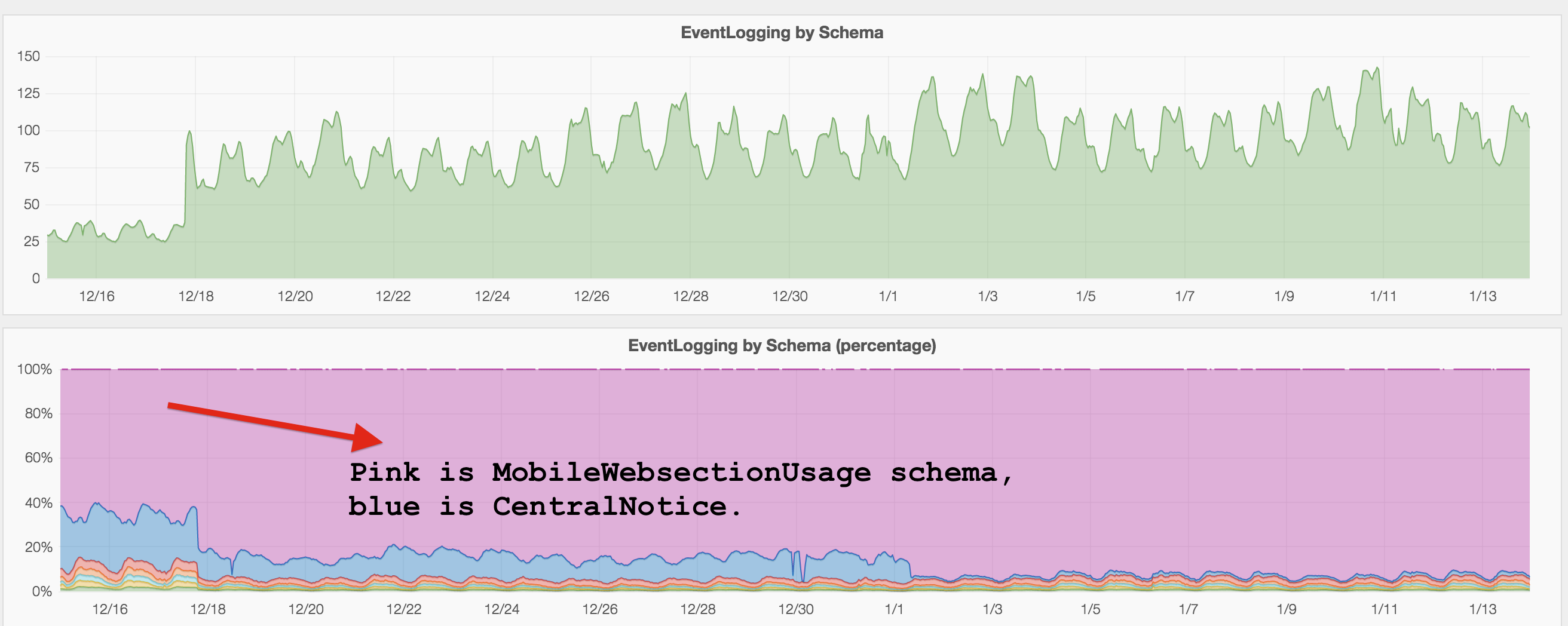
We have thus far seen that one schema was accounting for about 90% of eventlogging flow and we have blacklisted it: MobileWebSectionUsage (see image)
We have also dropped the MobileWebSectionUsage tables as the db was having disk space issues for a while (this was a just a shot in the dark though)
Looks like we have several long running queries we need to kill?