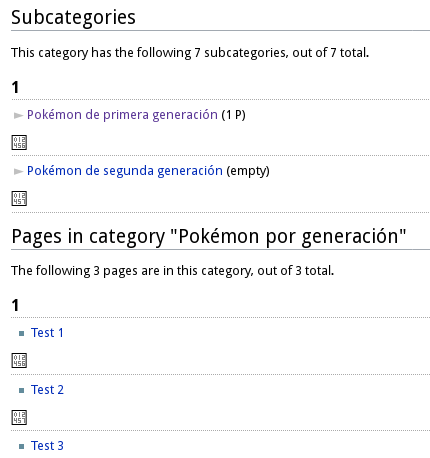
For some reason, when we have sortkeys with numbers in a category, the numbers 2 and 3 are printed as garbage characters in the category page.
See for example: https://www.wikidex.net/wiki/Categor%C3%ADa:Pok%C3%A9mon_por_generaci%C3%B3n
I'm able to reproduce it on a fresh installation with $wgCategoryCollation = 'uca-default';
To reproduce, create some pages and add each to the same category, with a number as the sortkey. For example (each line on a different page):
[[Category:Example|1]] [[Category:Example|2]] [[Category:Example|3]]
Now visit the Category:Example page and you'll see something like this:
Version: MediaWiki 1.30 (but it was also happening in MediaWiki 1.29)