Similar to T148506.
This is about row B only:
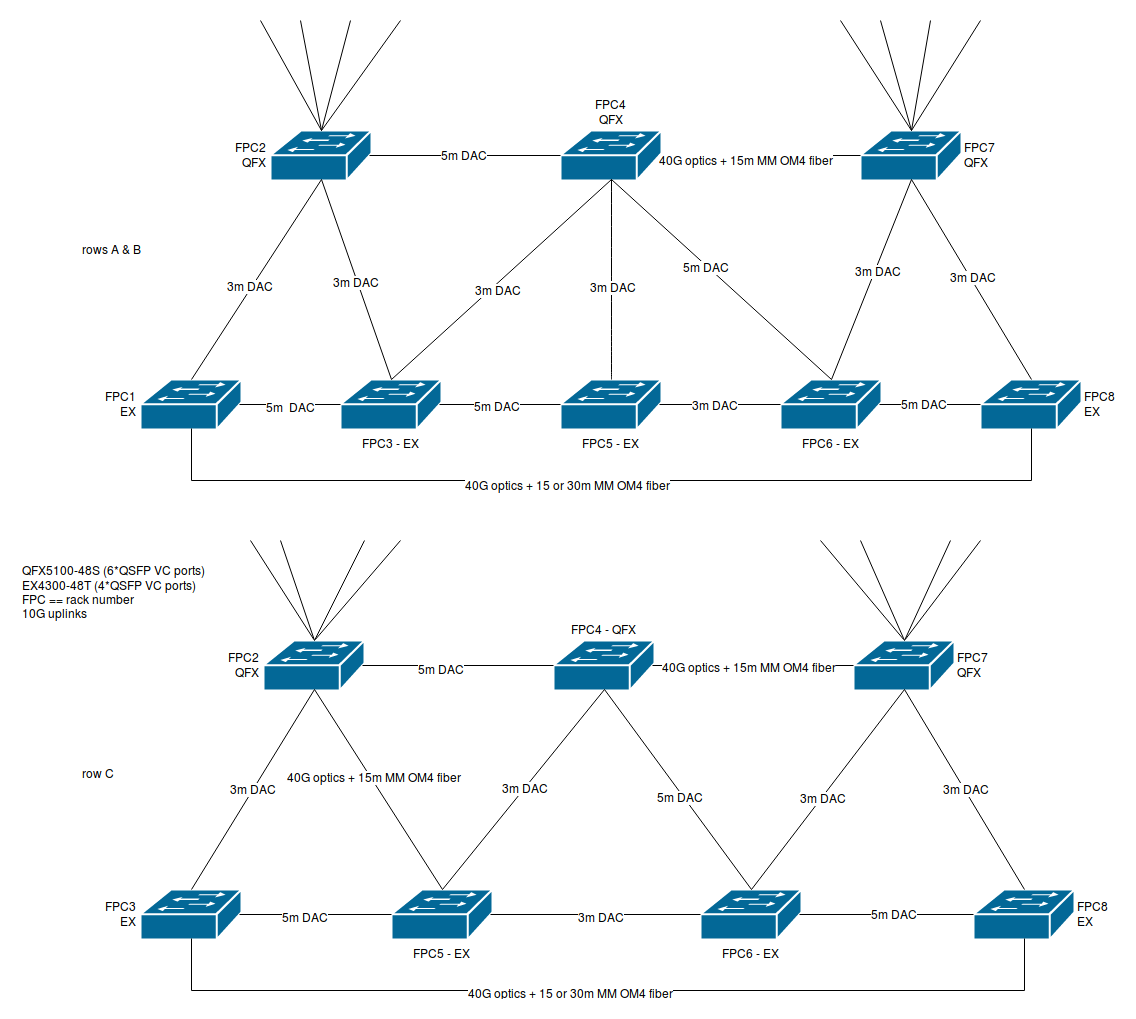
- Rack and cable the switches according to diagram (blocked on T187118) [Chris]
- Connect mgmt/serial [Chris]
- Check via serial that switches work, ports are configured as down [Arzhel]
- Stack the switch, upgrade JunOS, initial switch configuration [Arzhel]
- Add to DNS [Arzhel]
- Add to LibreNMS & Rancid [Arzhel]
- Switch ports configuration to match asw-b (+login announcement) [Arzhel]
- Solve snowflakes [Chris/Arzhel]
WAS xe-3/1/0 description "labnet1001 eth5" MOVED TO: xe-2/0/22 WAS xe-3/1/2 description "labnet1001 eth4" MOVED TO: xe-2/0/24 WAS ge-3/0/33 description "labnet1001 eth0" MOVED TO: ge-2/0/23 WAS xe-4/1/0 description "labnet1002 eth3" MOVED TO: xe-4/0/45 WAS xe-4/1/2 description "labnet1002 eth4" MOVED TO: xe-4/0/44
- Pre populate FPC2, FPC4 and FPC7 (QFX) with copper SFPs matching the current production servers on rack 2, 4 and 7 [Chris]
- Add to Icinga [Arzhel]
Thursday 22nd, noon Eastern (4pm UTC) 3h (for all 3 rows)
- Verify cr2-eqiad is VRRP master
- Disable interfaces from cr1-eqiad to asw-b
- Move cr1 router uplinks from asw-b to asw2-b (and document cable IDs if different) [Chris/Arzhel]
xe-2/0/44 -> cr1-eqiad:xe-3/0/1 xe-2/0/45 -> cr1-eqiad:xe-4/0/1 xe-7/0/44 -> cr1-eqiad:xe-4/1/1 xe-7/0/45 -> cr1-eqiad:xe-3/1/1
- Connect asw2-b with asw-b with 2x10G (and document cable IDs if different) [Chris]
xe-2/0/43 -> asw-b-eqiad:xe-2/1/0 xe-7/0/43 -> asw-b-eqiad:xe-7/1/0
- Verify traffic is properly flowing though asw2-b
- Update interfaces descriptions on cr1
Before maintenance
- Failover hosts
In maintenance window July 31st (3pm UTC, 11am EDT, 8am PDT), 4h.
- Move servers from asw-b to asw2-b (1st batch) [Chris]
(full list in T183585#4466638)
- TBD - cf. T207278
ge-8/0/6 up up dumpsdata1001
- puppetmaster1001
- October 24th 14:00 UTC server move (3rd batch) (cloud)
ge-5/0/6 up up labvirt1009:eth0 ge-5/0/7 up up labvirt1008:eth0 ge-5/0/8 up up labvirt1007:eth0 ge-5/0/9 up up labvirt1009:eth1 ge-5/0/10 up up labvirt1008:eth1 ge-5/0/11 up up labvirt1007:eth1 ge-5/0/18 up up labvirt1004 eth0 ge-5/0/19 up up labvirt1005 eth0 ge-5/0/20 up up labvirt1006 eth0 ge-5/0/21 up up labvirt1004 eth1 ge-5/0/22 up up labvirt1005 eth1 ge-5/0/23 up up labvirt1006 eth1 ge-2/0/20 up up labvirt1015-eth0 ge-2/0/21 up up labvirt1015-eth1 ge-3/0/7 up up labvirt1012 eth0 ge-3/0/8 up up labvirt1001 eth0 ge-3/0/9 up up labvirt1012 eth1 ge-3/0/14 up up labvirt1010 eth0 ge-3/0/15 up up labvirt1010 eth1 ge-3/0/16 up up labvirt1011 eth0 ge-3/0/17 up up labvirt1011 eth1 ge-3/0/18 up up labnodepool1001 ge-3/0/20 up up labvirt1002 eth0 ge-3/0/21 up up labvirt1003 eth0 ge-3/0/37 up up labvirt1001 eth1 ge-3/0/38 up up labvirt1002 eth1 ge-3/0/39 up up labvirt1003 eth1 ge-4/0/0 up up labvirt1013 eth0 ge-4/0/9 up up labvirt1016-eth0 ge-4/0/12 up up labvirt1016-eth1 ge-4/0/18 up down labvirt1021 eth2 ge-4/0/36 up up labvirt1013 eth1 ge-4/0/39 up down labnet1002 eth1 xe-4/1/0 up down labnet1002 eth3 xe-4/1/2 up down labnet1002 eth4 ge-5/0/0 up up labvirt1014 eth0 ge-5/0/3 up up labvirt1014 eth1 ge-7/0/6 up up labvirt1017 ge-7/0/11 up up labvirt1017-eth1 ge-7/0/13 up down labvirt1020 ge-8/0/5 up up labvirt1018 ge-8/0/11 up up labpuppetmaster1001 ge-8/0/12 up down labnet1004 ge-8/0/13 up up labvirt1018-eth1 ge-8/0/23 up down labvirt1022 eth3
- Failover VRRP master to cr1
- Verify traffic is properly flowing through cr1/asw2
- Disable interface between cr2 and asw-b-eqiad:ae2
- Move cr2 router uplinks from asw-b to asw2-b (and document cable IDs if different) [Chris/Arzhel]
xe-2/0/46 -> cr2-eqiad:xe-3/0/1 xe-2/0/47 -> cr2-eqiad:xe-4/0/1 xe-7/0/46 -> cr2-eqiad:xe-4/1/1 xe-7/0/47 -> cr2-eqiad:xe-3/1/1
- Re-enable cr2 interfaces
- Move VRRP master back to cr2
- Verify no more traffic on asw-b<->asw2-b link [Arzhel]
- Disable asw-b<->asw2-b link [Arzhel]
- Verify all servers are healthy, monitoring happy
After maintenance window
- Update interfaces descriptions on cr2
- Cleanup config, monitoring, DNS, etc.
- Wipe & unrack asw-b