Similar to T148506.
This is about row C only:
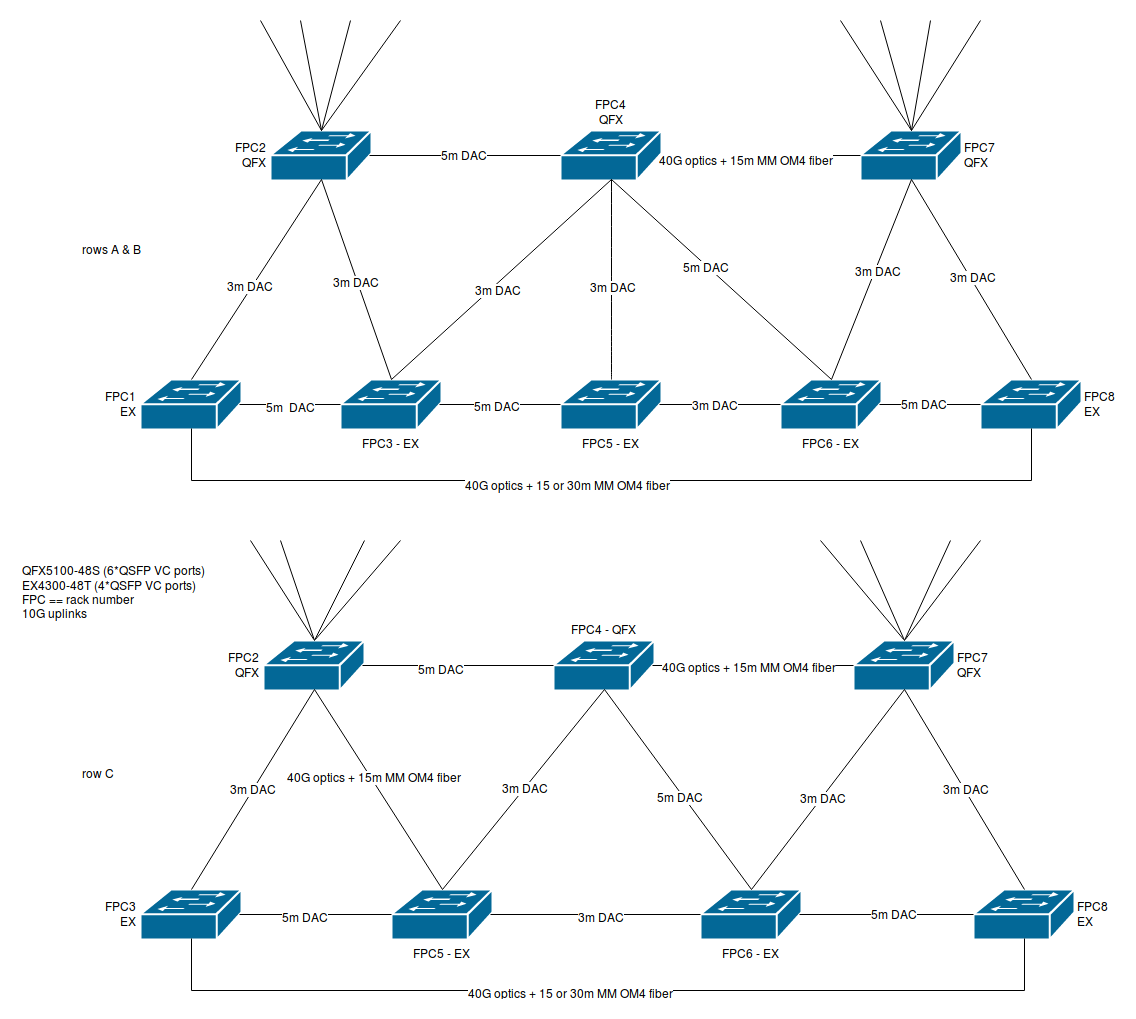
- Rack and cable the switches according to diagram (blocked on T187118) [Chris]
- Connect mgmt/serial [Chris]
- Check via serial that switches work, ports are configured as down [Arzhel]
- Stack the switch, upgrade JunOS, initial switch configuration [Arzhel]
- Add to DNS [Arzhel]
- Add to LibreNMS & Rancid [Arzhel]
- Uplinks ports configured [Arzhel]
- Add to Icinga [Arzhel]
Thursday 22nd, noon Eastern (4pm UTC) 3h (for all 3 rows)
- Disable interfaces from cr1-eqiad to asw-c
- Move cr1 router uplinks from asw-c to asw2-c (and document cable IDs if different) [Chris/Arzhel]
xe-2/0/44 -> cr1-eqiad:xe-3/0/2 xe-2/0/45 -> cr1-eqiad:xe-3/1/2 xe-7/0/44 -> cr1-eqiad:xe-4/0/2 xe-7/0/45 -> cr1-eqiad:xe-4/1/2
- Connect asw2-c with asw-c with 2x10G (and document cable IDs if different) [Chris]
xe-2/0/43 -> asw-c-eqiad:xe-1/1/0 xe-7/0/43 -> asw-c-eqiad:xe-7/0/0
- Verify traffic is properly flowing though asw2-c
- Update interfaces descriptions on cr1
___
- Switch ports configuration to match asw-c (+login announcement) [Arzhel]
- Solve snowflakes [Chris/Arzhel]
- Pre populate FPC2, FPC4 and FPC7 (QFX) with copper SFPs matching the current production servers on rack 2, 4 and 7 [Chris]
ge-2/0/2 kafka-jumbo1004 ge-2/0/3 db1108 ge-2/0/4 analytics1074 ge-2/0/6 labstore1004 eth0 ge-2/0/7 db1087 ge-2/0/8 db1088 ge-2/0/9 db1100 ge-2/0/10 analytics1065 - no-bw-mon ge-2/0/11 analytics1066 - no-bw-mon ge-2/0/12 db1101 ge-2/0/13 db1055 ge-2/0/15 labstore1001 ge-2/0/17 db1059 ge-2/0/18 db1060 ge-2/0/19 analytics1028 - no-bw-mon ge-2/0/20 analytics1029 - no-bw-mon ge-2/0/21 analytics1030 - no-bw-mon ge-2/0/22 analytics1031 - no-bw-mon ge-2/0/23 es1015 ge-2/0/24 es1016 ge-2/0/26 analtyics1064 ge-2/0/45 lvs1001:eth3 ge-2/0/46 lvs1002:eth3 ge-2/0/47 lvs1003:eth3 ge-4/0/0 eventlog1001 ge-4/0/1 mwlog1001 ge-4/0/2 logstash1002 ge-4/0/3 rdb1007 ge-4/0/4 hafnium ge-4/0/6 graphite1001 ge-4/0/8 neodymium ge-4/0/9 rdb1001 ge-4/0/13 ores1006 ge-4/0/16 analytics1001 - no-bw-mon ge-4/0/17 cobalt ge-4/0/18 analytics1003 - no-bw-mon ge-4/0/22 ganeti1001 ge-4/0/23 ganeti1002 ge-4/0/25 radon ge-4/0/26 labsdb1006 ge-4/0/27 labsdb1007 ge-4/0/28 restbase1012 ge-4/0/29 restbase1013 ge-4/0/30 snapshot1006 ge-4/0/31 deploy1001 ge-4/0/32 bast1002 ge-4/0/33 labsdb1010 ge-4/0/34 elastic1029 ge-4/0/36 elastic1022 ge-4/0/37 kafka-jumbo1005 ge-7/0/0 dbproxy1007 ge-7/0/1 analytics1014 - no-bw-mon ge-7/0/2 elastic1051 ge-7/0/3 dbproxy1008 ge-7/0/4 dbproxy1009 ge-7/0/5 analytics1075 ge-7/0/6 notebook1001 ge-7/0/7 ganeti1003 ge-7/0/8 ganeti1004 ge-7/0/9 ocg1001 ge-7/0/11 analytics1022 - no-bw-mon ge-7/0/14 conf1002 ge-7/0/15 notebook1004 ge-7/0/17 pc1005 ge-7/0/18 rdb1002 ge-7/0/22 terbium ge-7/0/26 labcontrol1002 ge-7/0/31 scb1003 ge-7/0/32 polonium ge-7/0/33 francium ge-7/0/34 lithium ge-7/0/35 elastic1052 ge-7/0/36 wtp1040 ge-7/0/37 wtp1041 ge-7/0/38 wtp1042
- Move 10G servers from C8 to C2/4/7 [Filippo/Chris/Arzhel]
ms-be1036 ms-be1035 ms-be1034 ms-be1025 ms-be1024 ms-fe1008 ms-fe1007
- "Regarding neodymium the only thing that needs to be done is to remember people to use sarin instead for long maintenance tasks"
- Depool aluminium and poolcounter1001 [akosiaris]
- Disable ping offload (ping1001) [Arzhel]
- Redirect ns0 to baham [Arzhel]
- Announce read-only time on-wiki to users of frwiki, ruwiki and jawiki with at least 1 week in advance - T194939 [Arzhel/Community-liaisons]
- Depool DB hosts [jcrespo]
In maintenance window Tuesday May 29th
- Downtime asw-c hosts in Icinga [Arzhel]
- Move servers' uplinks from asw-c to asw2-c, round 1 [Chris]
Leave behind: labs*, cp* es* db* analytics* kafka* ores* osm-web* rdb* graphite* mwlog* eventlog* ganeti* (see comment bellow above hosted VMs) restbase* snapshot* bast* deploy* elastic* wtp* kubernetes* mc* relforge* maps* aqs* druid* radon neodymium hafnium cobalt
- Verify all servers are healthy, monitoring happy
- Repool depooled servers
At a later date
- Move remaining servers [Chris]
lvs1001.wikimedia.org lvs1002.wikimedia.org labstore1005.eqiad.wmnet labstore1004.eqiad.wmnet labmon1001.eqiad.wmnet labcontrol1002.wikimedia.org labsdb1011.eqiad.wmnet labsdb1010.eqiad.wmnet labcontrol1001.wikimedia.org labstore1002.eqiad.wmnet labstore1001.eqiad.wmnet labsdb1005.eqiad.wmnet labsdb1004.eqiad.wmnet labsdb1007.eqiad.wmnet labsdb1006.eqiad.wmnet
Thursday 26nd, 5pm UTC 1h
- Failover VRRP master to cr1-eqiad and verify status + traffic shift [Arzhel]
On cr2: set interfaces ae3 unit 1003 family inet address 208.80.154.67/26 vrrp-group 3 priority 70 set interfaces ae3 unit 1019 family inet address 10.64.32.3/22 vrrp-group 19 priority 70 set interfaces ae3 unit 1022 family inet address 10.64.36.3/24 vrrp-group 22 priority 70 set interfaces ae3 unit 1119 family inet address 10.64.37.3/24 vrrp-group 119 priority 70 set interfaces ae3 unit 1003 family inet6 address 2620:0:861:3:fe00::2/64 vrrp-inet6-group 3 priority 70 set interfaces ae3 unit 1019 family inet6 address 2620:0:861:103:fe00::2/64 vrrp-inet6-group 19 priority 70 set interfaces ae3 unit 1022 family inet6 address 2620:0:861:106:fe00::2/64 vrrp-inet6-group 22 priority 70 set interfaces ae3 unit 1119 family inet6 address 2620:0:861:119:fe00::2/64 vrrp-inet6-group 119 priority 70 On cr1/2: show vrrp summary -> master/backup
- Disable cr2-eqiad:ae3 [Arzhel]
- Move cr2 router uplinks from asw-c to asw2-c (and document cable IDs if different) [Chris/Arzhel]
xe-2/0/46 -> cr2-eqiad:xe-3/0/2 xe-2/0/47 -> cr2-eqiad:xe-3/1/2 xe-7/0/46 -> cr2-eqiad:xe-4/0/2 xe-7/0/47 -> cr2-eqiad:xe-4/1/2
- Verify connectivity (eg. with cp1045)
- Enable cr2-eqiad:ae3 [Arzhel]
- Re-move VRRP master to cr2-eqiad [Arzhel]
- Update interfaces descriptions [Arzhel]
- Verify all servers are healthy, monitoring happy
After CP servers are decommed
- Verify no more traffic on asw-c<->asw2-c link [Arzhel]
- Disable asw-c<->asw2-c link [Arzhel]
- Cleanup config, monitoring, DNS, etc.
- Wipe & unrack asw-c