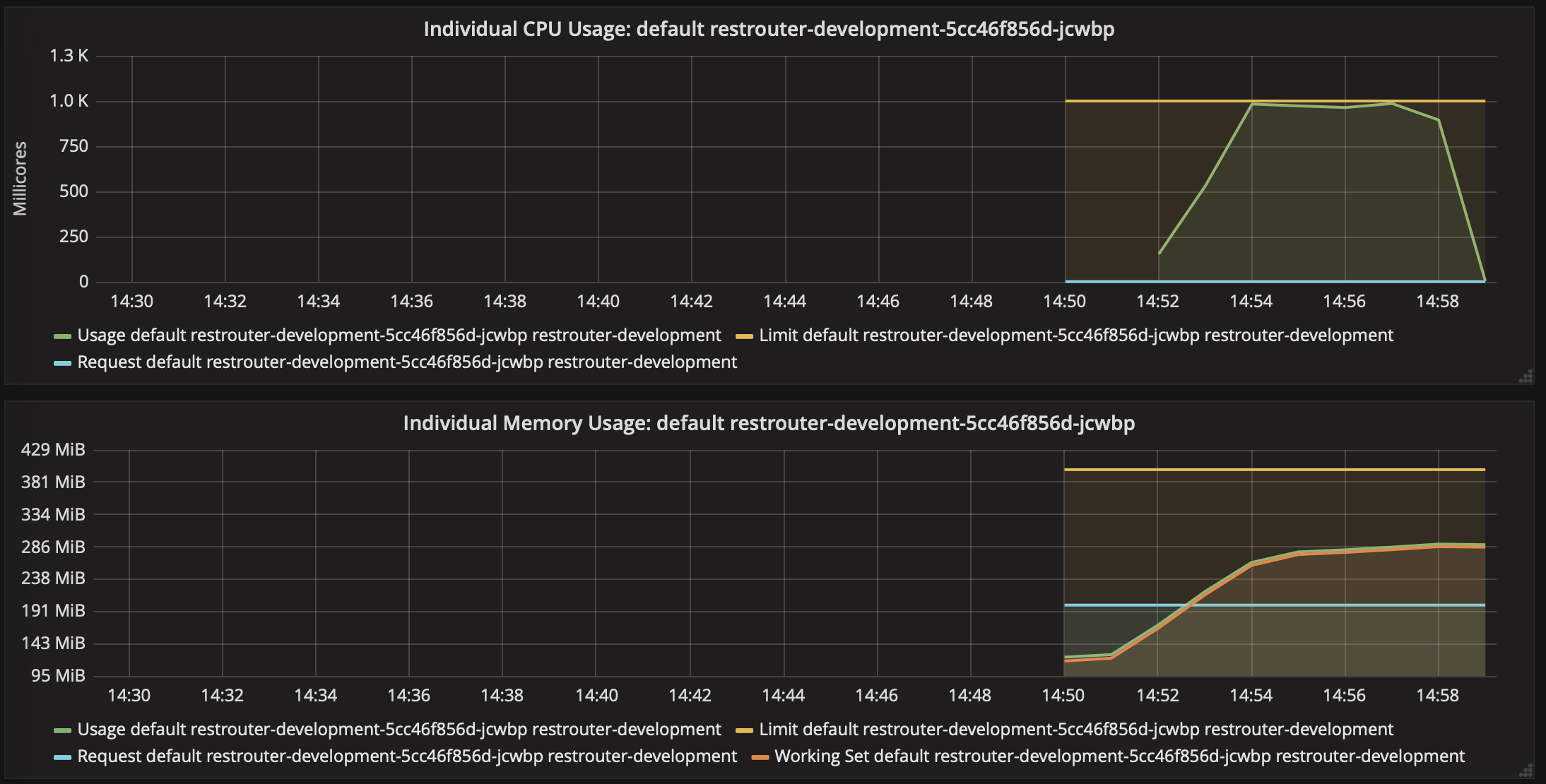
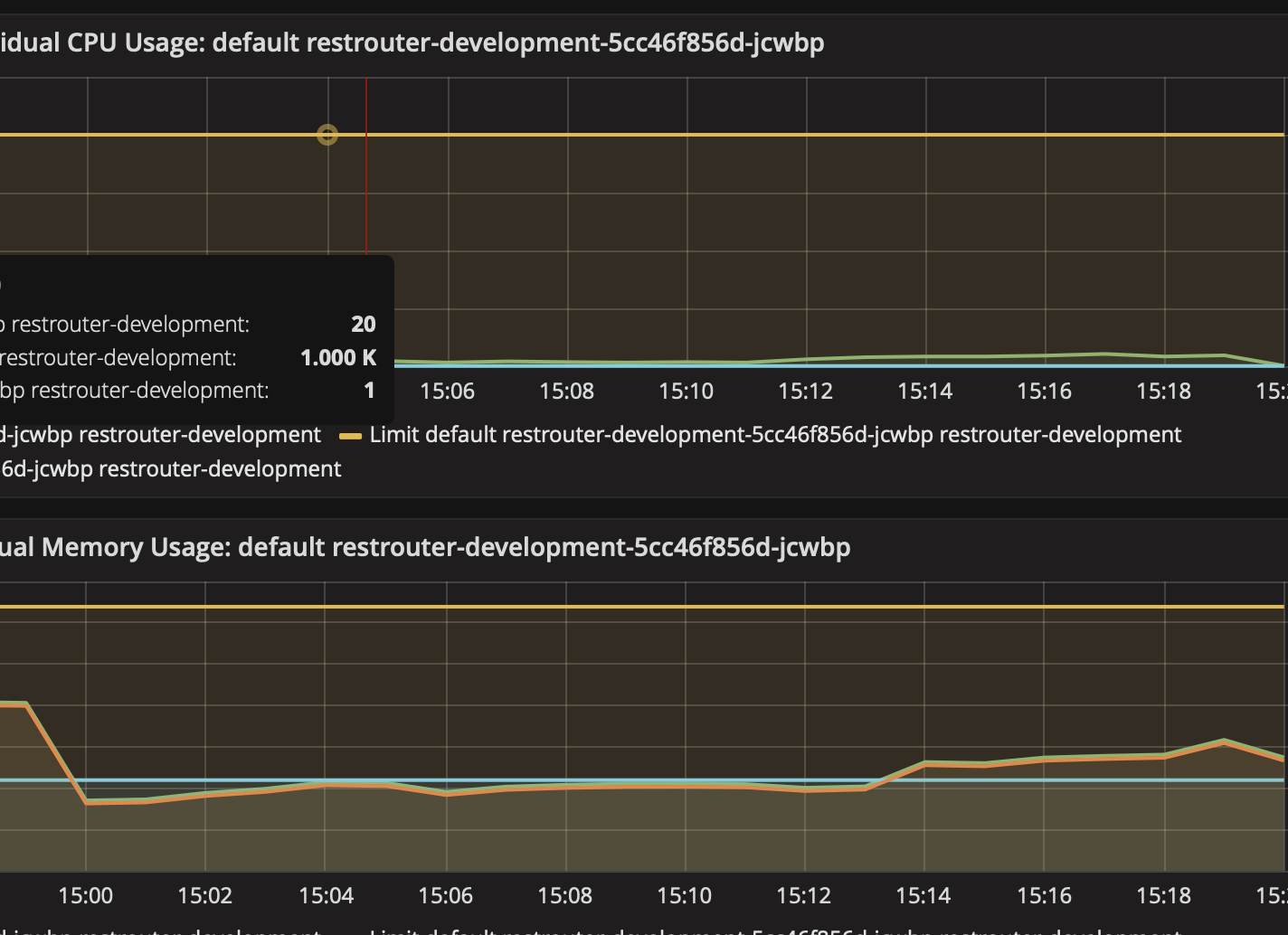
Before we can start the deployment of RESTRouter, we need to determine the CPU and memory constraints to impose on each instance pod. This can be done by using the image that gets build as part of the pipeline job (cf. T226536) and the initial Helm chart locally in minikube. To have a proper set-up to conduct the experiments, see the benchmark wiki page as well as the P8425 script.
Because RESTRouter contacts a considerable amount of back-end services, the challenge here is to have a realistic experiment set up. To do that, I propose to set the local RESTRouter instance in such a way as to issue requests to back-end services located in Beta. This will give us a pathological worst-case scenario when it comes to memory pressure. However, an open question is whether the back-end RESTBase service in Beta should be also used. If so, then it would need to be modified (locally, in-place) to allow external requests to reach the /{domain}/v1/key_value/ hierarchy for the duration of the experiments. Alternatively, a local RESTBase back-end instance can be used for this purpose.
Once the experiments gave us some data, we should incorporate the findings into the Helm chart}(https://gerrit.wikimedia.org/r/#/c/operations/deployment-charts/+/512923/) by adjusting the resources needed for [requests and the respective pod limits.