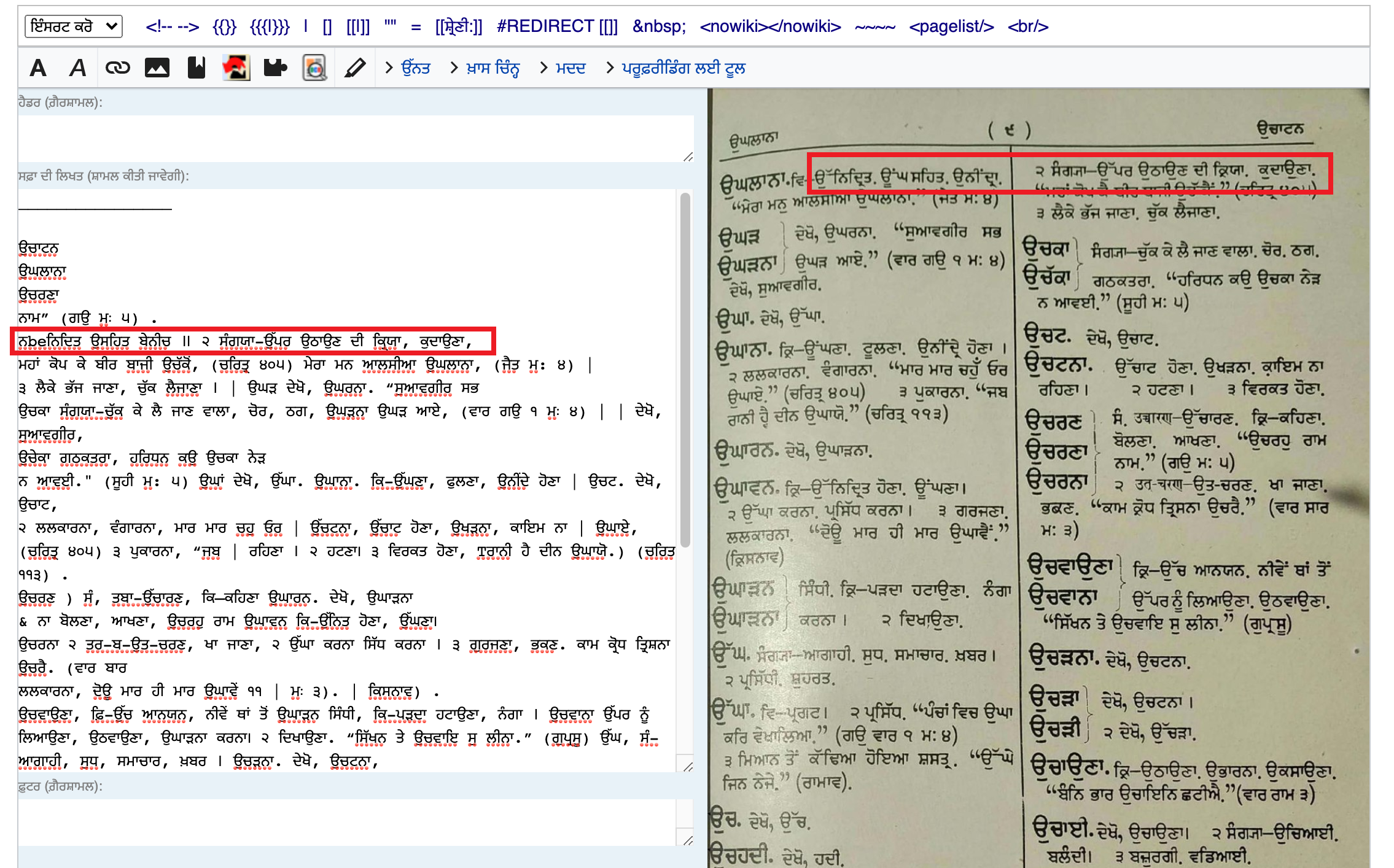
As a product manager, I want engineers to explore if it is possible to support columns in OCR-ed text, so we can determine what solutions we can implement (if any), which would vastly improve the user experience and output of Wikisource editors.
Examples with Indic OCR:
- https://pa.wikisource.org/w/index.php?title=%E0%A8%AA%E0%A9%B0%E0%A8%A8%E0%A8%BE:%E0%A8%AE%E0%A8%B9%E0%A8%BE%E0%A8%A8_%E0%A8%95%E0%A9%8B%E0%A8%B8%E0%A8%BC_%E0%A8%AD%E0%A8%BE%E0%A8%97_1.pdf/19&action=edit&redlink=1 -
- https://pa.wikisource.org/w/index.php?title=%E0%A8%AA%E0%A9%B0%E0%A8%A8%E0%A8%BE:%E0%A8%AE%E0%A8%B9%E0%A8%BE%E0%A8%A8_%E0%A8%95%E0%A9%8B%E0%A8%B8%E0%A8%BC_%E0%A8%AD%E0%A8%BE%E0%A8%97_1.pdf/30&action=edit&redlink=1
Wikimedia OCR:
Acceptance Criteria:
- Investigate the technical reason/root cause of why OCR tools are not properly handling multiple columns (i.e., displaying text in one column)
- Investigate if there is a technical solution to properly format OCR-ed texts with multiple columns
- If there is a solution, share findings with team as well as estimated scope of work
- This investigation can focus on Wikimedia OCR, but it may be helpful to do some basic poking around Basic OCR & IndicOCR as well to get a more comprehensive sense of how the issue is being handled by different OCR tools at the moment
Visual Examples: