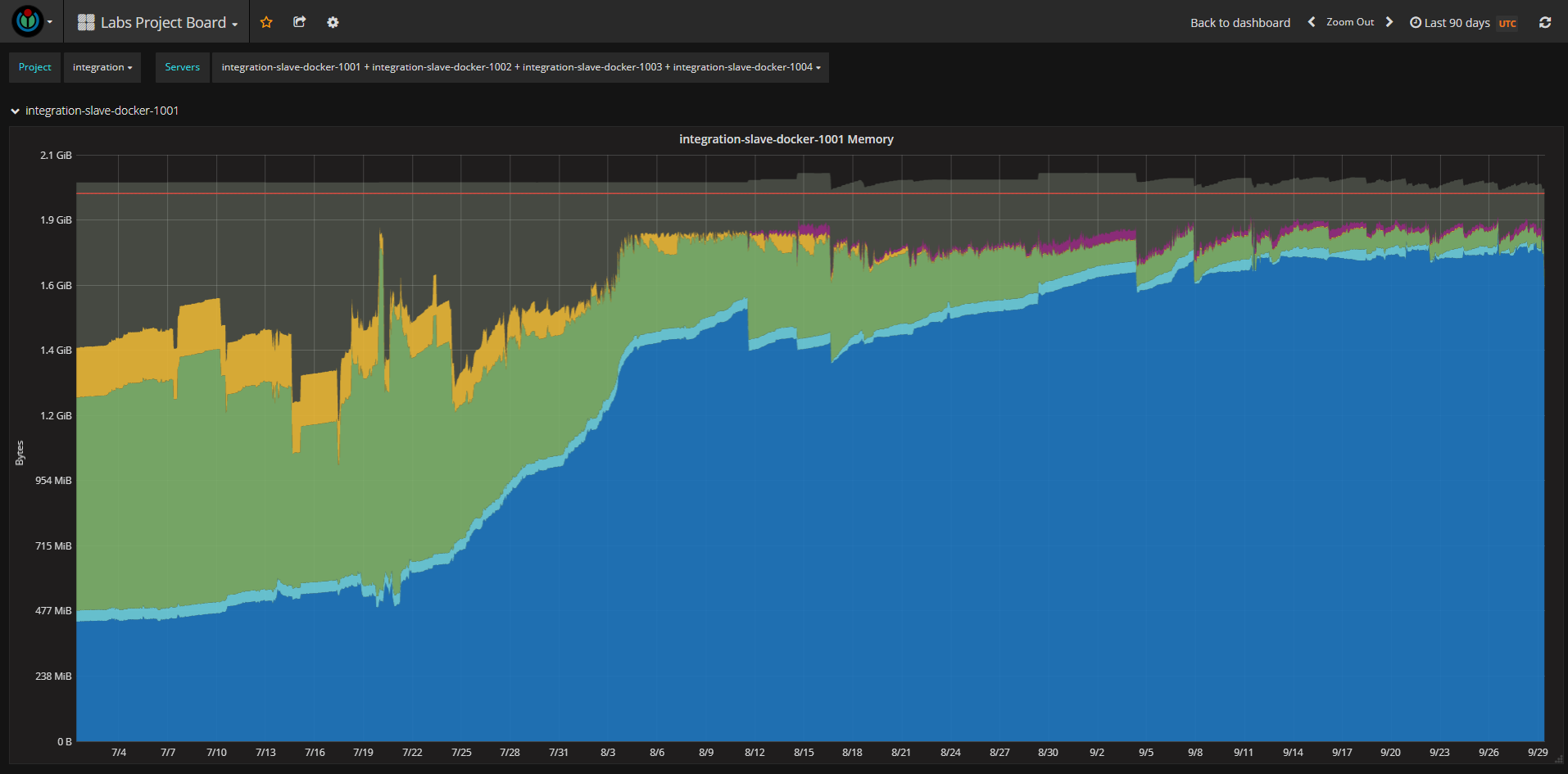
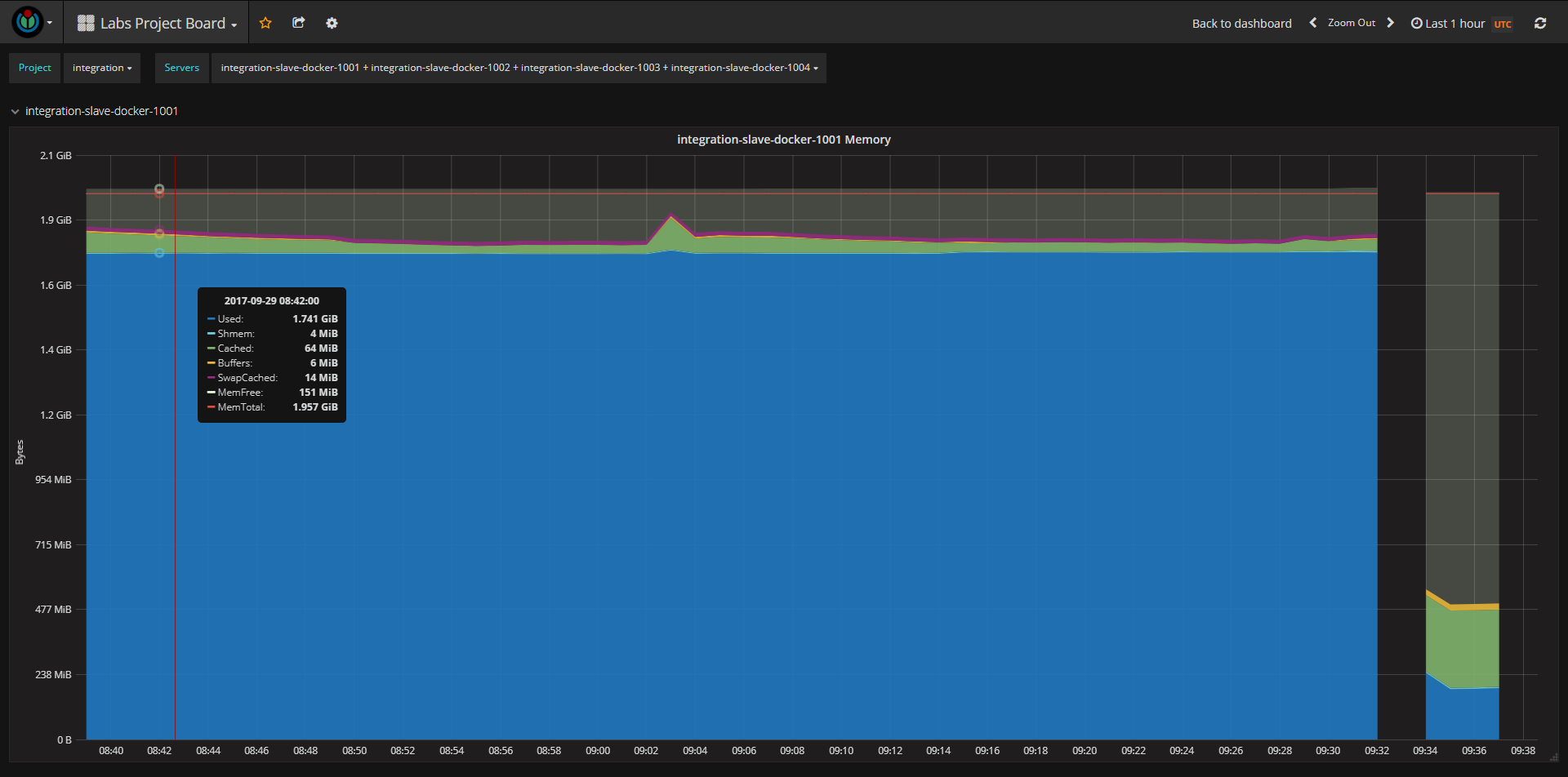
Looking at https://integration.wikimedia.org/ci/job/mediawiki-core-phpcs-docker/buildTimeTrend the jobs that have significantly higher build times were all run on integration-slave-docker-1001.
Looking at e.g.
- https://integration.wikimedia.org/ci/job/mediawiki-core-phpcs-docker/13/console
- https://integration.wikimedia.org/ci/job/mediawiki-core-phpcs-docker/26/console
- https://integration.wikimedia.org/ci/job/mediawiki-core-phpcs-docker/44/console
- https://integration.wikimedia.org/ci/job/mediawiki-core-phpcs-docker/45/console