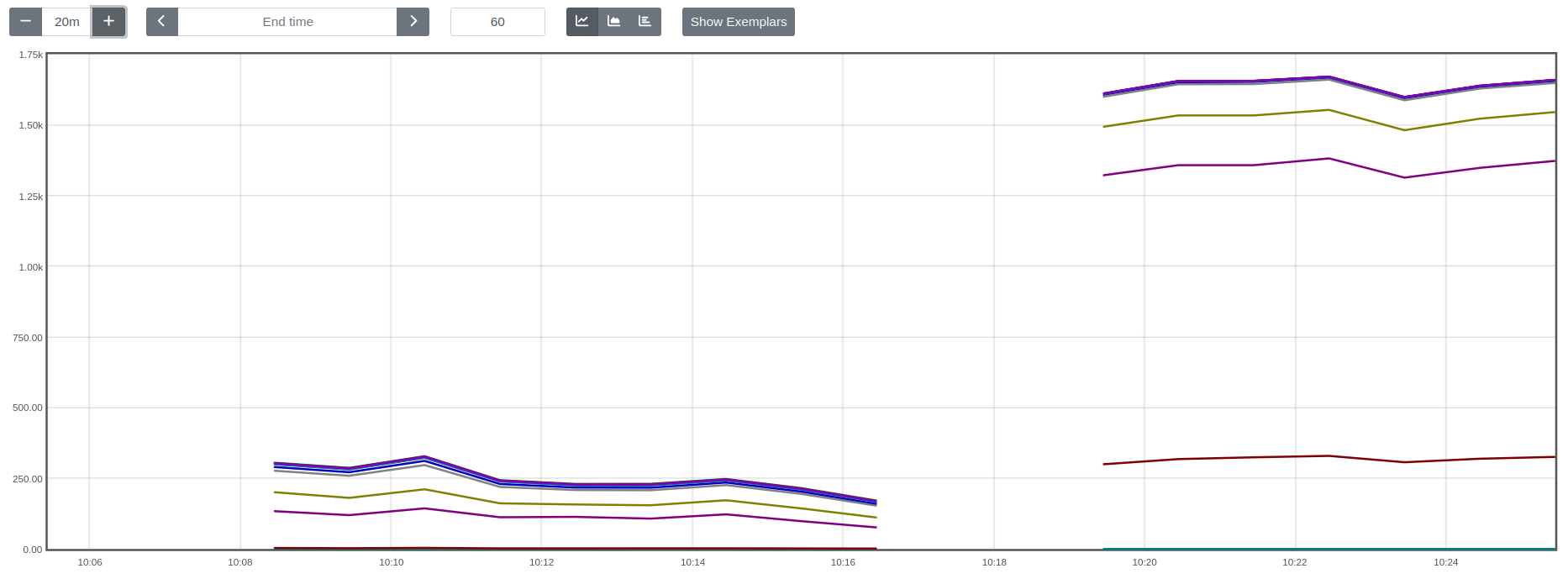
Problem: HTML dump scraper thoroughput drops off quickly after time.
Hypothesis 1: some threads fail to halt
Evidence for: Performance degrades but never recovers. Secondary process count decreases over a long timeframe at the end of the job, as if each thread is shutting down one at a time.
Test: Kill worker threads after a maximum time limit. Log skipped pages.
Hypothesis 2: exponential ref comparisons explode
Evidence against:
- the highest number of references is found in an article https://de.wikipedia.org/wiki/Liste_von_neuzeitlich_ausgestorbenen_Weichtieren , with 832kB of wikitext and 5300 refs. I synthesized a dump file with just the existing (four!) copies of this article which appear in the real dump and ran processing, but the job allocated 75MB of memory, took 1m20s to finish and outputs looked fine.
- Articles which seem to cause the drop in performance aren't timing out.
Hypothesis 3: triggered by a specific article feature
Evidence for: The problem doesn't seem to appear until roughly the 1.6M'th article, and then quickly degrades with time. If you fast-forward the stream to this point, the problem appears immediately. This happens whether we fast-forward by skipping lines within the program (therefore running data through all of the tar / gunzip / line split stream transformers), or if we start with a prepared snippet of the input file.
Evidence against: Performance curves look the same even if the articles around the inflection point have been skipped.
Hypothesis 4: articles are sorted in order of increasing difficulty
Evidence for: Similar to H3, processing snippets later in the stream seem to reflect exactly the same performance profile as the corresponding rows in a full run.
Understanding the way dumps are ordered would be helpful.