Acceptance Criteria:
- Determine how to fix the issue in Wikimedia OCR in which lines are formatted to end at the last word of the line in the original text rather than the last word of the line that would be appropriate for the new text
- Note: This should not apply to poems
- Note: Indic OCR seems to be handling the issue better. Maybe we can look into what that OCR tool is doing.
- Wouldn't it be possible to disable line breaks after the text is validated?
URL of example: https://en.wikisource.org/w/index.php?title=Page:Myths_of_Mexico_and_Peru.djvu/22&action=edit
Visual Example:
Issues when using Wikimedia OCR:
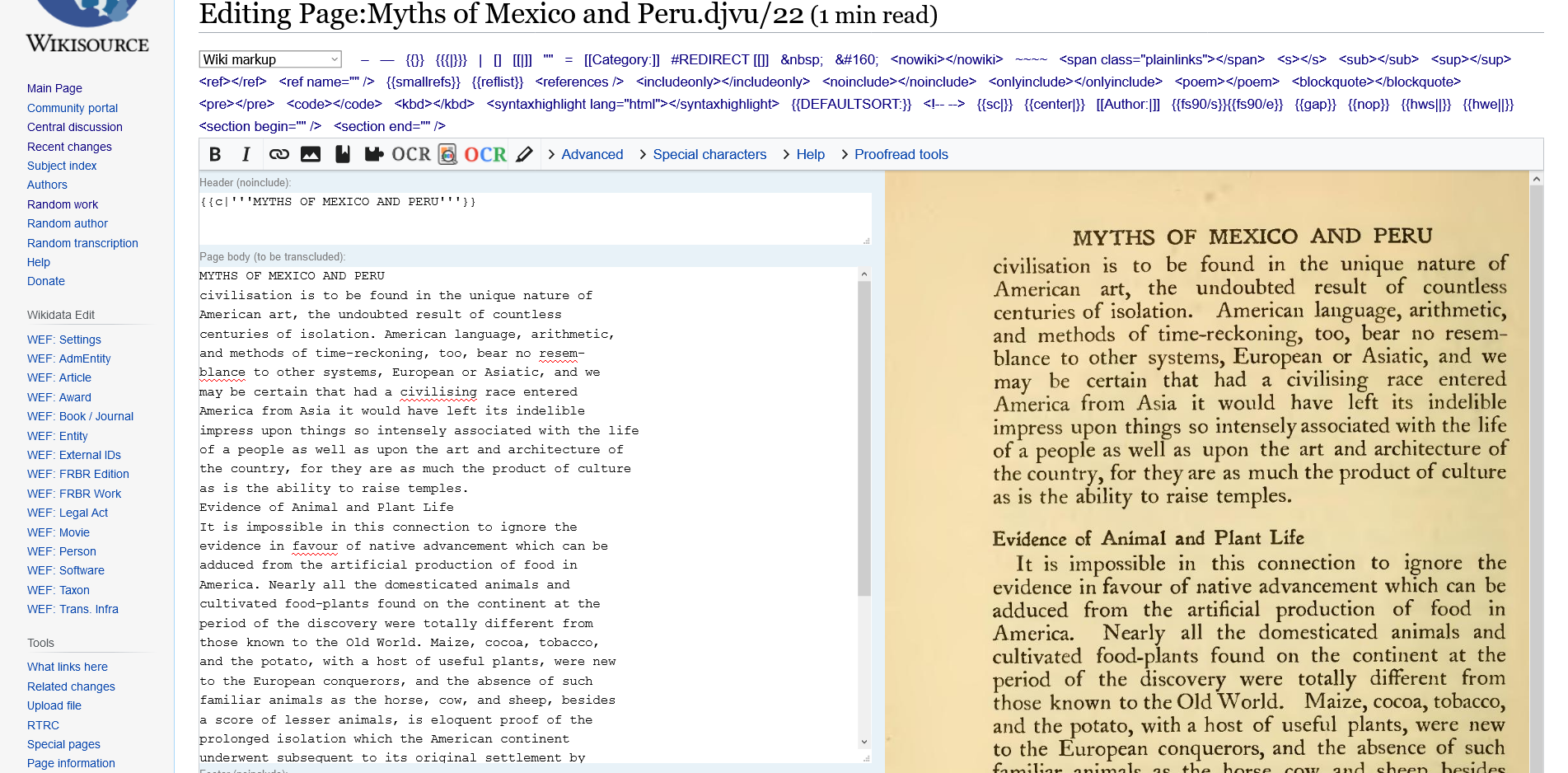
Working properly with Indic OCR: