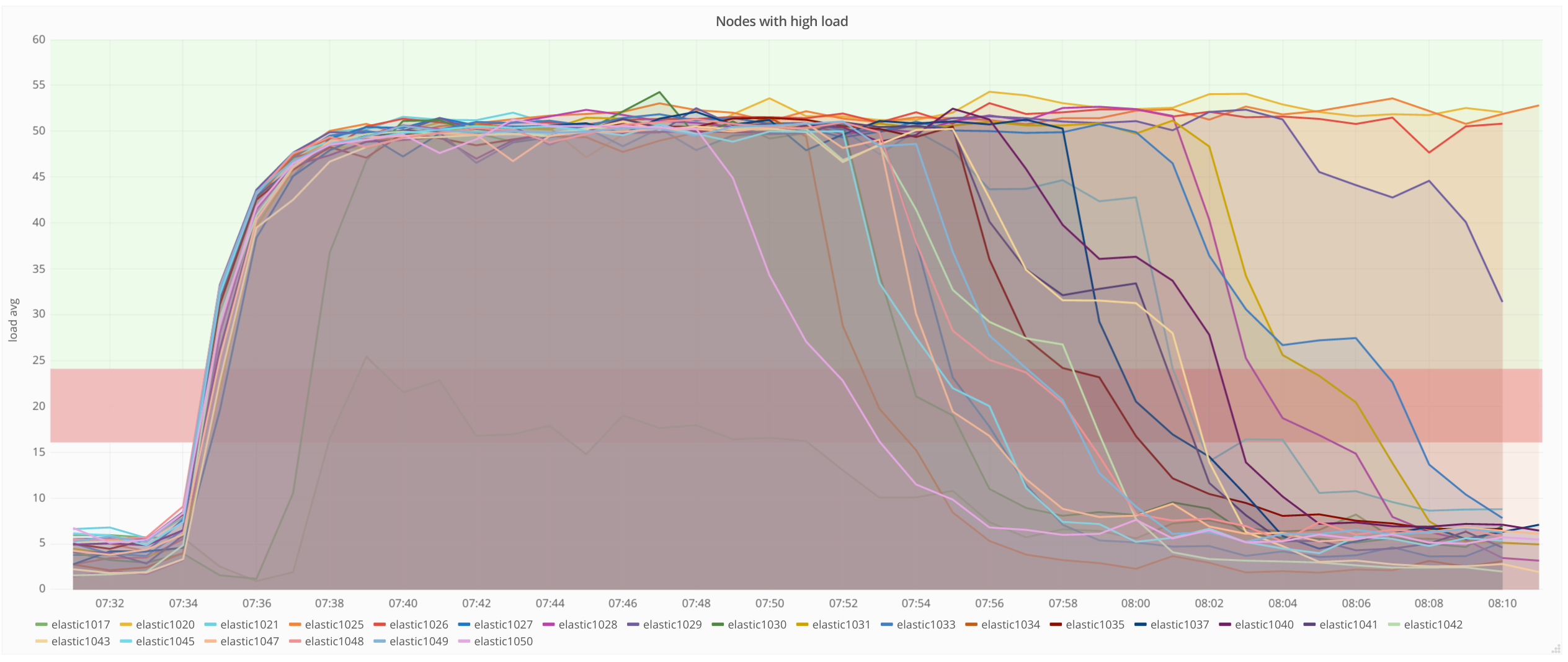
Since few days the cluster is showing performance issues causing a spike in percentiles.
It happened several times with only one node affected (e.g. with elastic1019 in yellow):
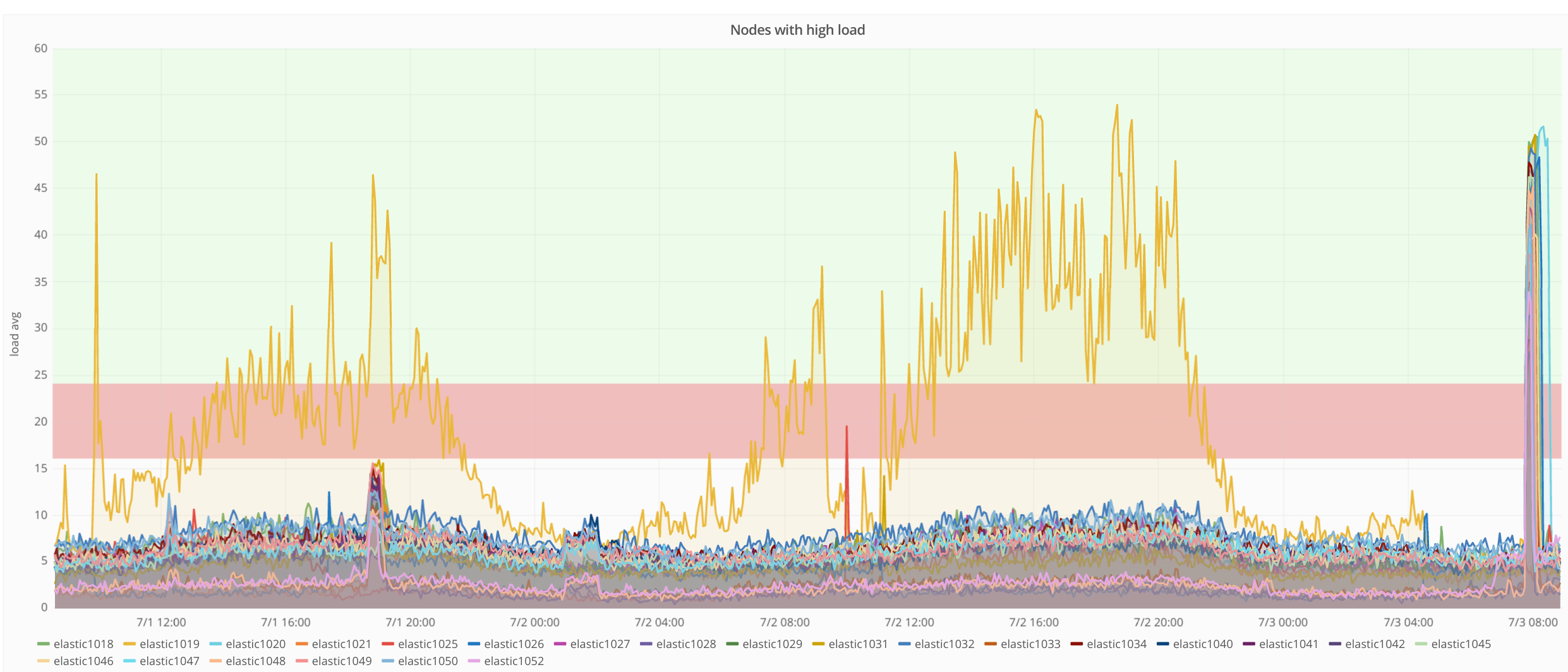
But this morning (jul 4 between 7:45 and 8:00 UTC) many nodes were affected:
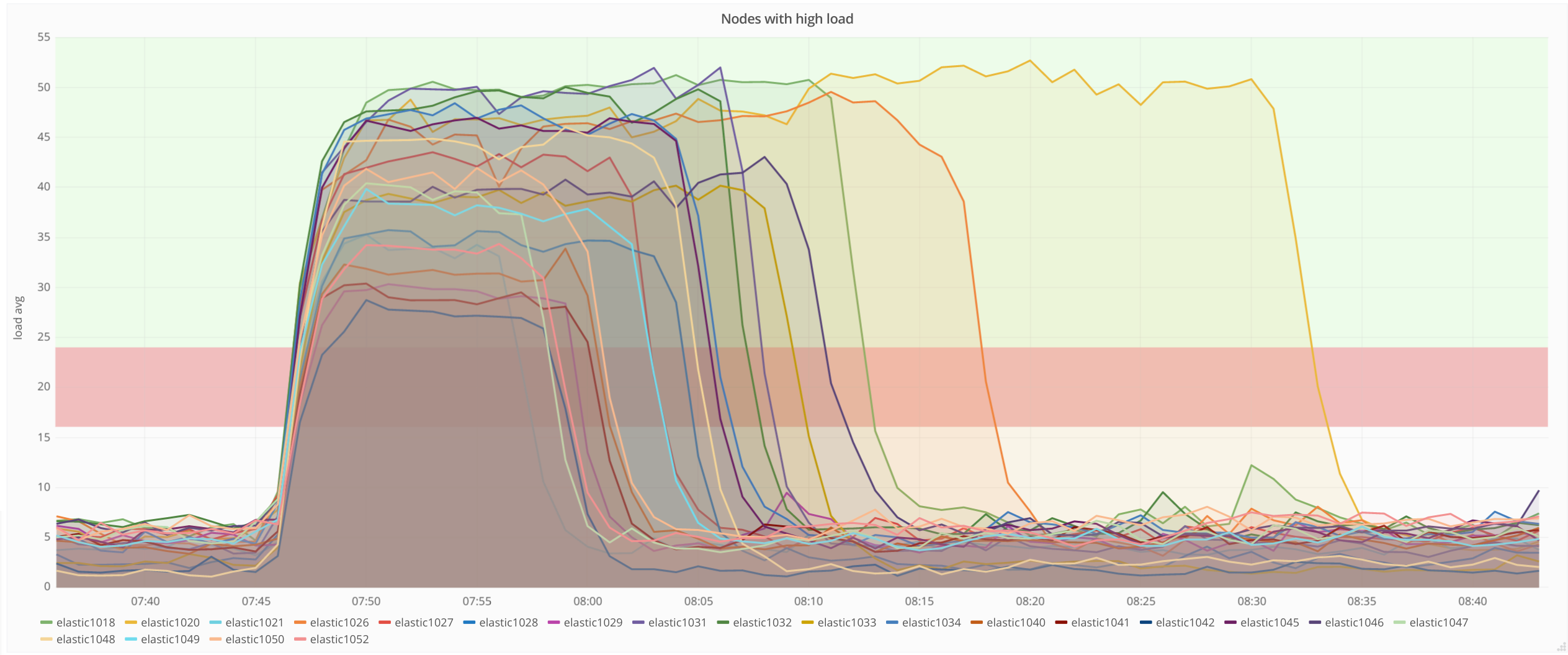
Possible causes to investigate:
- cluster not well balanced: when elastic1019 was misbehaving we noted that it served the most active shards (banning it seemed to have temporarily fixed the perf issues that tends to confirm the balance issues)
- bot: when multiple nodes are affected we can suspect a bot hammering the search apis with complex queries
- T152094: certainly caused much more queries to run the phrase rescore (costly)
- A slight increase in load avg (+~4%) after june 7 for unknown reasons