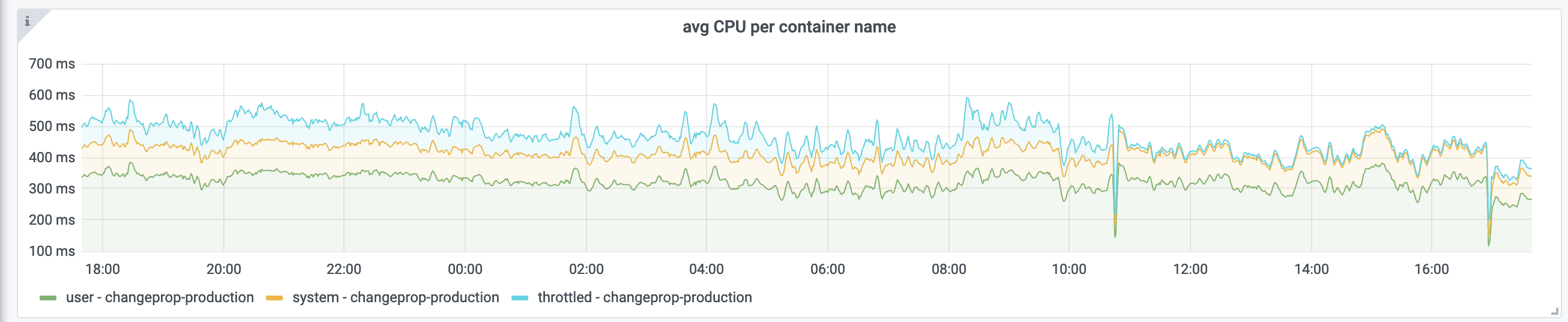
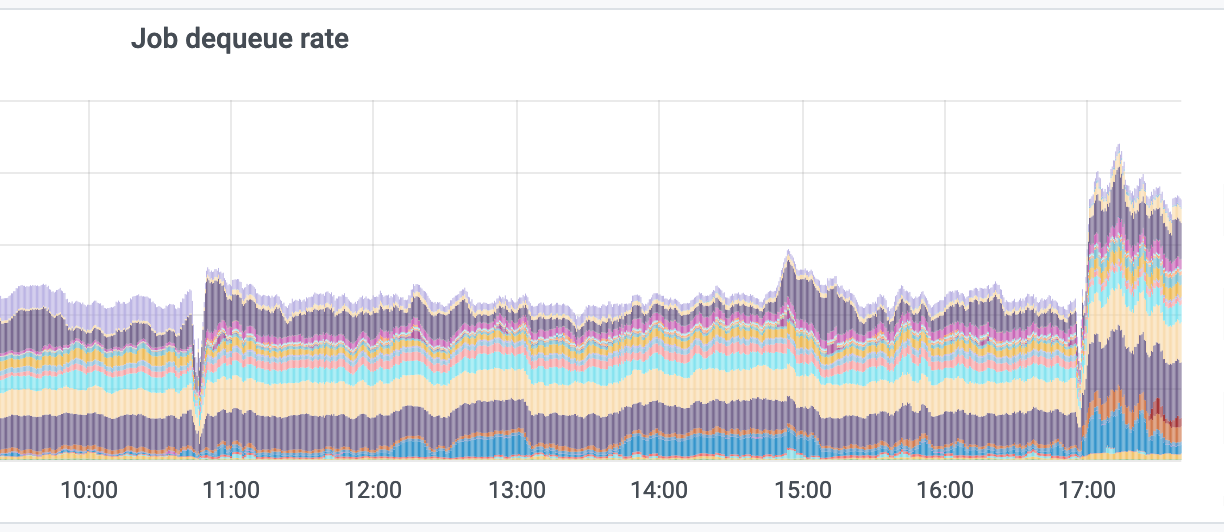
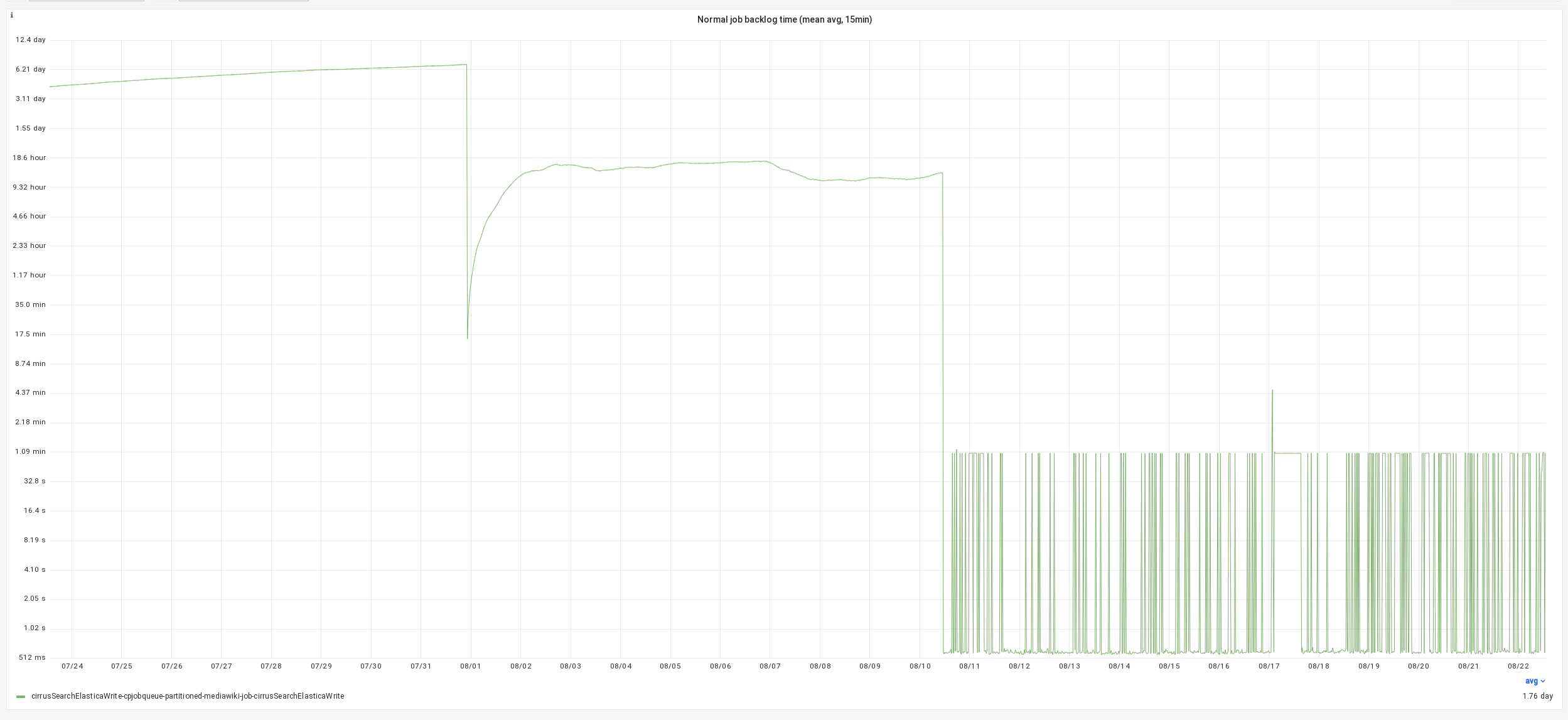
CirrusSearchElasticaWrite jobs have been backlogging recently. In T266762 the same issue was addressed and concurrency for the job was increased to 100 per partition, 300 overall. Job concurrency graphs, added to JobQueue Job dashboard while investigating this issue, show the job achieving a typical concurrency of ~25 per partition with a backlogged queue. We have disabled some important maintenance operations on the cirrus elasticsearch clusters to reduce the backlog, but these cannot stay turned off forever.
While looking into this I also noticed that several other jobs are backlogged currently, unclear but plausible they are experiencing a similar issue:
| job | normal job backlog time (mean avg, 15min) |
| wikibase-addUsagesforPage | 4.93 days |
| refreshLinks | 3.27 days |
| cirrusSearchElaticaWrite | 12.9 hours |