As detailed in T301949, tools-db-1 is a new VM with Ceph storage that will become the new primary ToolsDB database.
This task is to set up tools-db-1 as a MariaDB replica that will replicate from the current primary clouddb1001. I already did that once (T301949#8554308) but after the outage in T329535 the replica is no longer in sync and needs to be recreated from scratch.
The required steps are detailed below, based on the experience of my previous attempt. EDIT: Reusing the same steps from T301949#8554308 did not work this time. I have updated the strategy, and the steps below, to use a libvirt snapshot instead of an LVM snapshot. See the comments below for more details.
Step 2 will set MariaDB in read-only mode, and step 3 will stop it completely, so remember to write a message in IRC (#wikimedia-cloud) and send an email to cloud-announce@lists.wikimedia.org to inform people of the brief ToolsDB outage (expected to last about 2 minutes in total).
- In the Horizon web interface (project: clouddb-services), create a new 4TB Cinder volume (type: high-iops) and attach it to clouddb1001. Create a partition and an ext4 filesystem.
fdisk /dev/vdb # use "g" to create the partition table, then "n" to create a single partition mkfs.ext4 /dev/vdb1
- Flush data to disk and take note of the current GTID. If the "FLUSH TABLES" command hangs for more than a few seconds, open a separate mysql session, and manually kill (using KILL {id}) any running query (find the queries to kill using SELECT * FROM INFORMATION_SCHEMA.PROCESSLIST WHERE command != 'Sleep' AND state not like 'Waiting%';).
FLUSH TABLES WITH READ LOCK; SELECT @@global.gtid_binlog_pos; #store the result somewhere safe, it will be needed in step 9
- Stop MariaDB on clouddb1001 to ensure the snapshot we are going to take in the next step is "clean". I tried taking a snapshot without stopping MariaDB and that meant I could not load it cleanly on a new instance running a newer version of MariaDB (see T301949#8565151).
systemctl stop mariadb
- From the hypervisor cloudvirt1019, create a libvirt snapshot of the virtual disk attached to clouddb1001 (instance name i-000045d4) and mount it to /mnt-snapshot.
virsh domblklist i-000045d4 #take note of the virtual disk filename virsh snapshot-create-as --disk-only --domain i-000045d4
mkdir /mnt-snapshot
apt install libguestfs-tools
guestmount -a {disk_filename} -i --ro /mnt-snapshot- Restart mariadb on clouddb1001, and enable write mode (this instance of mariadb is configured to start in read-only mode for extra safety).
systemctl start mariadb systemctl start prometheus-mysqld-exporter #for some reason this must be restarted manually SET GLOBAL read_only = 0;
- Detach the destination Cinder volume (tools-db-1) from clouddb1001 and attach it directly to the hypervisor using rbd map, then mount it to /mnt-cinder.
rbd map eqiad1-cinder/volume-9583ba88-b836-4233-8e51-6213d403f9c7 mkdir /mnt-cinder mount /dev/rbd0p1 /mnt-cinder/
- Copy the snapshot to the attached Cinder volume.
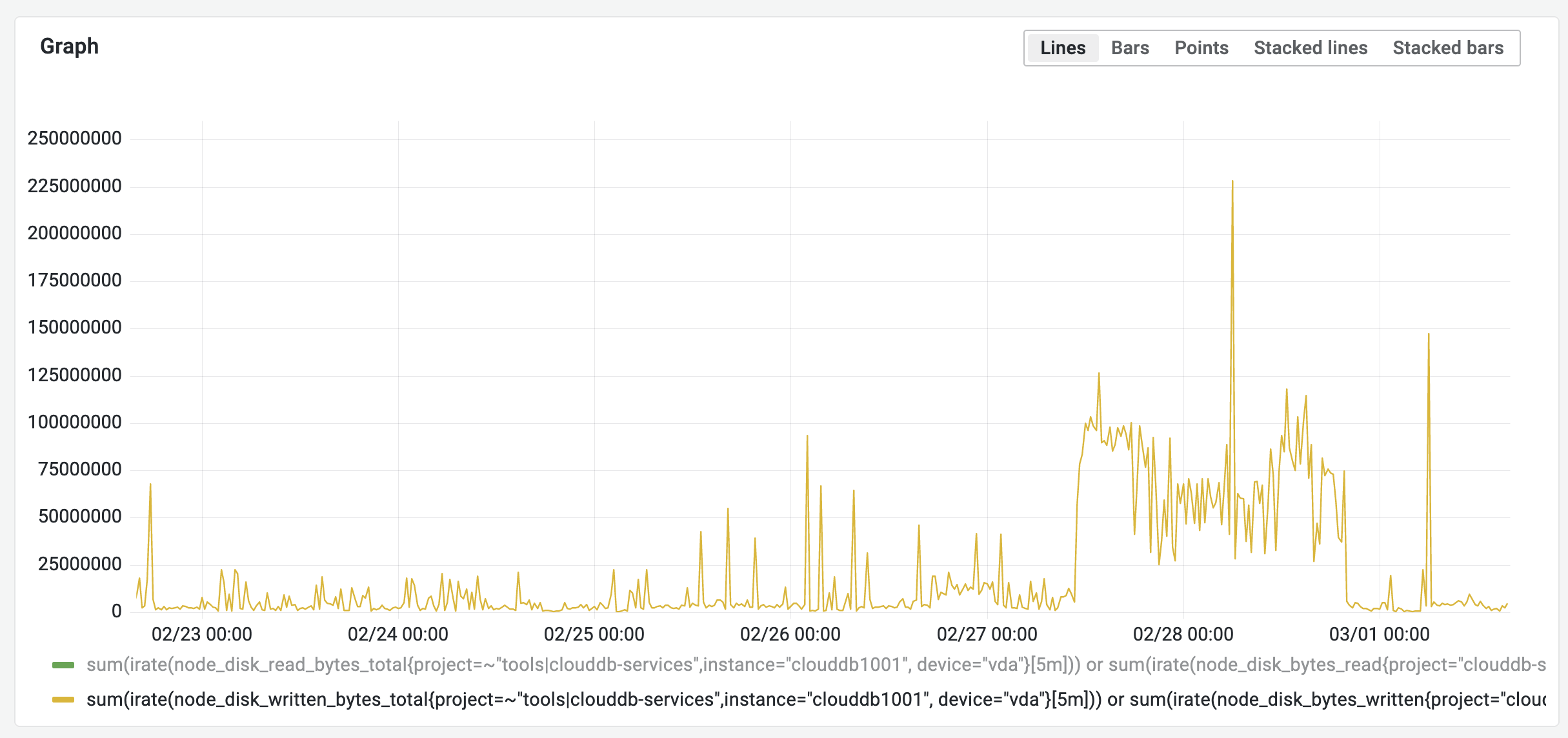
# make sure to run this in a screen/tmux session as it will take a few hours rsync -a --info=progress2 /mnt-snapshot/srv/labsdb/ /mnt-cinder/
- Unmount both the snapshot and the Cinder volume.
guestunmount /mnt-snapshot umount /mnt-cinder rbd unmap /dev/rbd0
- From a shell in a cloudcontrol* host, transfer the volume to the tools project.
export OS_PROJECT_ID=clouddb-services
openstack volume list
openstack volume transfer request create {volume-id}
export OS_PROJECT_ID=tools
openstack volume transfer request accept --auth-key {auth-key} {transfer-id}- From the Horizon web interface (project: tools), create a Cinder volume snapshot (for extra safety in case something goes wrong in the following steps) and attach the volume to tools-db-1. Then from a shell in tools-db-1 make sure that MariaDB is not running, mount the volume, and start MariaDB.
systemctl stop mariadb mount /dev/sdb1 /srv/labsdb chown -R mysql:mysql /srv/labsdb/ systemctl start mariadb
- Run mysql_upgrade to upgrade the data format from MariaDB 10.1 to 10.4
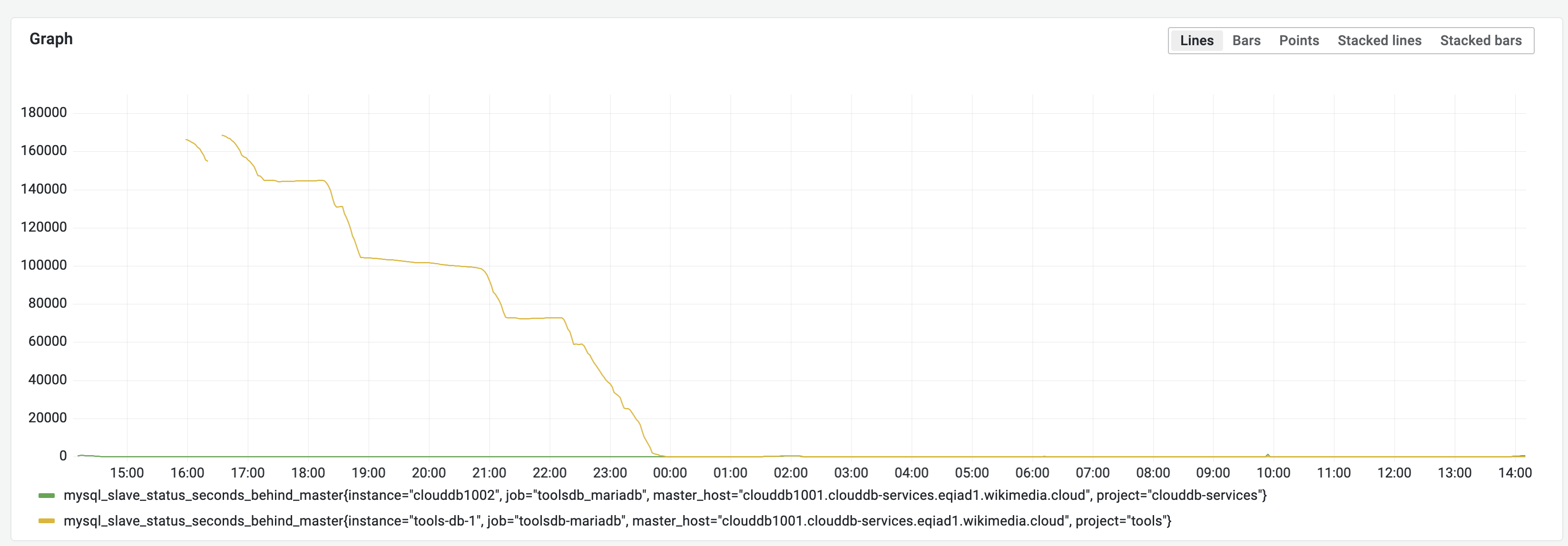
- Check with journalctl -u mariadb -f that there is no error. Then start the replication, excluding two databases: linkwatcher (that will be migrated separately in T328691) and mw (that will be migrated separately in T328693).
SET GLOBAL replicate_wild_ignore_table="s51230__linkwatcher.%,s54518__mw.%";
SET GLOBAL gtid_slave_pos = "{the value from step 2}"
SET GLOBAL innodb_flush_log_at_trx_commit=2;
CHANGE MASTER TO
MASTER_HOST='clouddb1001.clouddb-services.eqiad1.wikimedia.cloud',
MASTER_USER='repl',
MASTER_PASSWORD='{the password for the repl user},
MASTER_USE_GTID=slave_pos;
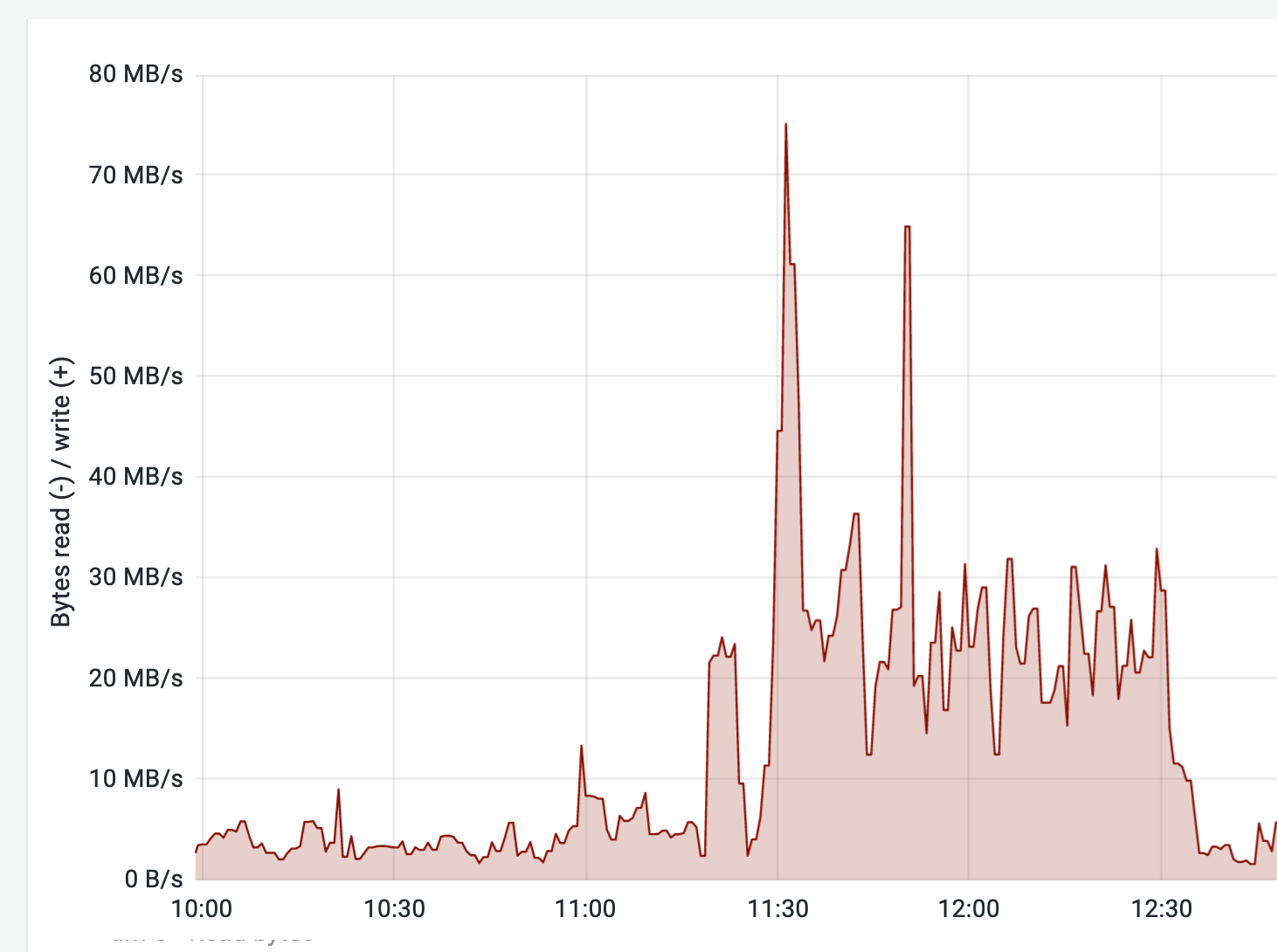
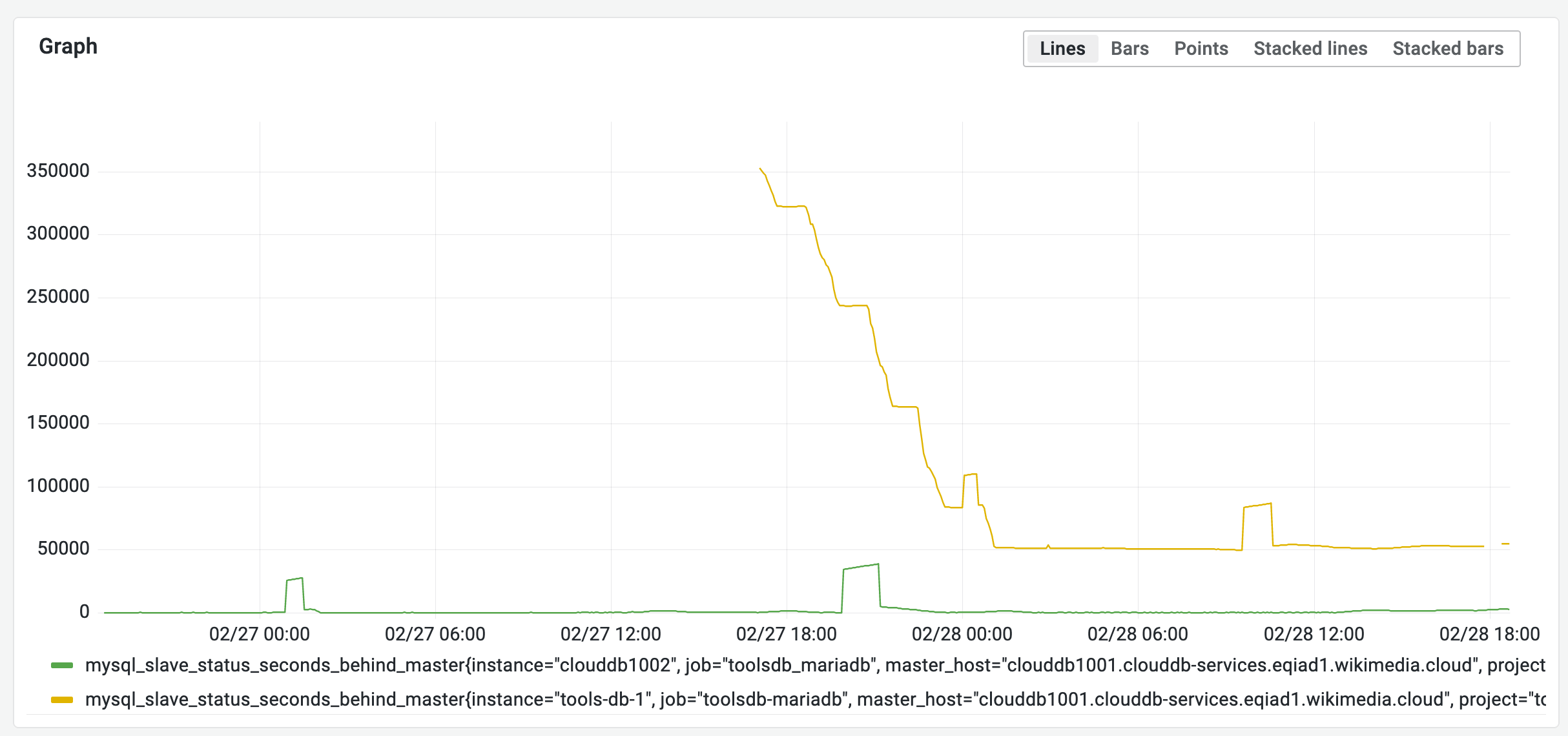
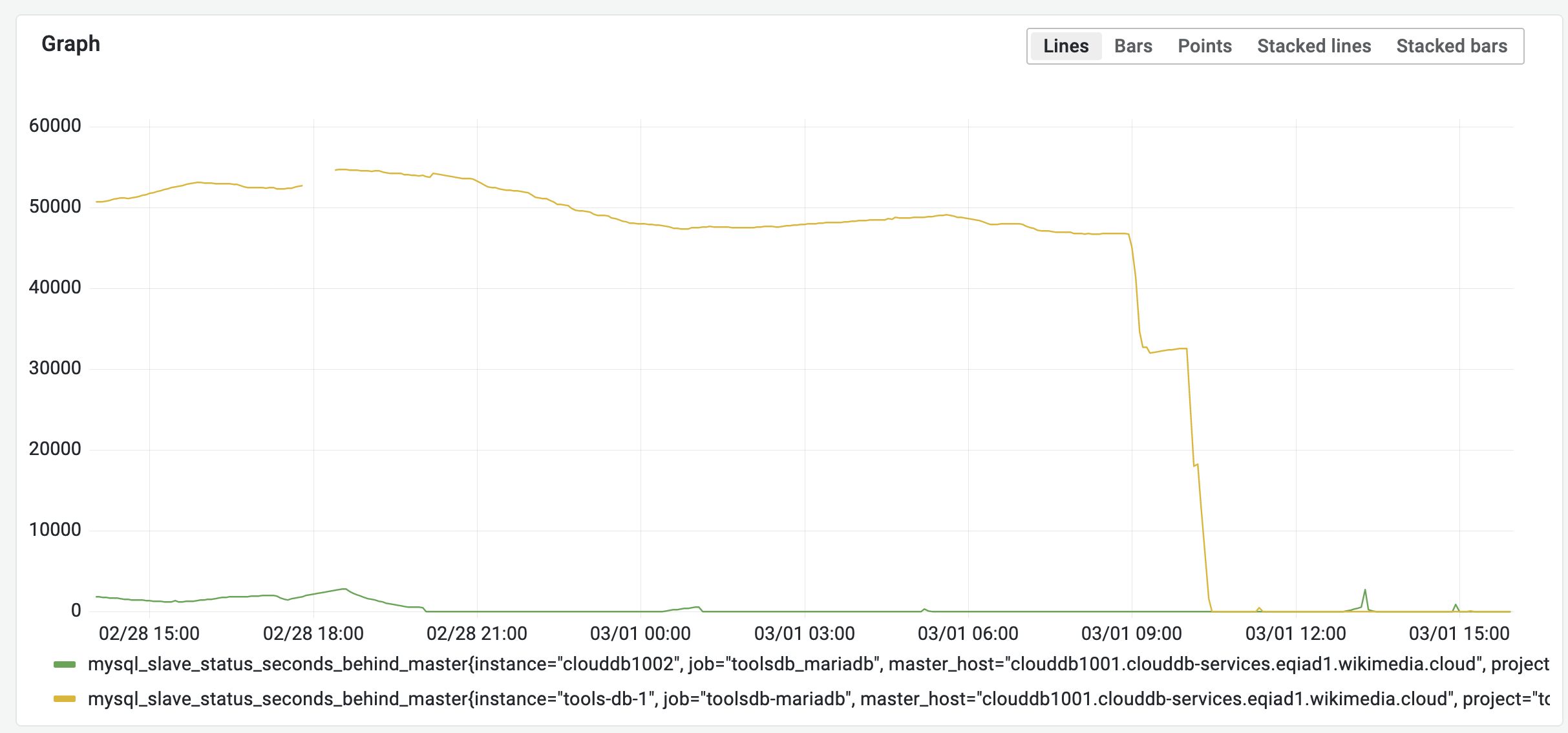
START SLAVE;- Using SHOW SLAVE STATUS\G or the ToolsDB Grafana dashboard, check that the replication lag (Seconds_Behind_Master) decreases to zero.