Open questions
- How different is to test in the beta cluster and locally, like we did for the initial benchmark? https://phabricator.wikimedia.org/T250493
- Are we testing with Dry Runs? No
Acceptance criteria
- Retrieve benchmarks to compare the performance test against
- Re-do the kubernetes benchmarking LOCALLY
- Re-do the kubernetes benchmarking against BETA clusters
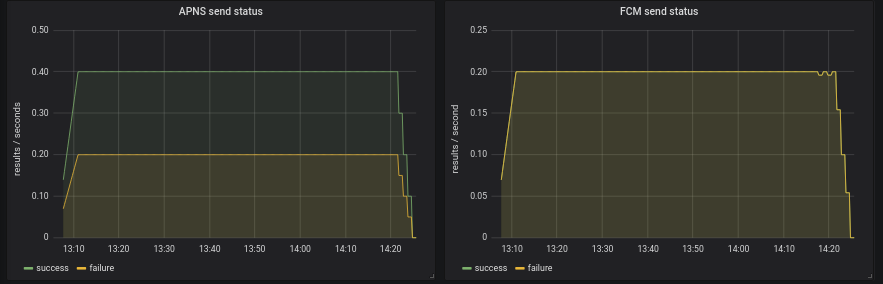
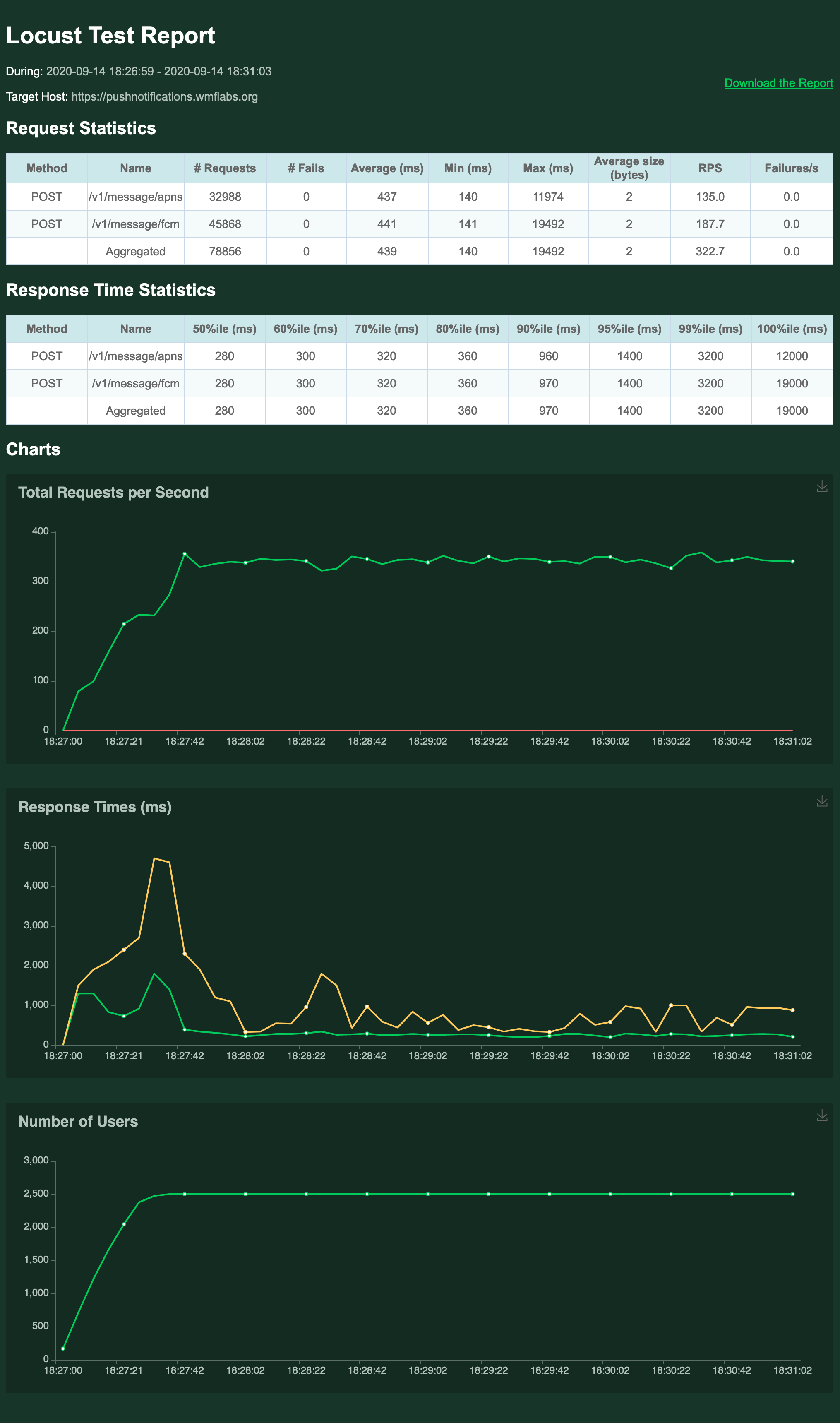
- Include APNS url
Out of Scope
- Not including echo
Notes
- We can potentially use the script that Mateus used on a previous beta test.
Conclusion
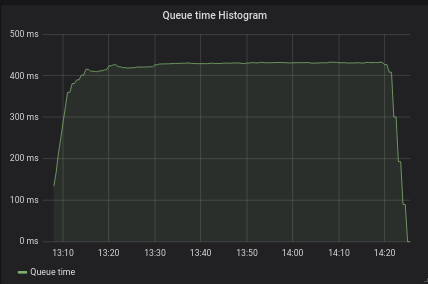
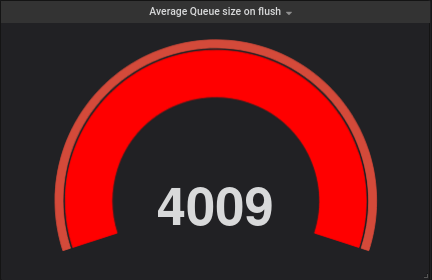
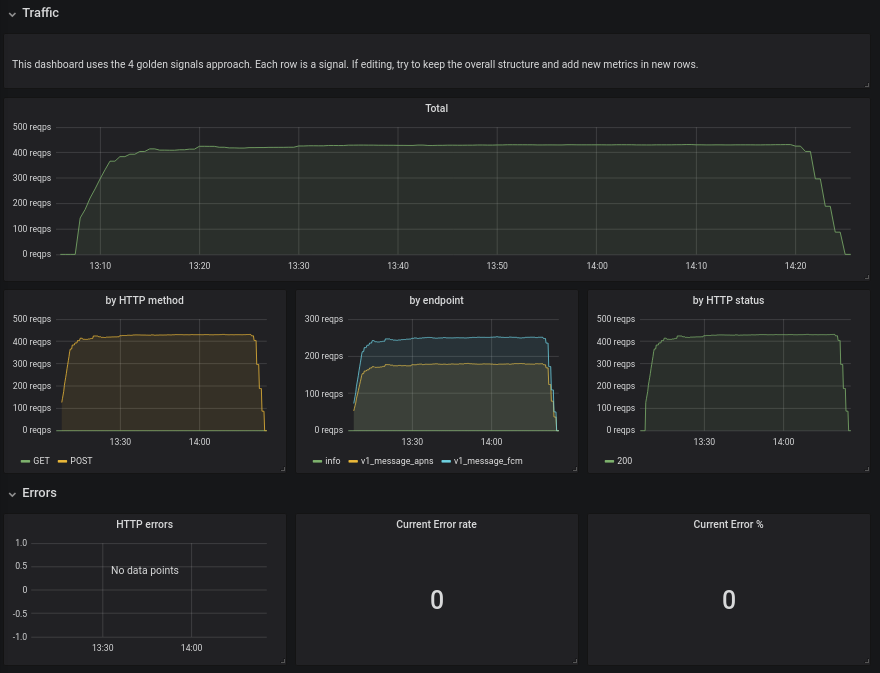
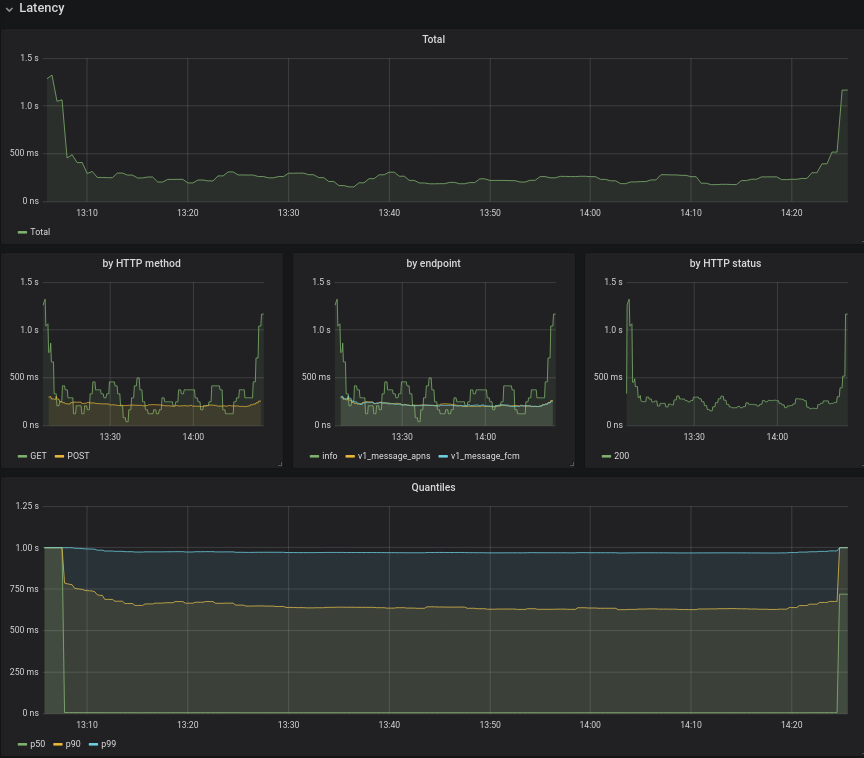
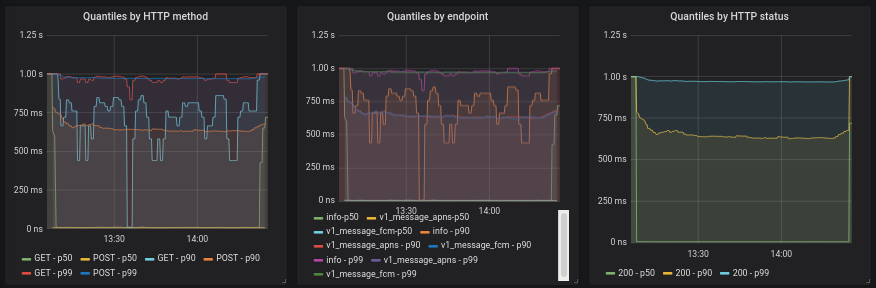
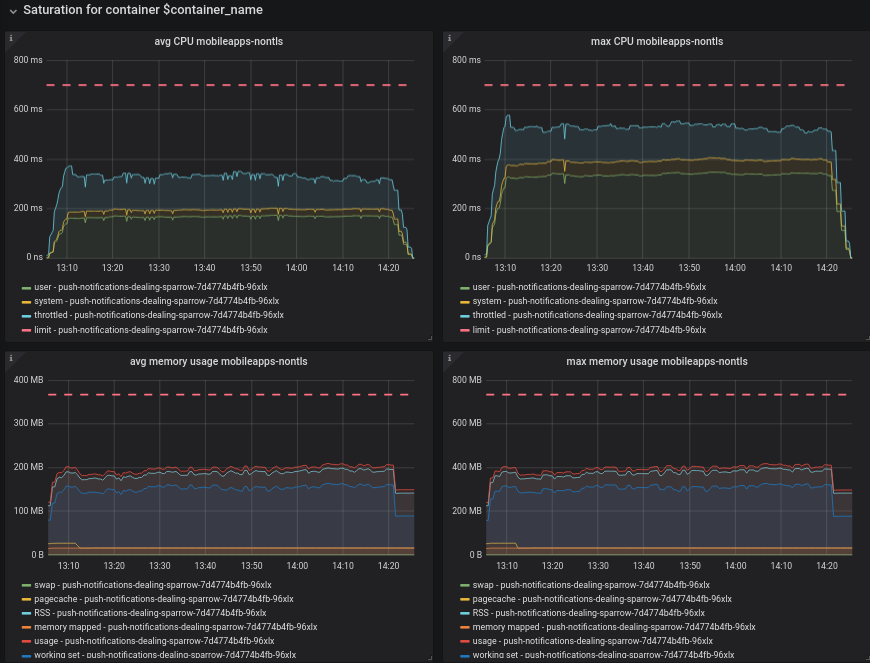
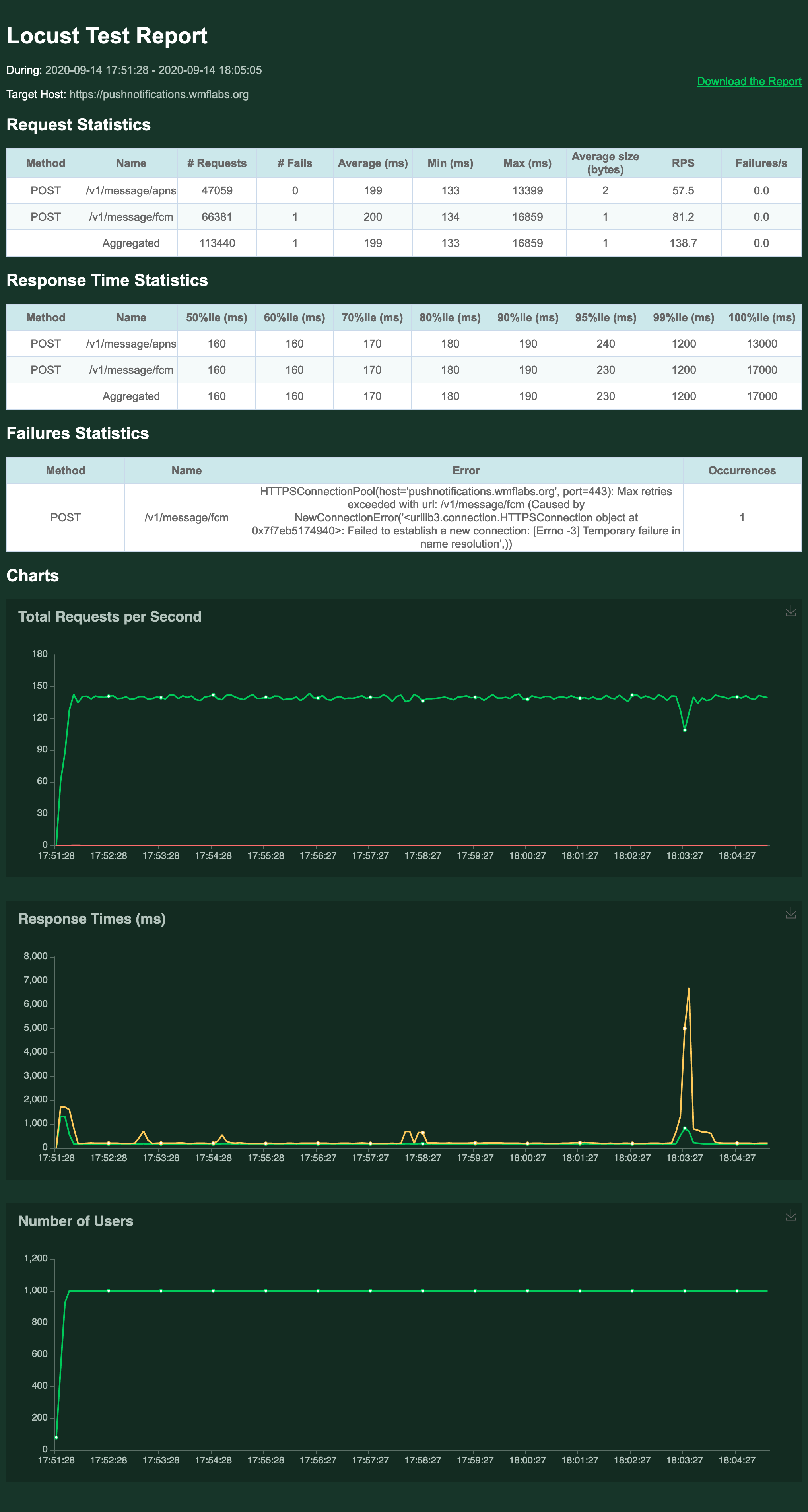
See reports T260807#6432860 and T260807#6459980
A follow-up patch on deployment-charts is to be pushed with the needed changes to run the service with the prometheus metrics collections and the new configurations.
No follow-up issues were found during tests.