How can issues on a single server affect all the service? Is this server (db1040) a SPOF? If yes, why?
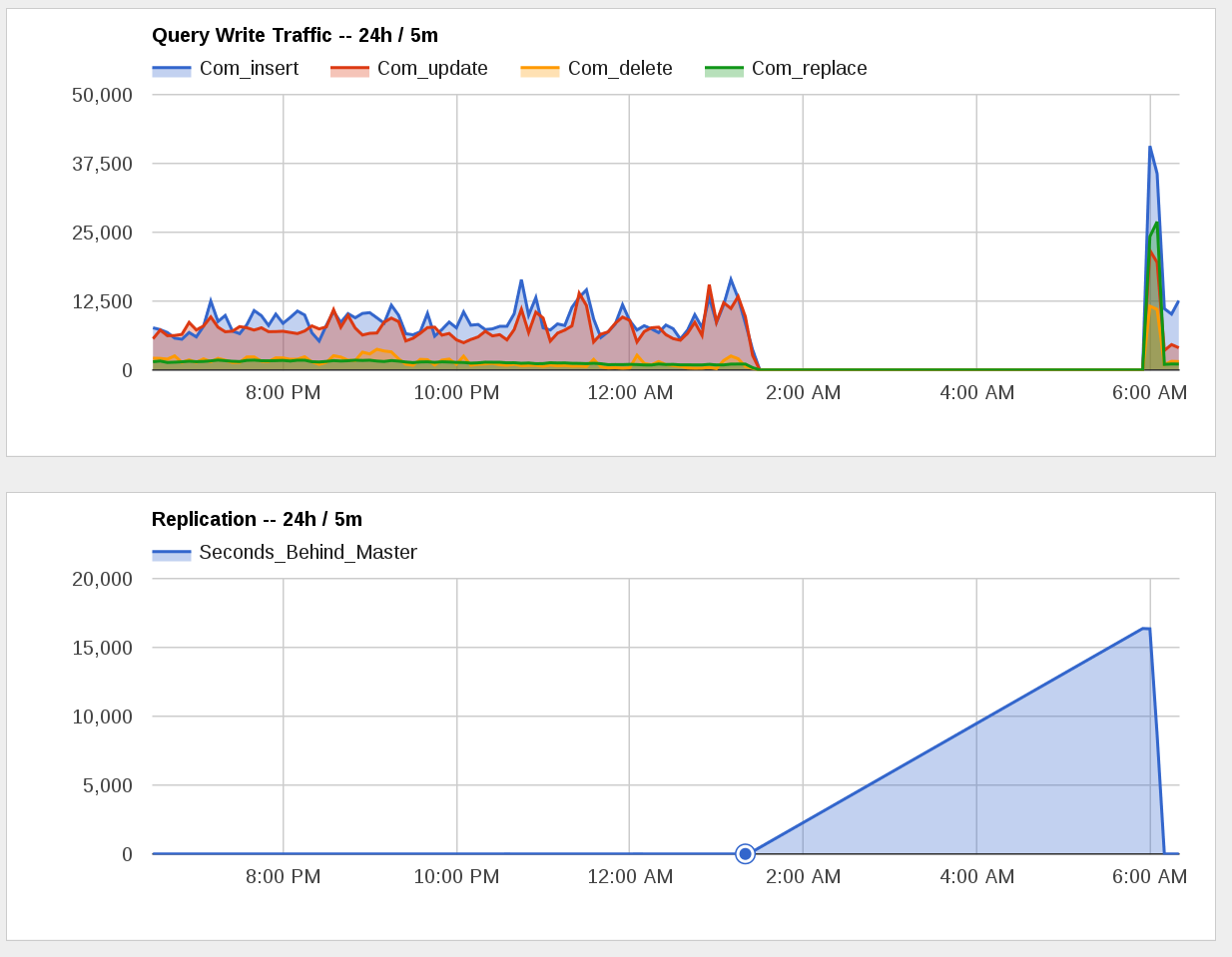
The server started lagging due to an ongoing schema change; however, that schema change, to avoid issues, only happens on a server at a time.
This is a 'vslow' slave, but that should have little user impact (except for statistics)- as far as I know, job queue is run on all slaves, and only this one was affected by lag.
https://graphite.wikimedia.org/render/?width=846&height=557&_salt=1463722181.272&from=-1hours&target=MediaWiki.jobqueue.acks.ThumbnailRender.rate
https://commons.wikimedia.org/wiki/Commons:Village_pump#The_October_2015_categorization_lag_is_back
https://grafana.wikimedia.org/dashboard/db/job-queue-health?panelId=12&fullscreen&from=1463684575201&to=1463726580442&var-jobType=all