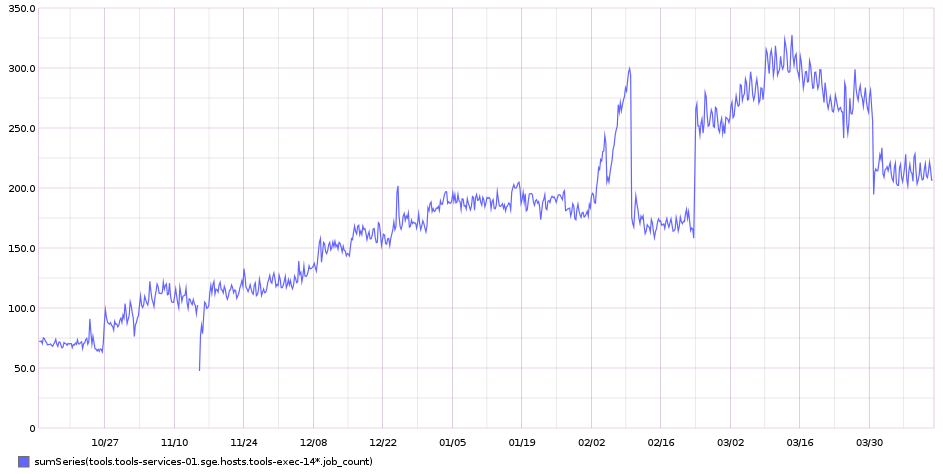
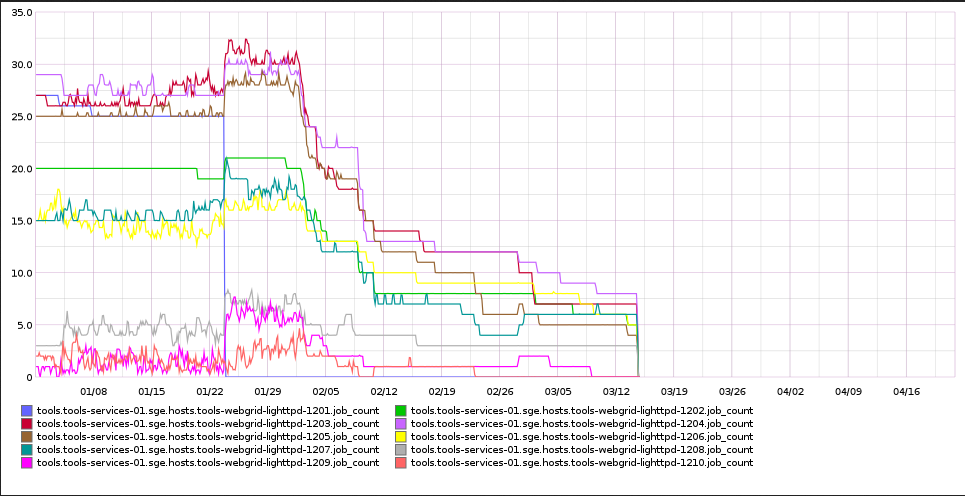
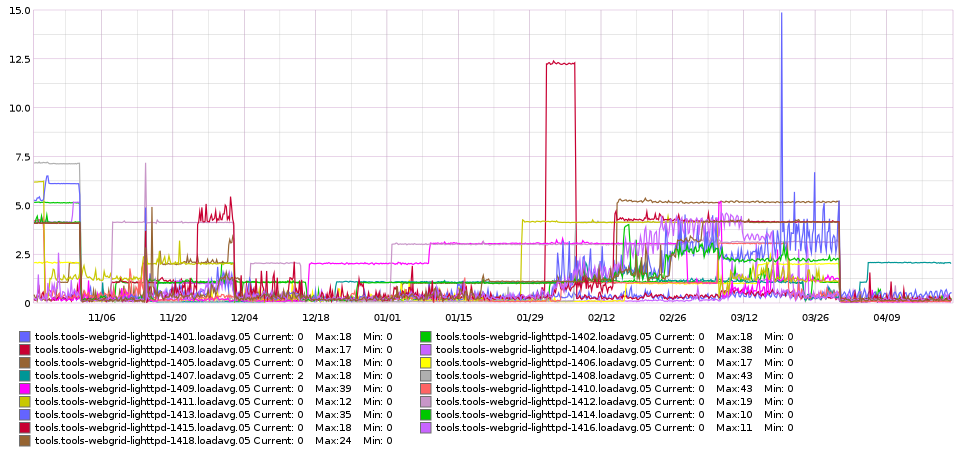
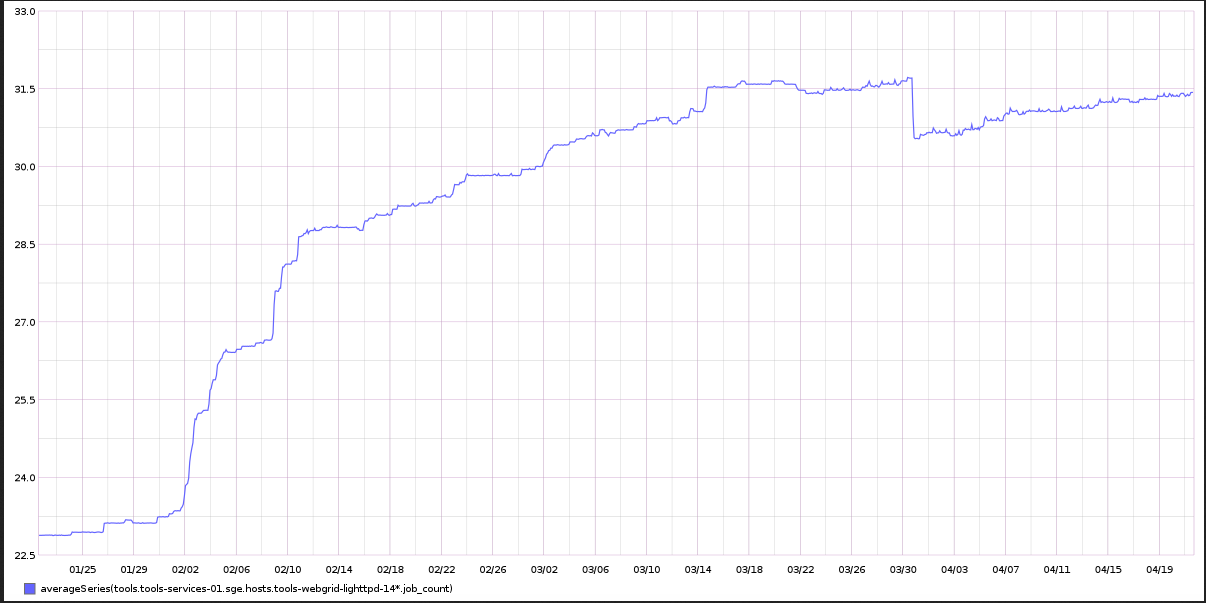
Shinken monitoring alerts for puppet errors on the tools instances have been flapping. Apparently there are legitimate reasons for some alerts but most have no obvious cause or impact. We still need puppet failure alerts due to it being an important proxy, but differentiating between a single instance/low percentage alert and general failures across all is essential to prioritize.
Original description:
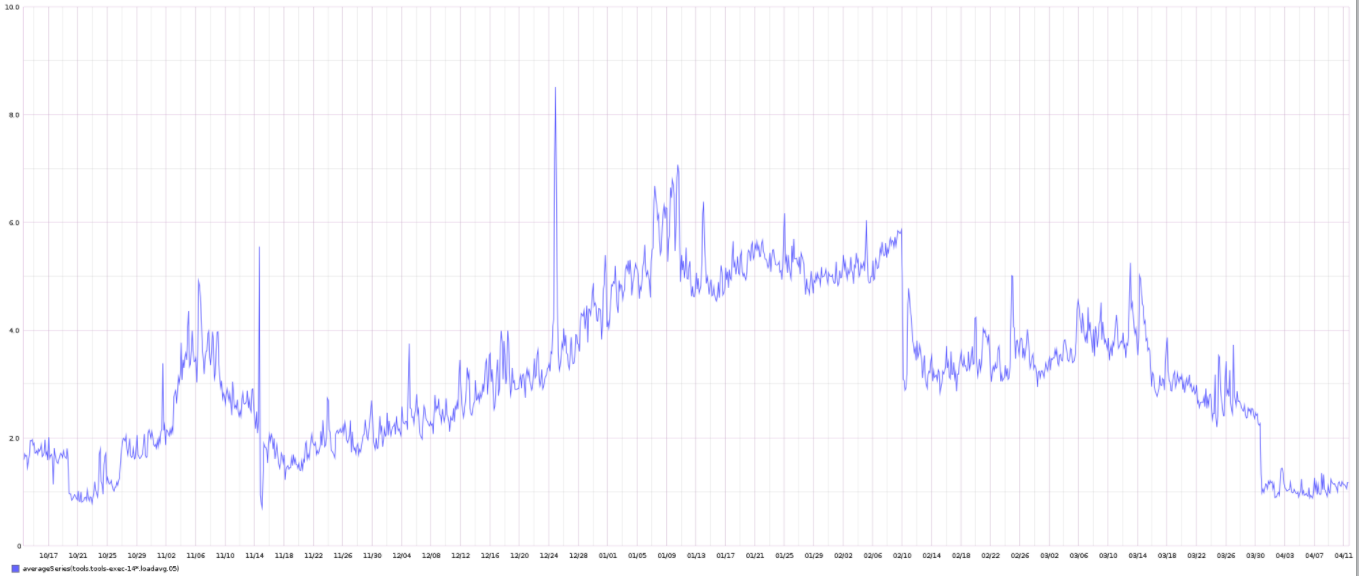
For the last month or so I've been seeing a smattering of shinken alerts like this:
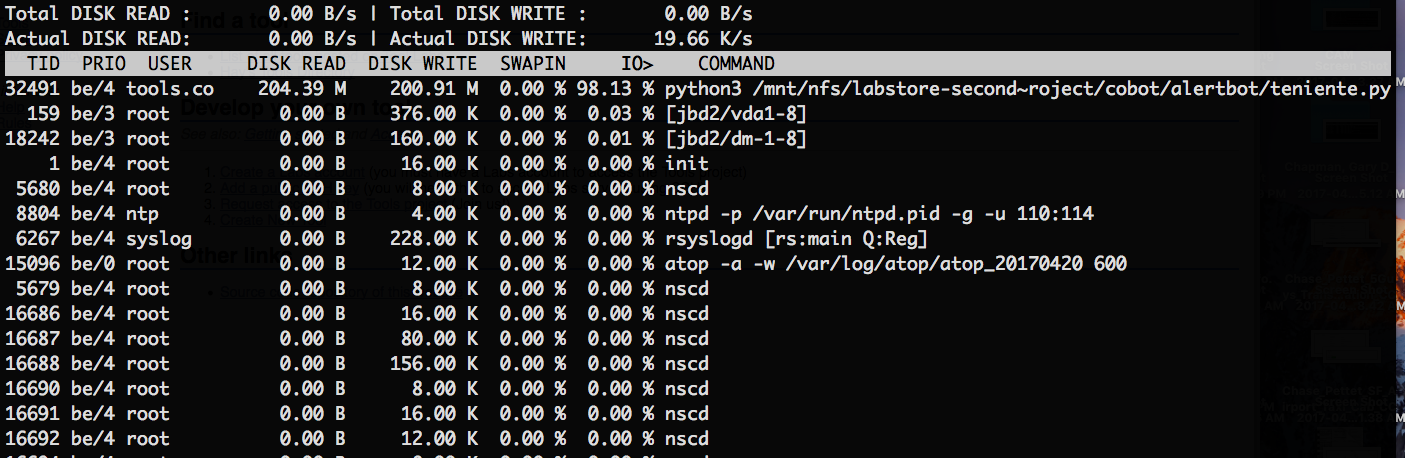
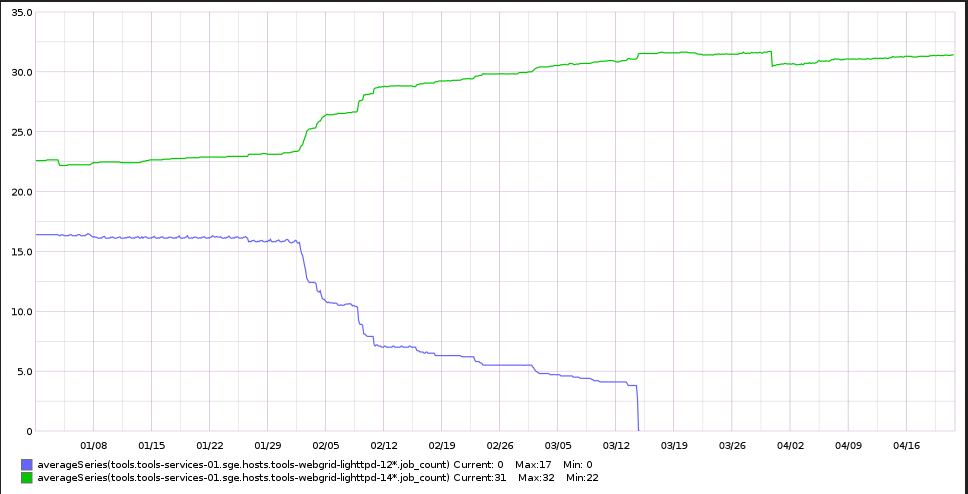
Notification Type: PROBLEM Service: High iowait Host: tools-exec-1408 Address: 10.68.18.14 State: WARNING Date/Time: Fri 31 Mar 12:52:06 UTC 2017 Additional Info: WARNING: tools.tools-exec-1408.cpu.total.iowait (>11.11%)I've also seen them for webgrid nodes. I'm not sure if this is because the labvirts themselves are overloaded or if we just need new exec nodes.