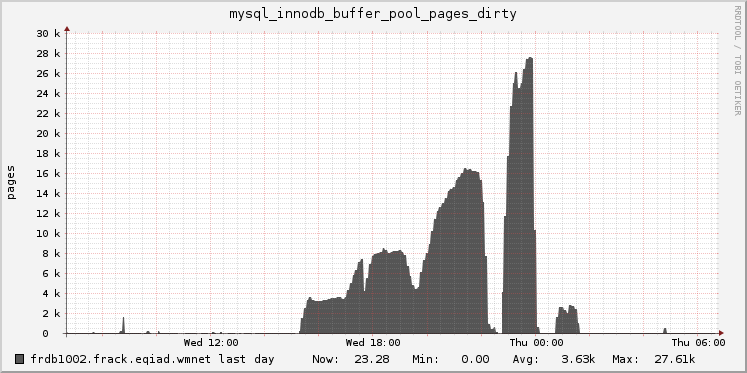
The fundraising DBs are displaying some erratic behavior around replication. Sometimes one or more slaves will fall behind and refuse to catch up. Neither flushing tables nor restarting slave threads has any effect but (so far) restarting the server daemon fixes it within minutes. Doing nothing for sufficient time also seems to work; today frdb1002 was lagging for over 8 hours after English banners were up for an hour. That box is also the read server so perhaps read locks made it worse.
Ganglia metrics make it look like something happened in late June that has had all the DB servers basically out of memory since then.
My best guess at this point is that single-threaded replication is simply not fast enough to keep up with the master under load. The only thing that doesn't explain is why restarting the daemon fixes it.
We might consider trying row-based replication, which should be faster, though I'm sure there are caveats.
I will keep investigating and post findings here.
Adding @Marostegui and @jcrespo because they were helping us poke at it.