Where can centralized backups for GitLab repositories be stored and what network access is required?
Description
Description
Details
Details
| Status | Subtype | Assigned | Task | ||
|---|---|---|---|---|---|
| Resolved | Dzahn | T274458 Remove Speed & Function blockers for GitLab work | |||
| Resolved | Jelto | T274463 Backups for GitLab | |||
| Resolved | Jelto | T316935 Setup partial backups for GitLab | |||
| Resolved | Arnoldokoth | T324506 Investigate incremental backups for GitLab | |||
| Resolved | Jelto | T326315 Align and refactor GitLab restore scripts |
Event Timeline
There are a very large number of changes, so older changes are hidden. Show Older Changes
Comment Actions
Also, after manually starting the "backup-restore" service on gitlab2001, which was still alerting in Icinga, we now have:
23:25 <+icinga-wm> RECOVERY - Check systemd state on gitlab2001 is OK: OK - running: The system is fully operational https://wikitech.wikimedia.org/wiki/Monitoring/check_systemd_state
Comment Actions
Change 677970 abandoned by Jbond:
[operations/puppet@production] O:gitlab: add config for backup sets
Reason:
This is an old batch which has [hopefully] been superseded
Comment Actions
Change 800357 merged by Jelto:
[operations/puppet@production] backup: switch fileset for gitlab from /mnt to /srv
Comment Actions
Change 800358 abandoned by Dzahn:
[operations/puppet@production] gitlab::dump: backup files on gitlab1004 in Bacula
Reason:
not needed anymore, migration happened
Comment Actions
After migrating to new hosts (T307142) we got a bacula alert about backups on gitlab1001 (the old production machine):
PROBLEM - Backup freshness on backup1001 is CRITICAL: All failures: 1 (gitlab1004), Fresh: 115 jobs https://wikitech.wikimedia.org/wiki/Bacula%23Monitoring
This is expected as backups were disabled by switching the active_host.
Backups for the new production host gitlab1004 look as expected. Backups also appear on Bacula:
Select the Client (1-244): 103 Automatically selected FileSet: gitlab +---------+-------+----------+----------------+---------------------+----------------+ | JobId | Level | JobFiles | JobBytes | StartTime | VolumeName | +---------+-------+----------+----------------+---------------------+----------------+ | 447,261 | F | 6 | 14,754,287,536 | 2022-06-03 04:58:17 | production0081 | +---------+-------+----------+----------------+---------------------+----------------+
Restore from Bacula to gitlab1004 worked and the files are similar to todays backup.
One last thing is to increase the local backup retention of GitLab to three days again (see https://gerrit.wikimedia.org/r/c/operations/puppet/+/797278). When that is done this task can be closed I think.
Comment Actions
Bacula is now happy: Fresh: 116 jobs
Note on first setup, the backup check is quite sensitive, so anything that is not a sucessful completion will be considered a failure, hence the "all failures" while it is running. :-) This is a bit annoying, but it is rare, and difficult to tune (there are many statuses that would have to be classified. Also there is some lag for icinga, as checking all backups is a bit slow, while the old check is removed.
FYI, I have a custom wrapper to check the list of past runs (and I think it is easier for quick checks), which is:
root@backup1001:~$ check_bacula.py gitlab1004.wikimedia.org-Daily-production-gitlab id: 447261, ts: 2022-06-03 04:58:17, type: F, status: T, bytes: 14754287536
T means successful completion.
This is the equivalent dashboard for the new host: https://grafana.wikimedia.org/d/413r2vbWk/bacula?orgId=1&var-site=eqiad&var-job=gitlab1004.wikimedia.org-Daily-production-gitlab&from=1654266128184&to=1654269728185
I also checked the logs, no errors there either.
Comment Actions
Change 802823 had a related patch set uploaded (by Dzahn; author: Dzahn):
[operations/puppet@production] gitlab::dump: delete class
Comment Actions
Change 802847 had a related patch set uploaded (by Dzahn; author: Dzahn):
[operations/puppet@production] site: remove gitlab_dump role from gitlab2002
Comment Actions
Change 802847 merged by Dzahn:
[operations/puppet@production] site: remove gitlab_dump role from gitlab2002
Comment Actions
Mentioned in SAL (#wikimedia-operations) [2022-06-03T19:29:37Z] <mutante> gitlab2002 - stop rsync service, apt-get remove --purge rsync, delete /etc/rsync.d/ and /etc/rsyncd.conf - after gerrit:802847 T274463
Comment Actions
Change 802823 merged by Jelto:
[operations/puppet@production] gitlab::dump: delete role and profile classes
Comment Actions
unfortunately just noticed an Icinga alert for gitlab1003 (nothing mails us about this, that's just if you happen to log at web UI for some reason)
and it's backup related: CRITICAL - degraded: The following units failed: backup-restore.service,wmf_auto_restart_ssh-gitlab.service
Comment Actions
Jul 01 01:33:24 gitlab1003 gitlab-restore.sh[2196430]: /opt/gitlab/embedded/service/gitlab-rails/lib/backup/manager.rb:94:in `each' Jul 01 01:33:24 gitlab1003 gitlab-restore.sh[2196430]: /opt/gitlab/embedded/service/gitlab-rails/lib/backup/manager.rb:94:in `restore' Jul 01 01:33:24 gitlab1003 gitlab-restore.sh[2196430]: /opt/gitlab/embedded/service/gitlab-rails/lib/tasks/gitlab/backup.rake:20:in `block (3 levels) in <top (required)>' Jul 01 01:33:24 gitlab1003 gitlab-restore.sh[2196430]: /opt/gitlab/embedded/bin/bundle:23:in `load' Jul 01 01:33:24 gitlab1003 gitlab-restore.sh[2196430]: /opt/gitlab/embedded/bin/bundle:23:in `<main>' Jul 01 01:33:24 gitlab1003 gitlab-restore.sh[2196430]: Tasks: TOP => gitlab:backup:restore Jul 01 01:33:24 gitlab1003 gitlab-restore.sh[2196430]: (See full trace by running task with --trace) Jul 01 01:33:24 gitlab1003 systemd[1]: backup-restore.service: Main process exited, code=exited, status=1/FAILURE Jul 01 01:33:24 gitlab1003 systemd[1]: backup-restore.service: Failed with result 'exit-code'.
Jul 01 14:20:08 gitlab1003 systemd[1]: Started Auto restart job: ssh-gitlab. Jul 01 14:20:08 gitlab1003 wmf-auto-restart[124081]: INFO: 2022-07-01 14:20:08,172 : Service ssh-gitlab not present or not running Jul 01 14:20:08 gitlab1003 systemd[1]: wmf_auto_restart_ssh-gitlab.service: Main process exited, code=exited, status=1/FAILURE Jul 01 14:20:08 gitlab1003 systemd[1]: wmf_auto_restart_ssh-gitlab.service: Failed with result 'exit-code'.
Comment Actions
Thanks for sharing the backup-restore issues here.
I tried to restart all gitlab components using gitlab-ctl stop and gitlab-ctl start. This did not work because multiple services failed to come up. I noticed some of this services wanted to bind to a wrong ip address (gitlab1004 address and not gitlab1003). So I tried to run puppet using run-puppet-agent to correct the addresses in the /etc/gitlab/gitlab.rb config file. However puppet run failed with:
Error: Could not retrieve catalog from remote server: Error 500 on SERVER: Server Error: Evaluation Error: Error while evaluating a Resource Statement, Prometheus::Blackbox::Check::Http[gitlab.wikimedia.org]: parameter 'body_regex_matches' expects an Array value, got String (file: /etc/puppet/modules/profile/manifests/gitlab.pp, line: 44)
I reverted the change which introduced the Blackbox exporter in https://gerrit.wikimedia.org/r/c/operations/puppet/+/810899. I guess the fix is quite small, but this is blocking updates and the GitLab hosts were close to being garbage collected.
After reverting a manual restore (systemctl start backup-restore) on gitlab1003 finished successfully.
Jul 05 10:04:39 gitlab1003 systemd[1]: backup-restore.service: Succeeded.
Nothing major is needed. Backups are configured and in place.
This task was mostly used to track backup and restore related bugs. But we can close this if backup-restore works fine the next days.
Comment Actions
Sorry about this. This has been fixed. Monitoring change was re-reverted and is not causing puppet errors anymore.
Comment Actions
Mentioned in SAL (#wikimedia-operations) [2022-07-06T01:21:25Z] <mutante> gitlab1004 rm /lib/systemd/system/rsync-data-backup-gitlab2001.wikimedia.org.* ; systemctl reset-failed (T274463, T307142) - fix icinga alert after gitlab2001 was decom'ed, we didn't have puppet remove the timer/service
Comment Actions
01:04 <+icinga-wm> PROBLEM - Check systemd state on gitlab1004 is CRITICAL: CRITICAL - degraded: The following units failed:
rsync-config-backup-gitlab2001.wikimedia.org.service,rsync-data-backup-gitlab2001.wikimedia.org.service https://wikitech.wikimedia.org/wiki/Monitoring/check_systemd_state^ looked like a fail at first but looking closer it's just the rsync to gitlab2001 and that was decom'ed today at T307142#8053147.
rm /lib/systemd/system/rsync-data-backup-gitlab2001.wikimedia.org.* ; systemctl reset-failed
01:21 <+icinga-wm> RECOVERY - Check systemd state on gitlab1004 is OK: OK - running: The system is fully operational https://wikitech.wikimedia.org/wiki/Monitoring/check_systemd_state
Comment Actions

Backups on gitlab1004 failed today due to full backup disk. There was no error on gitlab1004. The backup job exited with
Aug 01 00:21:03 gitlab1004 systemd[1]: full-backup.service: Succeeded. Aug 01 00:21:03 gitlab1004 systemd[1]: full-backup.service: Consumed 18min 44.960s CPU time.
I noticed the failure due to a non-working replica. Checking the backups showed the backup was missing ~13gb of data compared to the previous one. In Grafana a spike to 100% disk usage can be seen:

I re-run the backup on gitlab1004 with systemctl start full-backup, which created a proper backup. I synced the backup to the replica using systemctl start rsync-data-backup-gitlab1003.wikimedia.org.service. On the replica I triggered a restore with systemctl start backup-restore. Which was successful too. Replica is working again.
Before closing this task the backup (and restore) should be made more robust. I'm thinking about:
- alerting for non-completed backups for the production instance
- alerting for a failed restore on the replica/non working replica
- making the restore more idempotent. Currently a failed restore needs manual action because puppet is stopped, config files are mixed up and troubleshooting is needed
- more space for backups or less backups on the production host. This could mean ordering more disks for the host or setting up a dedicated backup host (I am not sure if that's needed parallel to bacula)
- refactor gitlab-backup.sh script to make disk usage more efficient (by using symlinks?) and check if exit codes can be used properly
- resize lvm/partman volumes
Comment Actions It would solve most of the issues above, and on a first phase you could just keep the gitlab-backup.sh script without much effort (without needing a full reimplementation, if you don't want it). The advantage is it is already a well-maintained piece of software, with unit tests and will continue to be maintained as it is core to database backups. Implementing a new backup type is as easy as implementing a child of the Backup class: https://phabricator.wikimedia.org/diffusion/OSWB/browse/master/wmfbackups/NullBackup.py and you would get for free the icinga checks, prometheus metrics, etc. I probably could do it in a few hours.
It would solve most of the issues above, and on a first phase you could just keep the gitlab-backup.sh script without much effort (without needing a full reimplementation, if you don't want it). The advantage is it is already a well-maintained piece of software, with unit tests and will continue to be maintained as it is core to database backups. Implementing a new backup type is as easy as implementing a child of the Backup class: https://phabricator.wikimedia.org/diffusion/OSWB/browse/master/wmfbackups/NullBackup.py and you would get for free the icinga checks, prometheus metrics, etc. I probably could do it in a few hours.
What about integrating gitlab backups with wmfbackups automation? Database backups started as a bash script, but when it was clear more sophisticated backup methods were needed, including scheduling, monitoring, metrics and metadata storage, I created an extensible framework for it, written in python, intended to be extended in the future by other backup types. I am also currently (T283017) building a nice dashboard for monitoring backup runs- including fine-grained size checks:
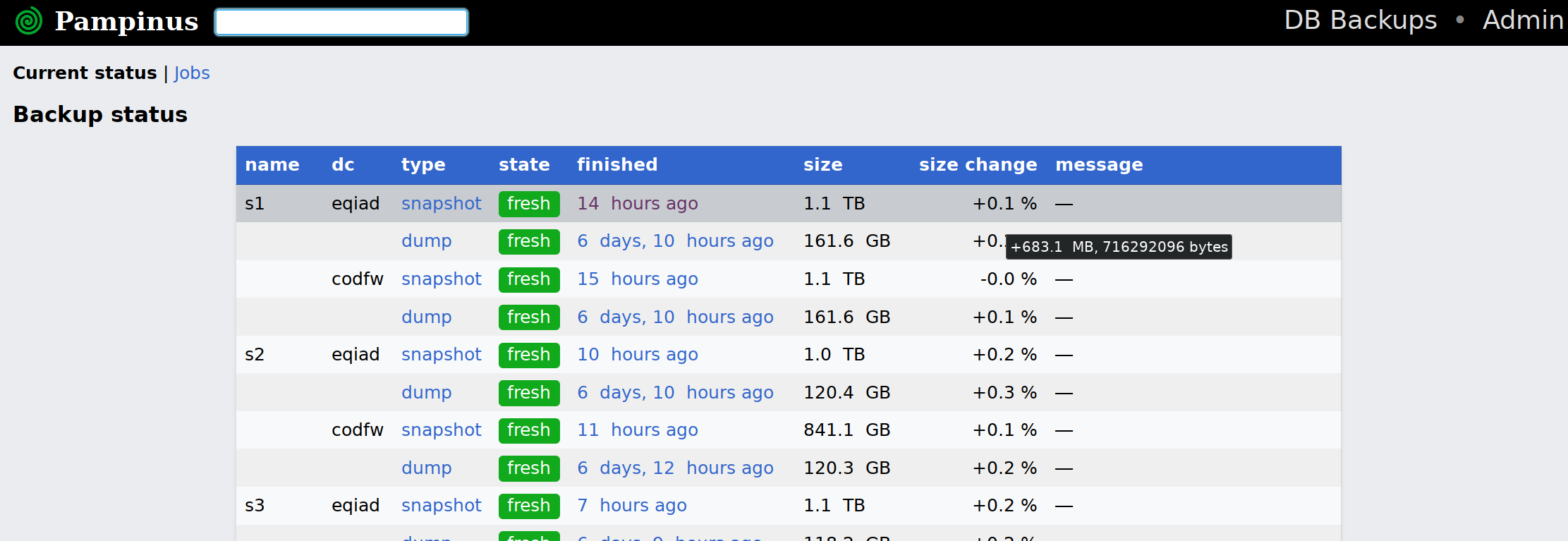
Edit: There are multiple issues with the current setup- bacula is getting weird files from May 26, and the latest config backup is from Jun 2- something that the checks from wmfbackups could have caught.
Comment Actions
Change 819109 had a related patch set uploaded (by Jcrespo; author: Jcrespo):
[operations/software/wmfbackups@master] Enable gitlab backup type for wmfbackups
Comment Actions
Change 820712 had a related patch set uploaded (by Jelto; author: Jelto):
[operations/puppet@production] gitlab: reduce backup_keep_time to 2d
Comment Actions
Change 820712 merged by Jelto:
[operations/puppet@production] gitlab: reduce backup_keep_time to 2d
Comment Actions
Backups on gitlab1004 failed again silently due to disk space issues. Restore on both replicas gitlab1003 and gitlab2002 failed due to non-complete backups.
I reduced the backup keep time on production host to 2 days, to give us more time to implement a proper solution. I triggered a manual backup and restore, all instances are up again.
Thanks for mentioning this framework and preparing the patch! I'll try to read about that and do a review as soon as possible.
Thanks for pointing this out. The current production instance gitlab1004 was a replica before. So there are some old files which are not meant to be in the backup (lates-config.tar and latest.tar in /srv/gitlab-backup/latest). The config backup is saved in a dedicated fileset location at /etc/gitlab/config_backup/latest/. I'll try to clean that up and double check the backups on bacula, so that only new and relevant files are in the backup.
Comment Actions
Please note the patch is not complete, it was a discussion-starter. Let's try to meet to sync- my intention here is to try to help you and support you in any way I can to make sure backup is something that doesn't bother you frequently.
I have experience of dealing scaling the "small" database backup project into a properly maintained service, so hopefully that can help you- most of the issues you are experiencing are familiar to me. I will be needing help, however, as I am not as familiar with GitLab as I was with databases, so I propose to organize a meeting.
Comment Actions
I removed the old stale files from the the backup folder yesterday. I checked the backup in bacula and it contains only 2 files now, which are up to date. This old files were used when gitlab1004 was setup as a replica.
gitlab1004:/var/tmp/bacula-restores# tree
.
├── etc
│ └── gitlab
│ └── config_backup
│ └── latest
│ └── latest-config.tar
└── srv
└── gitlab-backup
└── latest
└── latest-data.tarFurthermore @jcrespo and I had a chat on how to integrate GitLab to wmfbackups. We decided that GitLab would be quite a good fit to integrate into wmfbackups for additional monitoring and alerting of backups.
Long term plans
The current size of the lvm backup volume with 225GB is too small. Long term the lvm volume for backups has to be increased or the backups have to be stored somewhere else (other host, object storage, ...). So the partman config for GitLab hosts has to be adjusted from:
vg-root 457.7G lvm / vg-srv--registry 139.7G lvm /srv/registry vg-srv--gitlab--backup 228.7G lvm /srv/gitlab-backup vg-placeholder 23.3G lvm
To something like:
vg-root 300.0G lvm / vg-srv--registry 100.0G lvm /srv/registry vg-srv--gitlab--backup 425.0G lvm /srv/gitlab-backup vg-placeholder 2.0G lvm
With the new config, all hosts have to be re-imaged and at least one failover is needed.
However it's not clear if doubling the volume size solves this issue completely. I would estimate that we have to open this discussion again if GitLab backups grew even more (like ~100gb per backup).
Intermediate workarounds
Reimage all GitLab hosts and doing a failover is quite a lot of work with the possibility of data loss. There are some less invasive options.
Adjust non root volumes
It would be possible to alter the non-root lvm volumes without reimage the host. The volume for the (not used) registry and all remaining placeholder space could be assigned to the backup volume. With this additional space the backup volume could be increased to ~300-320GB. This would give at least multiple month room until the backup of GitLab needs even more space.
Don't use STRATEGY=copy
The backup strategy copy is used currently. This means all data is dumped into a temporary location first (which is also the backup folder) and then archived into a tarball. We could drop this option, which would reduce the needed space for backups drastically. The documentation states This works fine in most cases, but can cause problems when data is rapidly changing.. So we need to evaluate if this applies to us and if we want to take that risk.
Store backup in other folder
Backup creation needs a lot of space (see section above). There is no proper option to specify a temporary folder for this process. However there is a workaround to dump and create the backups in another folder than the final folder location. For that local upload connection can be used.
With this approach the backup can be created on the big root volume and then "uploaded" to the backup volume. This could be implemented without a reimage. However this would open up the risk that backup jobs could fill the root partition.
Comment Actions
Change 823115 had a related patch set uploaded (by Jelto; author: Jelto):
[operations/puppet@production] install_server: change partman config for gitlab
Comment Actions
Change 823115 merged by Jelto:
[operations/puppet@production] install_server: change partman config for gitlab
Comment Actions
Mentioned in SAL (#wikimedia-operations) [2022-08-16T10:30:27Z] <jelto> reimaging gitlab2003 (insetup) to test partman recipe from gerrit:823115 - T274463
Comment Actions
Cookbook cookbooks.sre.hosts.reimage was started by jelto@cumin1001 for host gitlab2003.wikimedia.org with OS bullseye
Comment Actions
Cookbook cookbooks.sre.hosts.reimage started by jelto@cumin1001 for host gitlab2003.wikimedia.org with OS bullseye completed:
- gitlab2003 (PASS)
- Downtimed on Icinga/Alertmanager
- Disabled Puppet
- Removed from Puppet and PuppetDB if present
- Deleted any existing Puppet certificate
- Removed from Debmonitor if present
- Forced PXE for next reboot
- Host rebooted via IPMI
- Host up (Debian installer)
- Host up (new fresh bullseye OS)
- Generated Puppet certificate
- Signed new Puppet certificate
- Run Puppet in NOOP mode to populate exported resources in PuppetDB
- Found Nagios_host resource for this host in PuppetDB
- Downtimed the new host on Icinga/Alertmanager
- Removed previous downtime on Alertmanager (old OS)
- First Puppet run completed and logged in /var/log/spicerack/sre/hosts/reimage/202208161033_jelto_640717_gitlab2003.out
- Checked BIOS boot parameters are back to normal
- configmaster.wikimedia.org updated with the host new SSH public key for wmf-update-known-hosts-production
- Rebooted
- Automatic Puppet run was successful
- Forced a re-check of all Icinga services for the host
- Icinga status is optimal
- Icinga downtime removed
- Updated Netbox data from PuppetDB
Comment Actions
New partman config
The new partman config on gitlab2003 increased the size of the backup volume:
vg-root 326G lvm / vg-srv--registry 111G lvm /srv/registry vg-srv--gitlab--backup 407G lvm /srv/gitlab-backup vg-placeholder 4.7G lvm
However I had a discussion with @LSobanski about where and how we want to store the backups long term. Above comments describe the approach of storing multiple backups on the production machine and resize the backup volume accordingly. This approach is mostly historical and was done for faster restores and additional redundancy (and because we were not fully familiar with bacula, I guess?).
Change plans and storing backups on the replicas
It is not clear if increasing the backup volume works long-term. If the backup size increases even more additional LVM resizes and reimages are needed. Additionally the root volume, which stores the git code and other artifacts gets less space with each resize. We are using 60GB on the root volume currently. So if we continue to increase the backup volume we may run out disk space for the root partition in some time. So before we invest more time into reimage all hosts some additional thoughts.
@LSobanski suggested that we may use the already existing replicas to store more than one backup. Currently we only store the latest backup on the replicas. This would provide the additional redundancy together with less disk pressure on the production machine. Creating and storing backups in a different locations helps with the inefficient way GitLab is dumping the backups.
This would mean additional backup rotation logic is needed on the replicas and we need additional time to restore the production instance. We either have to restore the backup from bacula or from a replica for backups older than one day. I've done a quick test and restoring from bacula and other replicas is roughly 1gbit raw link speed, which means additional ~5 minutes for the current backup size. Restore between DCs is a little bit slower ~8 minutes.
I would like to discuss this with a wide audience soon. I'll schedule a session or hijack the IC sync for that. So in conclusion a long-term solution for backups could look like:
- production: stores latest backup and uses additional space for backup creation
- replicas: stores 3 latest backups
- bacula: long term storage of backups
Comment Actions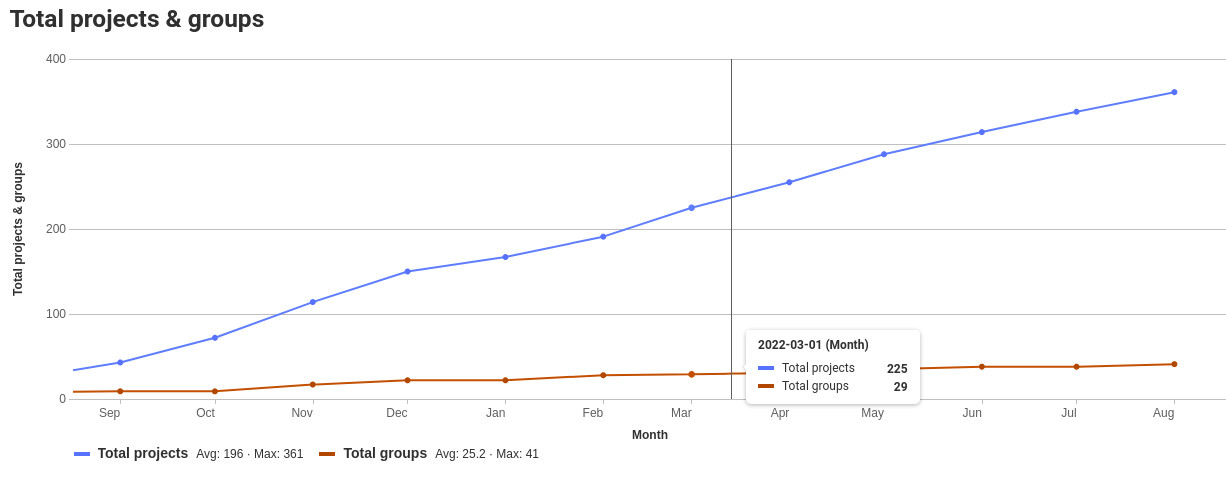
@LSobanski and I talked about predicting storage space of GitLab as we grow. We've learned that storage growth is much different than Gerrit.
In March, we finalized a structure to start moving projects, so that seems like a reasonable place to start.
Projects added per month
In March, we had 225 projects
Today we have 361 projects.
So, we added 126 projects in 5 months, so roughly 25 projects/month.
Data use per project
GitLab, unlike Gerrit, doesn't only store git repos. It stores git-lfs objects, packages, artifacts, and it has a database.
As of 17 Aug, 2022:
git data 3.2G artifact storage 41G postgresql 523M ------------------------ Total 44.723G
- 45GB/361 projects ~= 125M/project
- 125M * 25 projects/mo ~= 3.125G/mo storage growth
Caveats
- Issues are disabled for most repos
- Growth will be unpredictable and the rate will fluctuate as we undertake migrations and more projects implement GitLab CI / publish packages
- These numbers account for the GitLab root logical volume
- GitLab's native Docker registry is currently disabled, so we're not storing any images, although we have set aside 137G on /srv/registry
- These numbers don't account for backups, stored on /srv/gitlab-backup, just keep in mind backup size will scale with them
Comment Actions
Change 824730 had a related patch set uploaded (by Jelto; author: Jelto):
[operations/puppet@production] gitlab: use actual backup name instead of latest on replica
Comment Actions
Change 824739 had a related patch set uploaded (by Jelto; author: Jelto):
[operations/puppet@production] gitlab: rotate backups on replica
Comment Actions
While doing some research about GitLab disk space usage I found some projects which use significantly more disk space. Most of the affected projects were building big CI artifacts and storing them in the GitLab package registry. I reached out to the project owners and they cleaned up old packages and installed more aggressive cleanup policies. The size of this projects and packages was reduces significantly. Backups are half the size now.
I created a follow up task to implement default package cleanup policies for all (new?) projects: T315877
Backup volume utilization is down from 50% to around 25% now, root volume usage is 14%. So this gives us some more time to implement a proper long term solution for handling and storing backups for GitLab.
{F35483821}
Comment Actions
Change 824739 abandoned by Jelto:
[operations/puppet@production] gitlab: rotate backups on replica
Reason:
not needed anymore, other backup strategy is used
Comment Actions
Change 824730 abandoned by Jelto:
[operations/puppet@production] gitlab: use actual backup name instead of latest on replica
Reason:
not needed anymore, other backup strategy is used
Comment Actions
Change 827578 had a related patch set uploaded (by Dzahn; author: Jelto):
[operations/puppet@production] Revert "install_server: change partman config for gitlab"
Comment Actions
Change 827578 merged by Dzahn:
[operations/puppet@production] Revert "install_server: change partman config for gitlab"
Comment Actions
gitlab2003 (which had been used to test the new partman config) before reverting the partman change:
Filesystem Size Used Avail Use% Mounted on udev 63G 0 63G 0% /dev tmpfs 13G 1.5M 13G 1% /run /dev/mapper/gitlab2003--vg-root 320G 4.1G 300G 2% / tmpfs 63G 0 63G 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock /dev/mapper/gitlab2003--vg-srv--gitlab--backup 400G 28K 380G 1% /srv/gitlab-backup /dev/mapper/gitlab2003--vg-srv--registry 110G 24K 104G 1% /srv/registry tmpfs 13G 0 13G 0% /run/user/2075
reimaging gitlab2003 after deploying the revert based on Jelto's comment at https://gerrit.wikimedia.org/r/c/operations/puppet/+/827578
Comment Actions
Mentioned in SAL (#wikimedia-operations) [2022-08-31T19:15:44Z] <mutante> gitlab: reimaging gitlab2003 with cookbook after reverting partman change and comment on gerrit:827578 T274463
Comment Actions
Cookbook cookbooks.sre.hosts.reimage was started by dzahn@cumin2002 for host gitlab2003.wikimedia.org with OS bullseye
Comment Actions
Cookbook cookbooks.sre.hosts.reimage started by dzahn@cumin2002 for host gitlab2003.wikimedia.org with OS bullseye executed with errors:
- gitlab2003 (FAIL)
- Downtimed on Icinga/Alertmanager
- Disabled Puppet
- Removed from Puppet and PuppetDB if present
- Deleted any existing Puppet certificate
- Removed from Debmonitor if present
- Forced PXE for next reboot
- Host rebooted via IPMI
- The reimage failed, see the cookbook logs for the details
Comment Actions
Cookbook cookbooks.sre.hosts.reimage was started by dzahn@cumin2002 for host gitlab2003.wikimedia.org with OS bullseye
Comment Actions
Cookbook cookbooks.sre.hosts.reimage started by dzahn@cumin2002 for host gitlab2003.wikimedia.org with OS bullseye completed:
- gitlab2003 (PASS)
- Removed from Puppet and PuppetDB if present
- Deleted any existing Puppet certificate
- Removed from Debmonitor if present
- Forced PXE for next reboot
- Host rebooted via IPMI
- Host up (Debian installer)
- Host up (new fresh bullseye OS)
- Generated Puppet certificate
- Signed new Puppet certificate
- Run Puppet in NOOP mode to populate exported resources in PuppetDB
- Found Nagios_host resource for this host in PuppetDB
- Downtimed the new host on Icinga/Alertmanager
- First Puppet run completed and logged in /var/log/spicerack/sre/hosts/reimage/202208311921_dzahn_3653384_gitlab2003.out
- Checked BIOS boot parameters are back to normal
- configmaster.wikimedia.org updated with the host new SSH public key for wmf-update-known-hosts-production
- Rebooted
- Automatic Puppet run was successful
- Forced a re-check of all Icinga services for the host
- Icinga status is optimal
- Icinga downtime removed
- Updated Netbox data from PuppetDB
Comment Actions
gitlab2003 has been reimaged.
ECDSA key fingerprint is SHA256:hdh4RRTigMf9Q0+fqMKk8e35g0wVUhceRYYlEPLmgf8.
now it looks like this:
root@gitlab2003:/# df -h Filesystem Size Used Avail Use% Mounted on udev 63G 0 63G 0% /dev tmpfs 13G 1.5M 13G 1% /run /dev/mapper/gitlab2003--vg-root 320G 2.2G 302G 1% / tmpfs 63G 0 63G 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock /dev/mapper/gitlab2003--vg-srv--gitlab--backup 400G 28K 380G 1% /srv/gitlab-backup /dev/mapper/gitlab2003--vg-srv--registry 110G 24K 104G 1% /srv/registry tmpfs 13G 0 13G 0% /run/user/2075
which is.. the same?
Comment Actions
Cookbook cookbooks.sre.hosts.reimage was started by dzahn@cumin2002 for host gitlab2003.wikimedia.org with OS bullseye
Comment Actions
Cookbook cookbooks.sre.hosts.reimage started by dzahn@cumin2002 for host gitlab2003.wikimedia.org with OS bullseye completed:
- gitlab2003 (PASS)
- Downtimed on Icinga/Alertmanager
- Disabled Puppet
- Removed from Puppet and PuppetDB if present
- Deleted any existing Puppet certificate
- Removed from Debmonitor if present
- Forced PXE for next reboot
- Host rebooted via IPMI
- Host up (Debian installer)
- Host up (new fresh bullseye OS)
- Generated Puppet certificate
- Signed new Puppet certificate
- Run Puppet in NOOP mode to populate exported resources in PuppetDB
- Found Nagios_host resource for this host in PuppetDB
- Downtimed the new host on Icinga/Alertmanager
- Removed previous downtime on Alertmanager (old OS)
- First Puppet run completed and logged in /var/log/spicerack/sre/hosts/reimage/202208312022_dzahn_3664849_gitlab2003.out
- Checked BIOS boot parameters are back to normal
- configmaster.wikimedia.org updated with the host new SSH public key for wmf-update-known-hosts-production
- Rebooted
- Automatic Puppet run was successful
- Forced a re-check of all Icinga services for the host
- Icinga status is optimal
- Icinga downtime removed
- Updated Netbox data from PuppetDB
Comment Actions
puppet had not run on apt* yet. I had to repeat the reimaging. But now it looks as intended:
[gitlab2003:~] $ df -h Filesystem Size Used Avail Use% Mounted on udev 63G 0 63G 0% /dev tmpfs 13G 1.5M 13G 1% /run /dev/mapper/gitlab2003--vg-root 450G 2.2G 425G 1% / tmpfs 63G 0 63G 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock /dev/mapper/gitlab2003--vg-srv--gitlab--backup 225G 28K 213G 1% /srv/gitlab-backup /dev/mapper/gitlab2003--vg-srv--registry 137G 28K 130G 1% /srv/registry tmpfs 13G 0 13G 0% /run/user/2075
Comment Actions
Change 829747 had a related patch set uploaded (by Jelto; author: Jelto):
[operations/puppet@production] gitlab: reduce backup_keep_time to 1d
Comment Actions
@Dzahn thanks for merging the partman change and reimaging gitlab2003!
Backup keep time reduction
In the last GitLab IC meeting we discussed the future of backups for GitLab. In summary we lean towards storing less backup revisions on the production instance and rely more on bacula for backup storage. This reduces the needed disk space for the backup volume without compromising the available space for GitLab itself or the registry. We discussed this in a small round, so I'm also open to discuss this here more broadly. I prepared https://gerrit.wikimedia.org/r/829747 to reduce the backup retention to 1d. This change is not needed at the moment (we are at around 25% disk usage for backup volume after the cleanup). But this was a discussed action item.
New hardware
We also discussed that bigger disks may be needed at some point. The size model we used, which was aligned to Gerrit disk usage seems to be a little too small. GitLab accumulates more data, especially for CI. So we have to reach out to DC Ops with the following topics, especially with current lead times in mind:
- Is it possible to add more/bigger disks to the existing GitLab machines?
- Is there time for working on the GitLab machines in eqiad and codfw this year?
- Are entirely new hosts needed to get more disk space? Are there standards with more than 2x800GB SSDs?
Comment Actions
Change 831083 had a related patch set uploaded (by Jelto; author: Jelto):
[operations/puppet@production] gitlab: allow git user to access backup folder
Comment Actions
Backups on production gitlab1004 fail with
Errno::EACCES: Permission denied @ dir_s_mkdir - /srv/gitlab-backup/db
since Sep 08 00:00 UTC.
GitLab git user is unable to access temporary folders which are created during backup creation.
I was not able to find the reason why this is a issue now. We are using the same permissions for this backup folder for over a year now. The last GitLab update happened end of August. Backups worked after that update.
I prepared a change to allow user git to access /srv/gitlab-backup. I tested this by changing the access temporarily and backups worked again (I've done this yesterday to make sure we have a proper backup).
There are some hints in the docs that git user need access to the backup folder, but that's only mentioned in the restore.
Comment Actions
@Jelto i think this is fall out from https://gerrit.wikimedia.org/r/c/operations/puppet/+/809095 which changed the permission of that folder from git to root. when i looked into it it seemed from a high level that this would be fine, sorry i missed it. The lack of it being in puppet previously makes me thing that perhaps someone at some point just manually chown'ed git the folder
Comment Actions
@jbond thanks for the context!
I also found the following line in the puppet log:
Sep 7 11:42:31 gitlab1004 puppet-agent[934842]: (/Stage[main]/Main/File[/srv/gitlab-backup]/owner) owner changed 'git' to 'root'
Which makes more more confident that git was allowed previously and should be allowed again. I guess this permission was automatically setup when installing/bootstrapping GitLab apt package for the first time.
So then the above change should restore the previous state.
Comment Actions
I guess this permission was automatically setup when installing/bootstrapping GitLab apt package for the first time.
yes i imagine so
So then the above change should restore the previous state.
+1
Comment Actions
Change 831083 merged by Jelto:
[operations/puppet@production] gitlab: allow git user to access backup folder
Comment Actions
Backups on production gitlab1004 are fixed again with https://gerrit.wikimedia.org/r/831083.
The puppet run reported
Notice: /Stage[main]/Gitlab::Backup/File[/srv/gitlab-backup]/owner: owner changed 'root' to 'git'
And a manually triggered backup was successful.
Thanks again @jbond for reaching out!
Comment Actions
Change 829747 merged by Jelto:
[operations/puppet@production] gitlab: reduce backup_keep_time to 1d
Comment Actions
Change 875309 had a related patch set uploaded (by Jelto; author: Jelto):
[operations/puppet@production] gitlab: stop using "latest" backup name
Comment Actions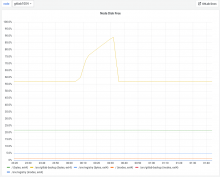
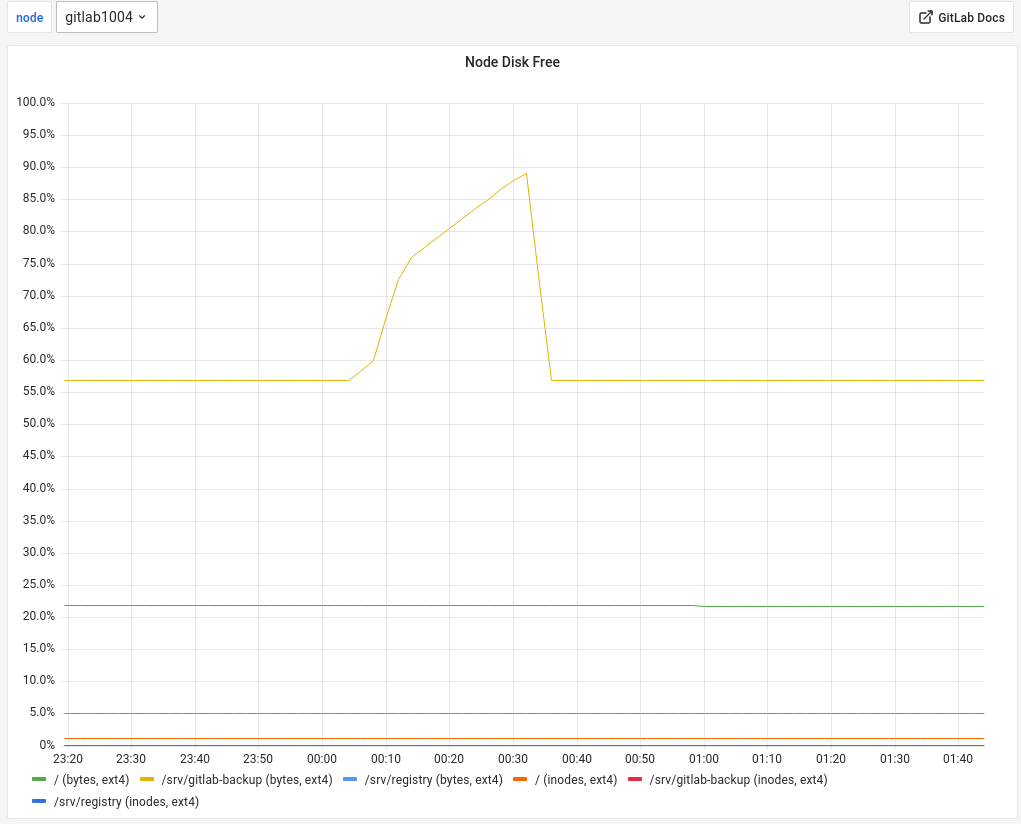
I picked up the GitLab backup task again because we hit around 90% disk usage on the GitLab backup volume during backup creation:
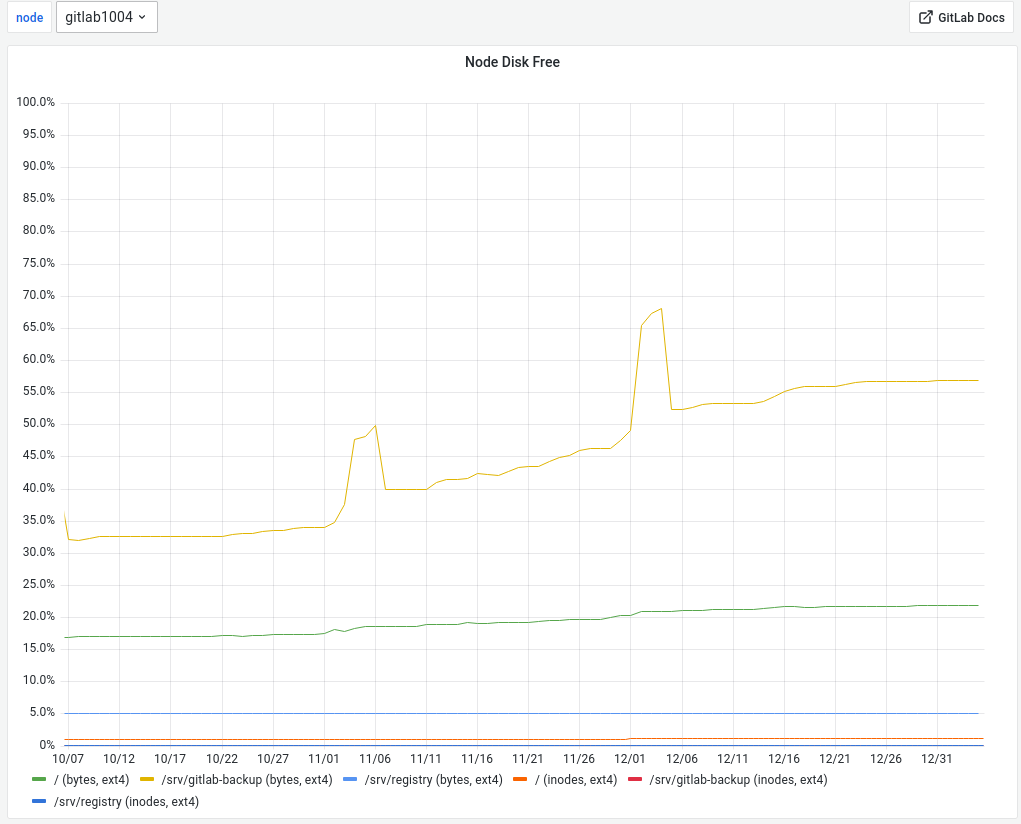
We are also slowly filling up the backup volume again with growing backups:
So I merged https://gerrit.wikimedia.org/r/829747 to reduce the backup keep time to 1d. I also verified one more time restore from bacula works with older backups.
I also opened https://gerrit.wikimedia.org/r/875309 to stop using "latest" backup names. With only one backup, we don't need all that logic for identifying and copying around the latest backup. This should also free more disk space on the backup volume and simplify the backup and restore process.
Comment Actions
GitLab backups on gitlab1004 failed again because the last two software upgrades (T327230 and T326815) created additional backups and caused a full disk.
I triggered a full backup manually on gitlab1004 using systemctl start full-backup.
I triggered a rsync to replicas using
systemctl start rsync-data-backup-gitlab1003.wikimedia.org.service systemctl start rsync-data-backup-gitlab2002.wikimedia.org.service
And triggered a restore on both replicas:
systemctl start backup-restore
Note all of that commands can be found in the GitLab cheat sheet
I'm hoping to test and deploy the first refactoring of the backup config somewhere next week: https://gerrit.wikimedia.org/r/q/875309 to address some of this problems a little bit more long term.
Comment Actions
Change 875309 merged by Jelto:
[operations/puppet@production] gitlab: stop using "latest" backup name
Comment Actions
I merged the change above and cleaned all the latest directories on all GitLab hosts.
A manual run of backup, sync and restore was successful. Files in GitLab backup folder look good so no duplicate/old files should end up in bacula.
There is one issue with the current rsync configuration. rsync run will remove the restore script (because we use rsync --delete and the script is not installed on production instance). The script will get recreated after the next puppet run. I'll try to find a solution of either excluding those files in rsync or move them somewhere else.
Comment Actions
Please make sure bacula contains all files it should in the next full backup- e.g. by attempting a recovery and checking the files are still there.
Comment Actions
Change 882704 had a related patch set uploaded (by Jelto; author: Jelto):
[operations/puppet@production] gitlab: exclude shell scripts and other backups from rsync jobs
Comment Actions
Change 882704 merged by Jelto:
[operations/puppet@production] gitlab: exclude shell scripts and other backups from rsync jobs
Comment Actions
Thanks for keeping an eye on that! I restored the most recent backup for gitlab1004 from bacula and it looks as expected. Bacula contains a data and config backups, without latest folders. Currently it contains two config backups because one backup was created inter-day during tests (so younger than 24h). The next bacula backup should contain a single config backup. Although the size of the config backup can be neglected.
root@gitlab1004:/var/tmp/bacula-restores# tree
.
├── etc
│ └── gitlab
│ └── config_backup
│ ├── gitlab_config_1674483181_2023_01_23.tar
│ └── gitlab_config_1674518408_2023_01_24.tar
└── srv
└── gitlab-backup
├── 1674518667_2023_01_24_15.7.5_gitlab_backup.tar
└── gitlab-backup.shWith the new configuration the backup and restore got less complex and we save disk space on GitLab hosts. Furthermore time for restore the replicas was also reduced by removing a mandatory puppet run after the restore.
Comment Actions
jynus opened https://gitlab.wikimedia.org/repos/sre/wmfbackups/-/merge_requests/3
WIP GitLab backups
Comment Actions
Change 819109 abandoned by Jcrespo:
[operations/software/wmfbackups@master] Enable gitlab backup type for wmfbackups
Reason:
Migrated to gitlab at https://gitlab.wikimedia.org/repos/sre/wmfbackups/-/merge_requests/3 and https://gitlab.wikimedia.org/repos/sre/wmfbackups/-/commit/f01152190d97c2a69a772c7facea120c9a481106