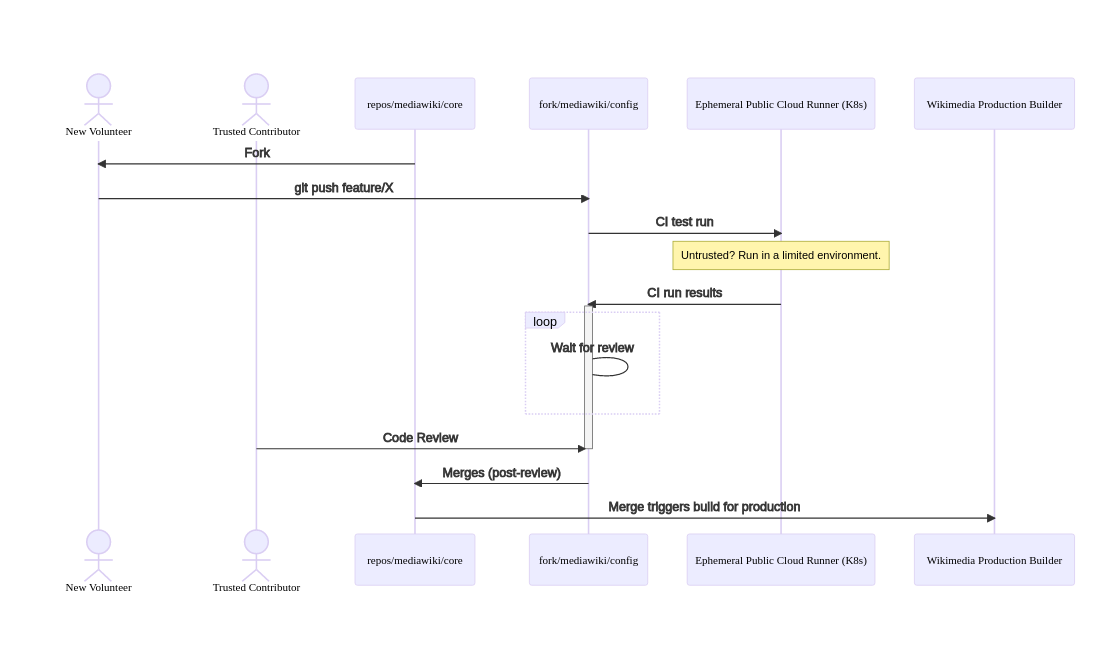
I'm filing this as a placeholder followup from T292094, where I mentioned:
After discussion today with SRE folks, we also expect to build:
…
- Untrusted and variously constrained runners, probably on a 3rd-party host, to handle user-level projects and merge requests from forks.
- This will be experimental, and a bunch of details will need to be worked out.
Open problems:
- provision managed Kubernetes cluster on Digital Ocean
- configure Kubernetes executor using gitlab/gitlab-runner helm chart
- create ci-pipeline for both above (repos/releng/gitlab-cloud-runner/)
- reduce timeout for CI jobs to 10m for Cloud Runners
- reduce amount of CPU/MEM available to CI jobs
- activate autoscaling for Kubernetes Node pool
-
create quota for available CI minutesnot possible in free tier. - create some kind of alerting or monitoring
- restrict allowed images?
- open Cloud Runners instance wide