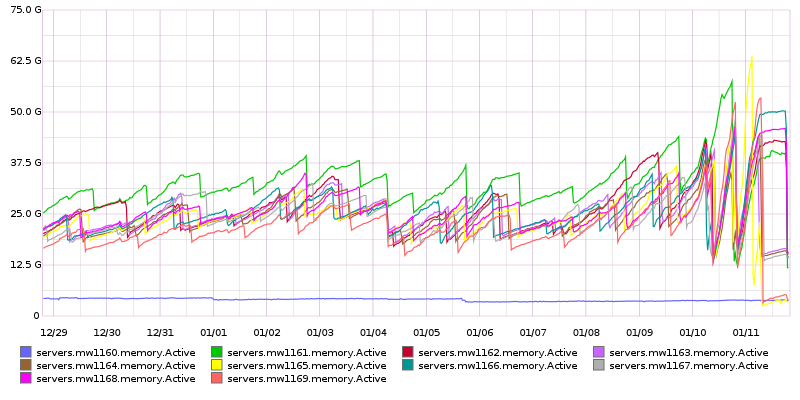
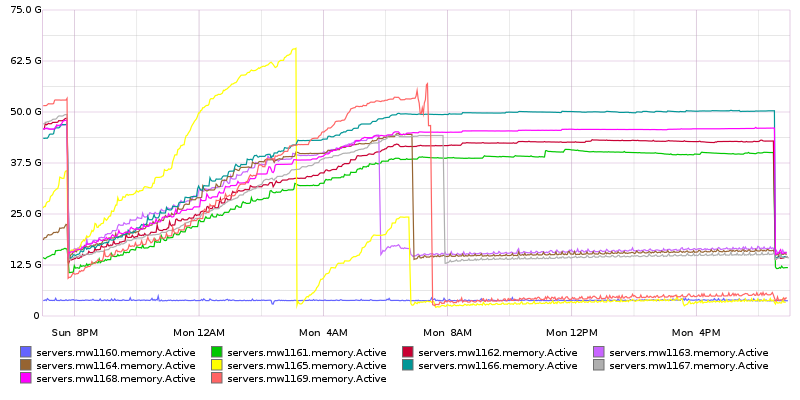
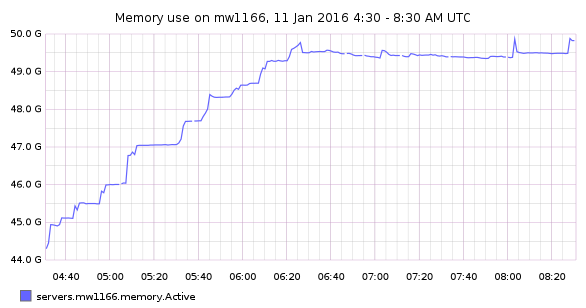
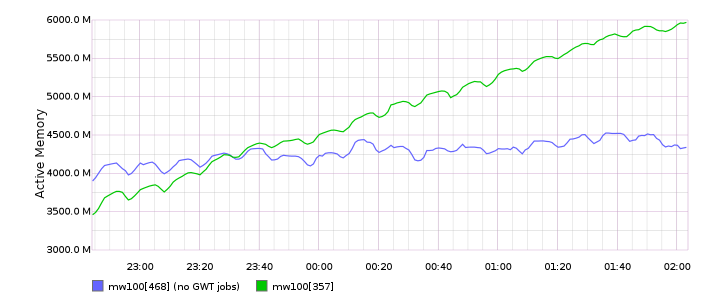
Since approximately Dec 15th there has been an increase in the rate jobrunners consume their memory. The effects appears to be cumulative, i.e. trending to exhaust all memory on the system and OOM (which has happened already on most of them). The memory levels of the jobrunners before used to be fairly steady, so this is new.
This seems to correlate with two changes happening that day:
- Make use of the per-server jobqueue:s-queuesWithJobs key (6483f1ad828b49070f4c86b1abb5b8b97105b1c2)
- Convert mw1162-1169 to job runners (ba0a47b56ded3dc748c436c2940f114389b312f2)
@ori has restarted mw1015 with jemalloc profiling and is collecting heap stats.
In the meantime, I restarted HHVM across the whole jobrunner fleet to avoid a fleet-wide OOM. Extrapolating from the current trend it appears that we'll get to the OOM threshold again (unless we restart again) in approximately 4 days.
Keyword: jobqueue, job queue