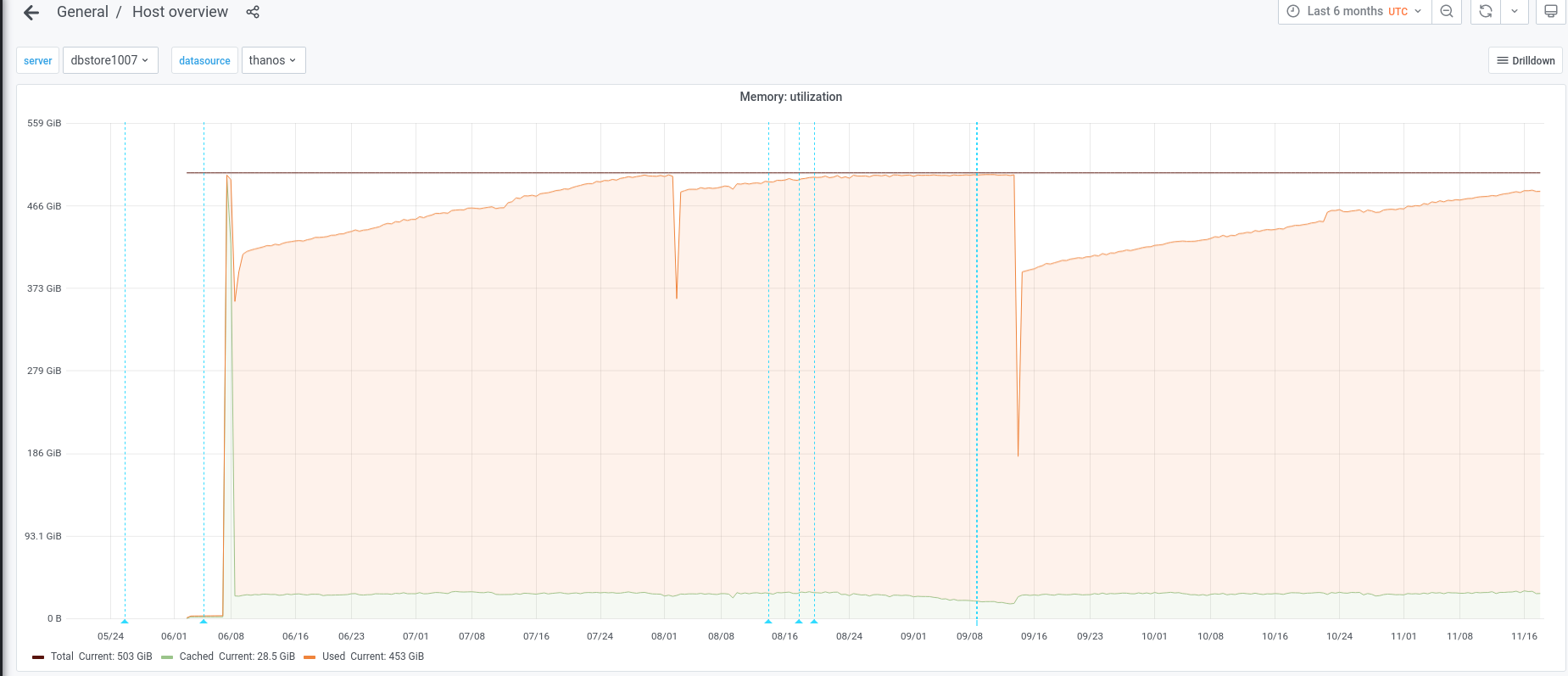
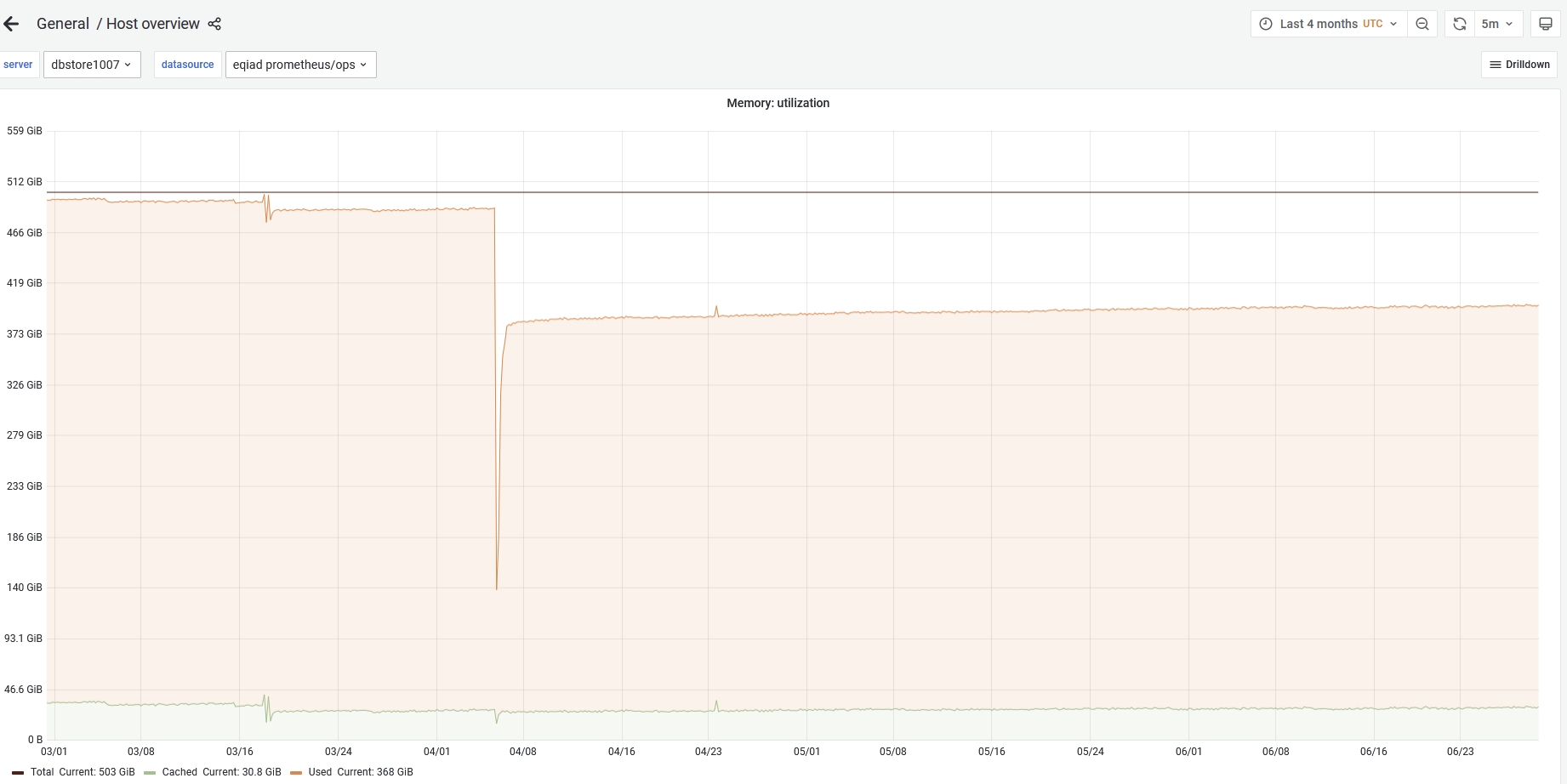
dbstore1007 is using 96% of its total memory: https://grafana.wikimedia.org/d/000000377/host-overview?viewPanel=4&orgId=1&var-server=dbstore1007&var-datasource=thanos&var-cluster=misc&from=1623138837938&to=1631516764499
It is frequently swapping:
https://grafana.wikimedia.org/d/000000377/host-overview?viewPanel=18&orgId=1&var-server=dbstore1007&var-datasource=thanos&var-cluster=misc&from=1623740593737&to=1631516593737&refresh=30s
which not only makes it run with lower performance, it also has the danger of the OOM killer activating and killing a mysql daemon.
I recommend to research a possible memory leak on those servers and/or restart some to prevent the killing.