Description
Details
| Status | Subtype | Assigned | Task | ||
|---|---|---|---|---|---|
| Resolved | • Kormat | T284825 Productionize pc2011-pc2014 and pc1011-pc1014 | |||
| Resolved | Jclark-ctr | T282484 (Need By: TBD) rack/setup/install pc1011-pc1014 | |||
| Resolved | Papaul | T282482 (Need By: TBD) rack/setup/install pc2011-pc2014 |
Event Timeline
For the record, I did assign them a partman recipe in order to get them installed with the proper one partitioning scheme.
I haven't added them to site.pp or anywhere else.
Change 699424 had a related patch set uploaded (by Marostegui; author: Marostegui):
[operations/puppet@production] site.pp: Add new parsercache hosts as insetup
Change 699424 merged by Marostegui:
[operations/puppet@production] site.pp: Add new parsercache hosts as insetup
codfw hosts are now ready to be productionized as the racking and installing task in codfw is done (T282482)
Reminder: set this hosts into Active mode in netbox.
Change 699580 had a related patch set uploaded (by Marostegui; author: Marostegui):
[operations/puppet@production] pc201[1-4]: Disable notifications
Change 699580 merged by Marostegui:
[operations/puppet@production] pc201[1-4]: Disable notifications
Just ran lvextend -L+1100G /dev/mapper/tank-data && sudo xfs_growfs /srv on all the codfw hosts.
===== NODE GROUP ===== (4) pc[2011-2014].codfw.wmnet ----- OUTPUT of 'df -hT /srv;' ----- Filesystem Type Size Used Avail Use% Mounted on /dev/mapper/tank-data xfs 8.7T 9.3G 8.7T 1% /srv ================
Change 706335 had a related patch set uploaded (by Kormat; author: Kormat):
[operations/puppet@production] pc201[1-4]: Add to mariadb::parsercache role
Change 706335 merged by Kormat:
[operations/puppet@production] pc201[1-4]: Add to mariadb::parsercache role
Change 706436 had a related patch set uploaded (by Kormat; author: Kormat):
[operations/puppet@production] pc201[1-4]: Enable notifications.
Change 706436 merged by Kormat:
[operations/puppet@production] pc201[1-4]: Enable notifications.
The new pc hosts in codfw are now in service. They're replicating from a blank start, so it will take 3 weeks for them to be populated fully. Once that's done, we can make one or more primary to see how that affects performance.
/srv resized on all eqiad hosts:
(4) pc[1011-1014].eqiad.wmnet ----- OUTPUT of 'df -hT /srv' ----- Filesystem Type Size Used Avail Use% Mounted on /dev/mapper/tank-data xfs 8.7T 9.3G 8.7T 1% /srv
Change 706475 had a related patch set uploaded (by Kormat; author: Kormat):
[operations/puppet@production] pc101[1-4]: Add to parsercache role and sections.
Change 706475 merged by Kormat:
[operations/puppet@production] pc101[1-4]: Add to parsercache role and sections.
Change 706507 had a related patch set uploaded (by Kormat; author: Kormat):
[operations/puppet@production] pc101[1-4]: Enable notifications.
Change 706507 merged by Kormat:
[operations/puppet@production] pc101[1-4]: Enable notifications.
All hosts are now in service. Including:
- sys schema deployed
- set to 'active' in netbox
Change 712115 had a related patch set uploaded (by Kormat; author: Kormat):
[operations/mediawiki-config@master] ProductionServices: Add new pc hosts.
Change 712115 merged by jenkins-bot:
[operations/mediawiki-config@master] ProductionServices: Add new pc hosts.
Change 712120 had a related patch set uploaded (by Kormat; author: Kormat):
[operations/mediawiki-config@master] ProductionServices: Promote pc2011 to primary of pc1.
Change 712120 merged by jenkins-bot:
[operations/mediawiki-config@master] ProductionServices: Promote pc2011 to primary of pc1.
Mentioned in SAL (#wikimedia-operations) [2021-08-12T09:27:12Z] <kormat@deploy1002> Synchronized wmf-config/ProductionServices.php: Promote pc2011 to primary of pc1 T284825 (duration: 01m 10s)
Mentioned in SAL (#wikimedia-operations) [2021-08-12T09:28:52Z] <kormat> reconfiguring replication tree for pc1 T284825
Mentioned in SAL (#wikimedia-operations) [2021-08-12T09:30:37Z] <kormat@cumin1001> START - Cookbook sre.hosts.downtime for 1:00:00 on 8 hosts with reason: Reconfiguring replication tree T284825
Mentioned in SAL (#wikimedia-operations) [2021-08-12T09:30:44Z] <kormat@cumin1001> END (PASS) - Cookbook sre.hosts.downtime (exit_code=0) for 1:00:00 on 8 hosts with reason: Reconfiguring replication tree T284825
Steps to update replication tree after making pc2011 primary:
- downtime all of pc1, as we have circular replication in place with eqiad
- move other pc1/codfw nodes beneath pc2011:
- db-move-replica pc2010 pc2011
- db-move-replica pc2014 pc2011
- reset replication for all affected nodes:
- mysql.py -h pc1007 -e 'stop slave; reset slave all'
- mysql.py -h pc2007 -e 'stop slave; reset slave all'
- mysql.py -h pc2011 -e 'stop slave; reset slave all'
- re-setup replication for the remaining nodes using binlog coords:
- mysql.py -h pc1007 -e "change master to master_node='pc2011..."
- mysql.py -h pc2007 -e "change master to master_node='pc2011..."
- mysql.py -h pc2011 -e "change master to master_node='pc1007..."
- reenable gtid everywhere
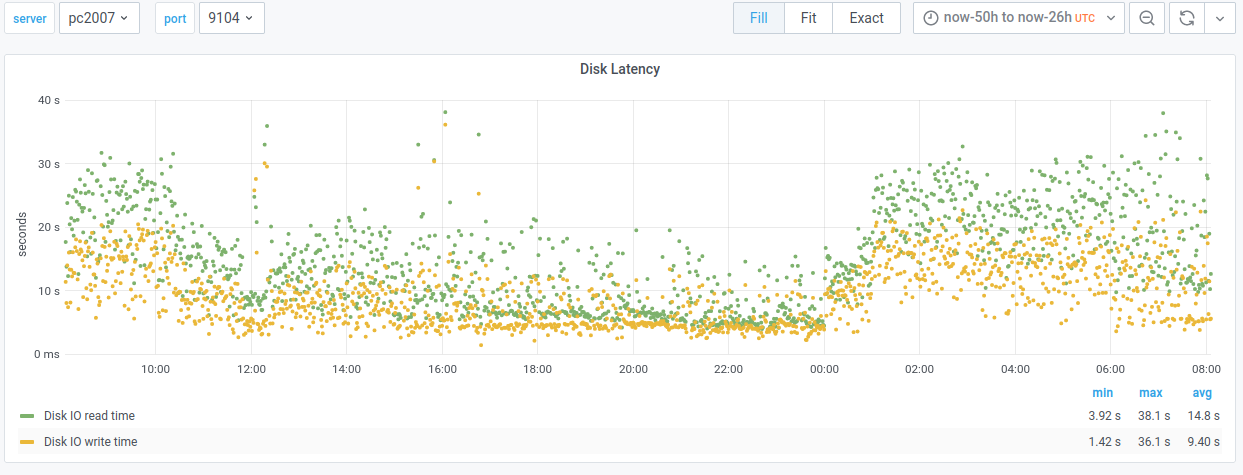
Current state: After running for a day, the graphs for the new node (db2011) are looking very promising. In particular, disk latency is massively improved.
Old primary:
Read latencies: 3.92s to 38.1s. Avg: 14.8s
Write latencies: 1.42s to 36.1s. Avg: 9.4s
New primary:
Read latencies: 172ms to 445ms. Avg: 260ms
Write latencies: 623ms to 3.63s. Avg: 1.39s
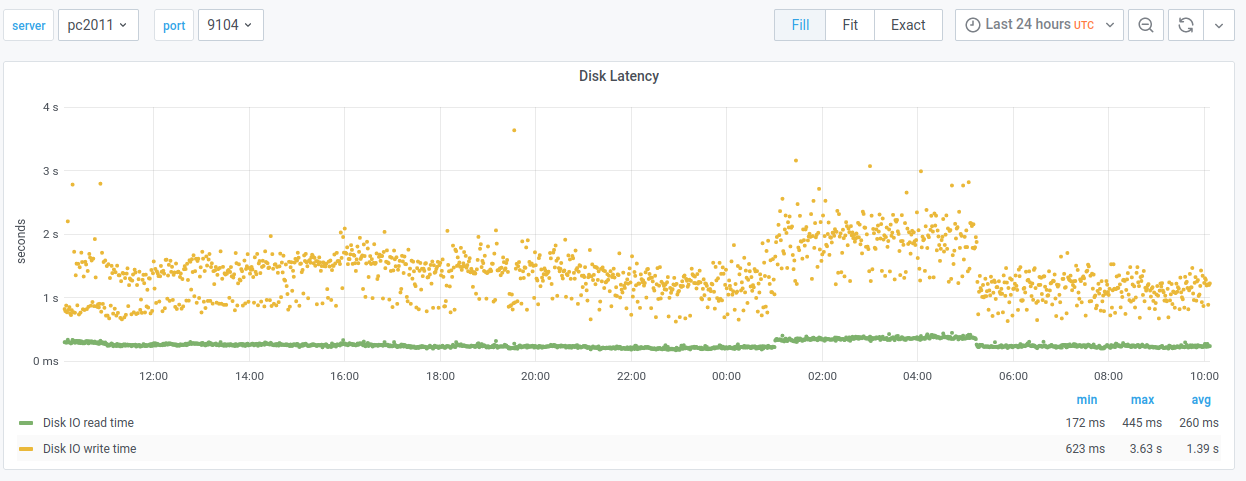
This makes sense, but it's still good to see :)
Change 713466 had a related patch set uploaded (by Kormat; author: Kormat):
[operations/mediawiki-config@master] ProductionServices: Promote pc2012 to primary of pc2.
Change 713471 had a related patch set uploaded (by Kormat; author: Kormat):
[operations/mediawiki-config@master] ProductionServices: Promote pc2013 to primary of pc3.
Change 713466 merged by jenkins-bot:
[operations/mediawiki-config@master] ProductionServices: Promote pc2012 to primary of pc2.
Mentioned in SAL (#wikimedia-operations) [2021-08-17T14:20:38Z] <kormat@deploy1002> Synchronized wmf-config/ProductionServices.php: Promote pc2012 to primary of pc2 T284825 (duration: 00m 59s)
Change 713471 merged by jenkins-bot:
[operations/mediawiki-config@master] ProductionServices: Promote pc2013 to primary of pc3.
Mentioned in SAL (#wikimedia-operations) [2021-08-17T14:37:58Z] <kormat@deploy1002> Synchronized wmf-config/ProductionServices.php: Promote pc2013 to primary of pc3 T284825 (duration: 00m 58s)
Change 713845 had a related patch set uploaded (by Kormat; author: Kormat):
[operations/mediawiki-config@master] ProductionServices: Promote pc1011 to primary of pc1.
Change 713866 had a related patch set uploaded (by Kormat; author: Kormat):
[operations/mediawiki-config@master] ProductionServices: Promote pc1012 to primary of pc2.
Change 713867 had a related patch set uploaded (by Kormat; author: Kormat):
[operations/mediawiki-config@master] ProductionServices: Promote pc2013 to primary of pc3.
Change 713845 merged by jenkins-bot:
[operations/mediawiki-config@master] ProductionServices: Promote pc1011 to primary of pc1.
Change 713866 merged by jenkins-bot:
[operations/mediawiki-config@master] ProductionServices: Promote pc1012 to primary of pc2.
Change 713867 merged by jenkins-bot:
[operations/mediawiki-config@master] ProductionServices: Promote pc1013 to primary of pc3.
Mentioned in SAL (#wikimedia-operations) [2021-08-19T13:09:06Z] <kormat@deploy1002> Synchronized wmf-config/ProductionServices.php: Promote new h/w to primary of eqiad pc sections T284825 (duration: 01m 08s)
Mentioned in SAL (#wikimedia-operations) [2021-08-19T13:24:17Z] <kormat> reconfiguring replication tree on pc1 T284825
Mentioned in SAL (#wikimedia-operations) [2021-08-19T13:30:22Z] <kormat> reconfiguring replication tree on pc2 T284825
Mentioned in SAL (#wikimedia-operations) [2021-08-19T13:34:24Z] <kormat> reconfiguring replication tree on pc3 T284825
Change 716936 had a related patch set uploaded (by Marostegui; author: Marostegui):
[operations/dns@master] wmnet: Update pcX-master
Mentioned in SAL (#wikimedia-operations) [2021-09-07T12:51:42Z] <mvernon@deploy1002> Synchronized wmf-config/ProductionServices.php: Remove old decommissioned pc hosts T284825 (duration: 01m 02s)
Change 729935 had a related patch set uploaded (by Kormat; author: Kormat):
[operations/puppet@production] mariadb: Set mysql_role for primary pc hosts.
Change 729935 merged by Kormat:
[operations/puppet@production] mariadb: Set mysql_role for primary pc hosts.