I recently started receiving notification alarms from Icinga for contint2001.mgmt/SSH):
Notification Type: PROBLEM Service: SSH Host: contint2001.mgmt Address: 10.193.2.250 State: CRITICAL
That seems rather recent:
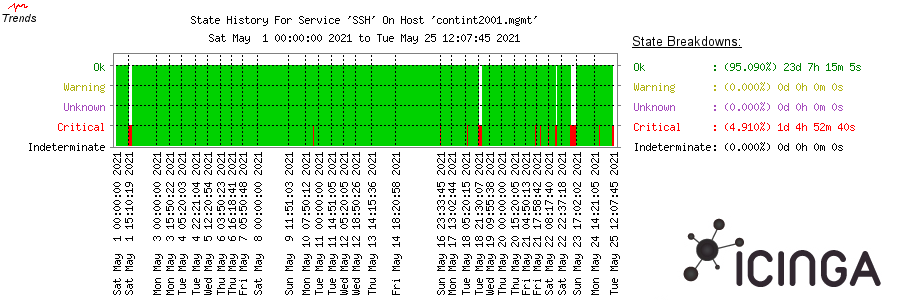
https://icinga.wikimedia.org/cgi-bin/icinga/histogram.cgi?host=contint2001.mgmt&service=SSH
Kunal stated that it might be the codfw network flapping somehow but we could not find a related task.
| status | host | version | New version | BIOS version | New BIOS version | Comments |
| [x] | ores2005.mgmt | 2.40 | 2.81 | |||
| [x] | gerrit2001.mgmt | 2.21 | 2.81 | |||
| [x] | ms-fe2006.mgmt | 2.40 | 2.81 | |||
| [x] | wdqs2001.mgmt | 2.30 | 2.81 | |||
| [x] | wdqs2002.mgmt | 2.30 | 2.81 | |||
| [] | logstash2021.mgmt | offline | ||||
| [] | logstash2022.mgmt | offline | ||||
| [x] | contint2001.mgmt | 2.21 | 2.81 | 2.3.4 | 2.12 | Reset IDRAC |
| [x] | mw2253.mgmt | 2.40 | 2.81 | 2.3.4 | 2.12 | Reset IDRAC |
| [x] | mw2255.mgmt | 2.40 | 2.81 | 2.3.4 | 2.13 | Reset IDRAC |