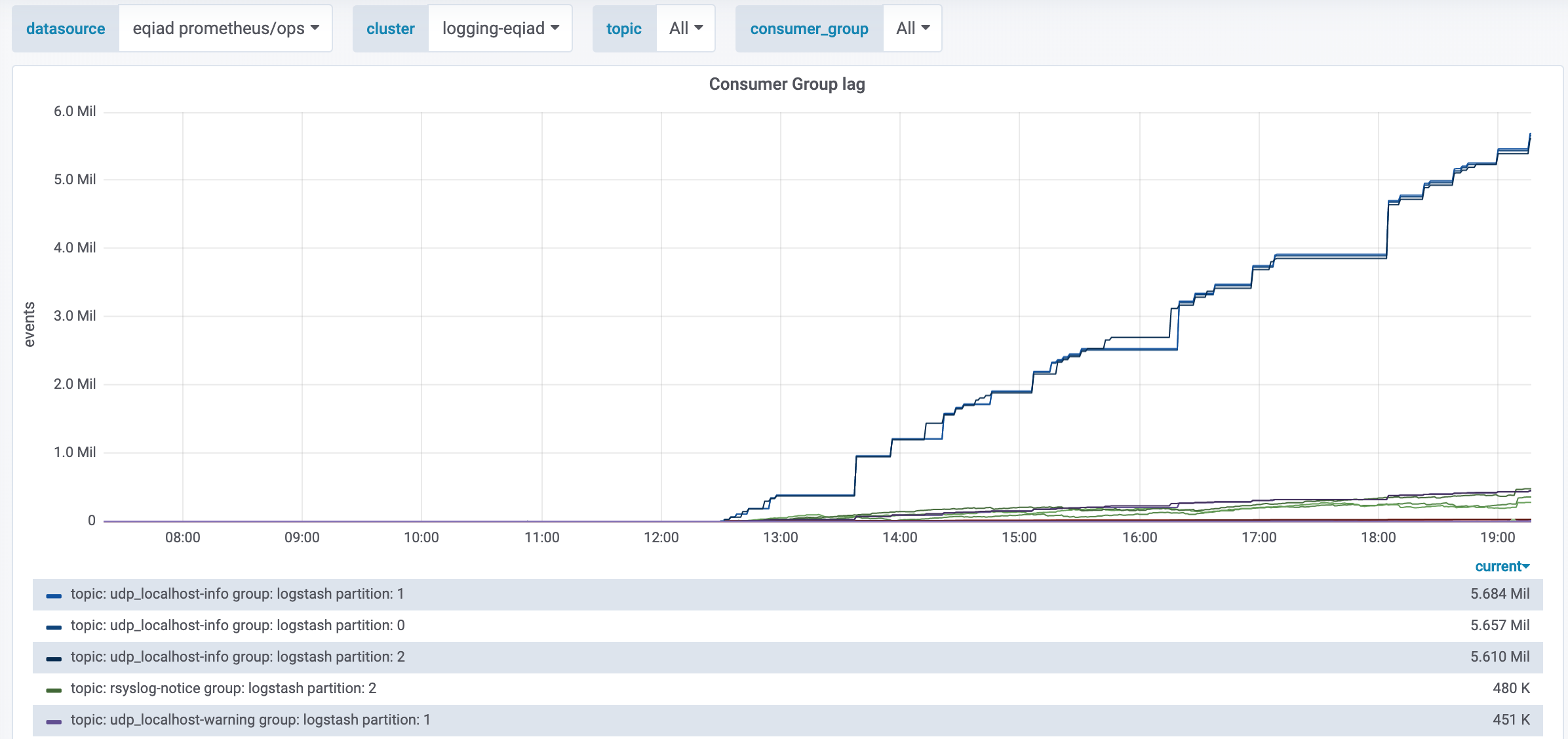
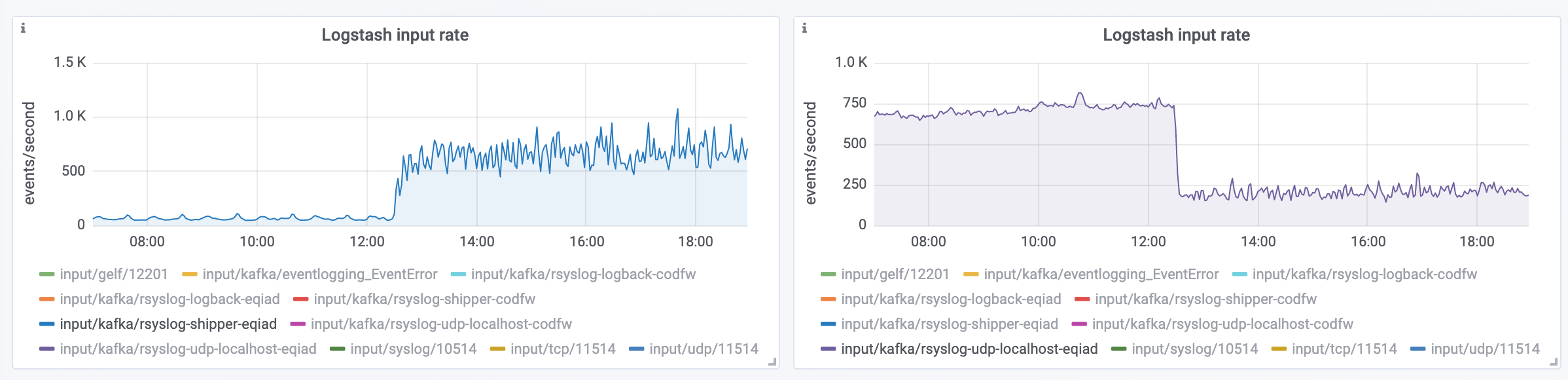
Around 12:30 UTC today, Logstash stopped accepting messages from MediaWiki.
From https://logstash.wikimedia.org/app/kibana#/dashboard/mediawiki-errors


Impact
- Blocks MediaWiki deployments, as Scap checks Logstash during the canary phase.
- Workflow for verifying changes from mwdebug1002 servers false-positively suggests there are no problems. (which unlike the main dashboard, does not appear suspicious because most requests produce no errors and these servers receive no other traffic, so no errors is the default).
- Engineering teams working on MediaWiki have no visibility into operational problems from the PHP core.