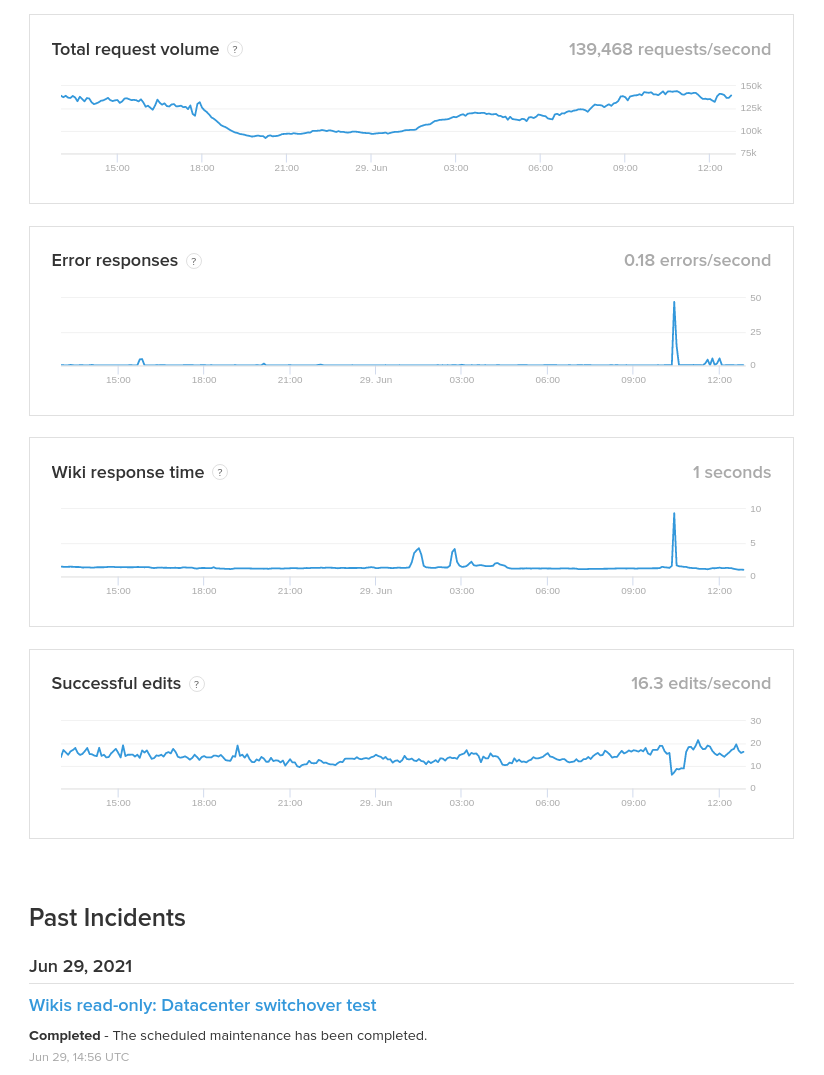
There's a great benefit in displaying a few high-level timeseries metrics on our status page: it means that semi-technical users can tell that something is amiss even before SRE has had a chance to manually update the page with an incident notification.
After discussion we selected four metrics:
- total edge HTTP requests per second
- Number of appserver error (5xx) responses per second
- Average* latency for all appserver requests
- Number of successfully-saved wiki edits
These metrics can be summarized in a fairly self-explanatory way, will reflect many different kinds of possible outages, and are also things that most users are likely to care about.
In the future we might also want to include RUM latency data from a broad swath of users, possibly using it to replace appserver latency, possibly adding it as another graph.
Another likely addition is the rate of incoming NEL reports of certain types (and with a low age field). In recent networking-related outages they've been a good signal of trouble and we page on them now, so why not present cleaned-up data to users as well?
However we should also strive to keep the number of metrics to a minimum: the page should be readable at a glance and not overwhelming. I think six plots is an absolute upper bound.
The plan is to upload these metrics by a simple Python utility we wrote, named statograph, running on both alerting hosts via a systemd timer. It will query Prometheus & Graphite and push data to the Statuspage.io API.
(*: Yes, average latency; percentiles are tricky to explain to the uninitiated, and I believe that skewing displayed data towards the long tail is actually beneficial in this case.)
- Code review of statograph
- Puppetization and deployment as a systemd timer on alert1001/alert2001 hosts
- Basic alerting provided by systemd unit failure (from statograph's exit code)
- Add feature to statograph upload_metrics to export a Prometheus node_exporter textfile of the most_recent_data_at timestamp for each Metric, plus some basic IRC alerting on those timestamps being too far behind current time