The mobileapps services flapped four times so far on 7/01/2016 UTC.
[01:46:25] <icinga-wm> PROBLEM - mobileapps endpoints health on scb1001 is CRITICAL: CHECK_NRPE: Socket timeout after 10 seconds. [01:48:35] <icinga-wm> RECOVERY - mobileapps endpoints health on scb1001 is OK: All endpoints are healthy [04:15:26] <icinga-wm> PROBLEM - mobileapps endpoints health on scb1002 is CRITICAL: CHECK_NRPE: Socket timeout after 10 seconds. [04:17:36] <icinga-wm> RECOVERY - mobileapps endpoints health on scb1002 is OK: All endpoints are healthy [05:46:47] <icinga-wm> PROBLEM - mobileapps endpoints health on scb1001 is CRITICAL: CHECK_NRPE: Socket timeout after 10 seconds. [05:48:57] <icinga-wm> RECOVERY - mobileapps endpoints health on scb1001 is OK: All endpoints are healthy [16:07:05] <icinga-wm> PROBLEM - mobileapps endpoints health on scb1002 is CRITICAL: CHECK_NRPE: Socket timeout after 10 seconds. [16:09:24] <icinga-wm> RECOVERY - mobileapps endpoints health on scb1002 is OK: All endpoints are healthy
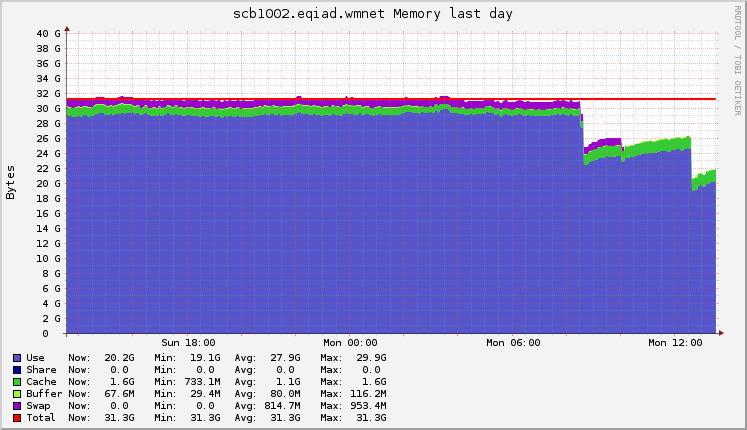
Checking Ganglia showed increased memory pressure. Looking at the yearly graph shows a steadily growing need for memory.[1][2] The long-term trend is very concerning.
I checked on scb1001 for the top memory using processes, and it looks like ORES is the most memory hungry, with each of the top processes consuming around 3-4% each.
$ ps aux | awk '{print $2, $4, $11, $15}' | sort -k2r | head -n 40 PID %MEM COMMAND 2844 4.0 /srv/deployment/ores/venv/bin/python3 ores_celery.application 2910 3.9 /usr/bin/uwsgi /etc/uwsgi/apps-enabled/ores.ini 2913 3.9 /usr/bin/uwsgi /etc/uwsgi/apps-enabled/ores.ini 2914 3.9 /usr/bin/uwsgi /etc/uwsgi/apps-enabled/ores.ini 2679 3.9 /srv/deployment/ores/venv/bin/python3 ores_celery.application 2692 3.9 /srv/deployment/ores/venv/bin/python3 ores_celery.application 2718 3.9 /srv/deployment/ores/venv/bin/python3 ores_celery.application 2736 3.9 /srv/deployment/ores/venv/bin/python3 ores_celery.application 2757 3.9 /srv/deployment/ores/venv/bin/python3 ores_celery.application 2781 3.9 /srv/deployment/ores/venv/bin/python3 ores_celery.application 2798 3.9 /srv/deployment/ores/venv/bin/python3 ores_celery.application 2804 3.9 /srv/deployment/ores/venv/bin/python3 ores_celery.application 2814 3.9 /srv/deployment/ores/venv/bin/python3 ores_celery.application 2832 3.9 /srv/deployment/ores/venv/bin/python3 ores_celery.application 2859 3.9 /srv/deployment/ores/venv/bin/python3 ores_celery.application 2872 3.9 /srv/deployment/ores/venv/bin/python3 ores_celery.application 2909 3.7 /usr/bin/uwsgi /etc/uwsgi/apps-enabled/ores.ini 2912 3.7 /usr/bin/uwsgi /etc/uwsgi/apps-enabled/ores.ini 2887 3.7 /srv/deployment/ores/venv/bin/python3 ores_celery.application 2894 3.7 /srv/deployment/ores/venv/bin/python3 ores_celery.application 2911 3.6 /usr/bin/uwsgi /etc/uwsgi/apps-enabled/ores.ini 2763 3.6 /srv/deployment/ores/venv/bin/python3 ores_celery.application 2905 3.5 /usr/bin/uwsgi /etc/uwsgi/apps-enabled/ores.ini 2904 3.4 /usr/bin/uwsgi /etc/uwsgi/apps-enabled/ores.ini 2906 3.4 /usr/bin/uwsgi /etc/uwsgi/apps-enabled/ores.ini 2907 3.4 /usr/bin/uwsgi /etc/uwsgi/apps-enabled/ores.ini 2908 3.4 /usr/bin/uwsgi /etc/uwsgi/apps-enabled/ores.ini 2898 3.2 /usr/bin/uwsgi /etc/uwsgi/apps-enabled/ores.ini 2903 3.2 /usr/bin/uwsgi /etc/uwsgi/apps-enabled/ores.ini 2125 3.2 /srv/deployment/ores/venv/bin/python3 ores_celery.application 2181 3.1 /usr/bin/uwsgi /etc/uwsgi/apps-enabled/ores.ini 2676 3.1 /usr/bin/uwsgi /etc/uwsgi/apps-enabled/ores.ini 2677 3.1 /usr/bin/uwsgi /etc/uwsgi/apps-enabled/ores.ini 2678 3.1 /usr/bin/uwsgi /etc/uwsgi/apps-enabled/ores.ini 2682 3.1 /usr/bin/uwsgi /etc/uwsgi/apps-enabled/ores.ini 2686 3.1 /usr/bin/uwsgi /etc/uwsgi/apps-enabled/ores.ini 2687 3.1 /usr/bin/uwsgi /etc/uwsgi/apps-enabled/ores.ini 2688 3.1 /usr/bin/uwsgi /etc/uwsgi/apps-enabled/ores.ini 2695 3.1 /usr/bin/uwsgi /etc/uwsgi/apps-enabled/ores.ini
[1] https://ganglia.wikimedia.org/latest/graph.php?r=year&z=xlarge&h=scb1001.eqiad.wmnet&m=cpu_report&s=by+name&mc=2&g=mem_report&c=Service+Cluster+B+eqiad
[2] https://ganglia.wikimedia.org/latest/graph.php?r=year&z=xlarge&h=scb1002.eqiad.wmnet&m=cpu_report&s=by+name&mc=2&g=mem_report&c=Service+Cluster+B+eqiad