August 1 2024: For a full update on Newspapers.com please see T322916#10036209
Current issues
- We do not currently seem to have access to some Publisher Extra content
- Users cannot log in via Ancestry
- Users cannot log in via Facebook
- Users cannot register a new account via Email
Past issues
Cloudflare is preventing access. Users get stuck at www.newspapers.com needs to review the security of your connection before proceeding.
Users currently cannot log out of their account while proxied, or log in via Ancestry.
This change has now been deployed, however we are seeing some access issues. Some users cannot retrieve search results, and logging in to accounts sometimes doesn't work.
Users can't login as they see the following error:
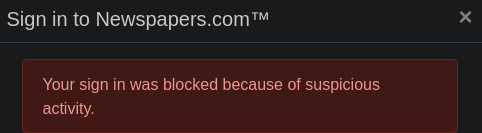
Newspapers.com fixed the initial issue here, which was enabling reCaptcha, however we're now getting a slightly different error about an "invalid domain key". We should be able to fix this issue, and are investigating.
Original task
Our existing partner newspapers.com has agreed to move to library bundle. We need to update their EZProxy configuration.
Partner id: 26 (https://wikipedialibrary.wmflabs.org/partners/26/)
Before making this change please send me a list of the user emails (privately) with active authorisations so I can let them know.

