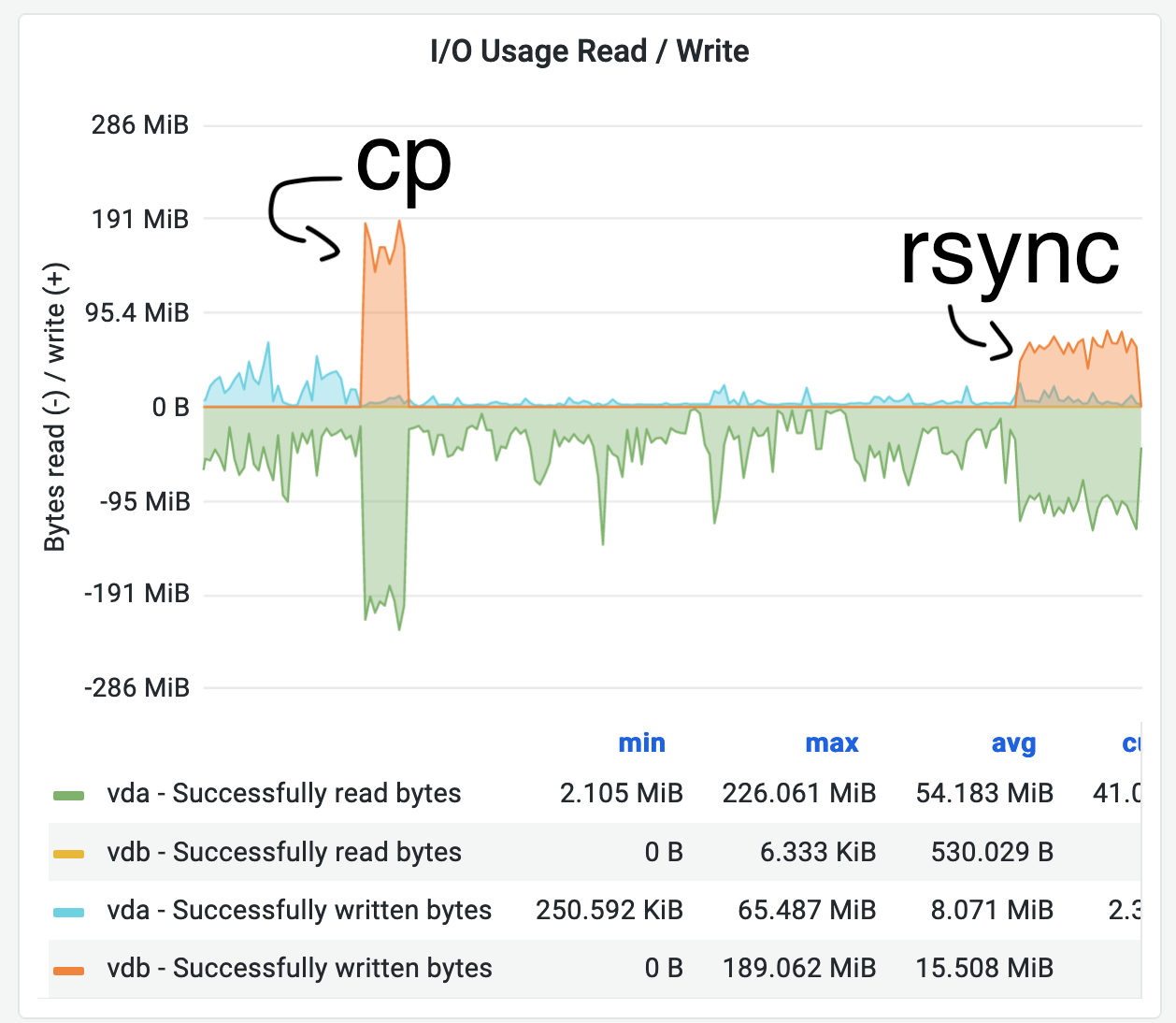
We can't really just keep pushing this to the future.. ToolsDB is still on Stretch + MariaDB 10.1 and needs to be upgraded to more modern things, which I believe currently means Bullseye and MariaDB 10.4.
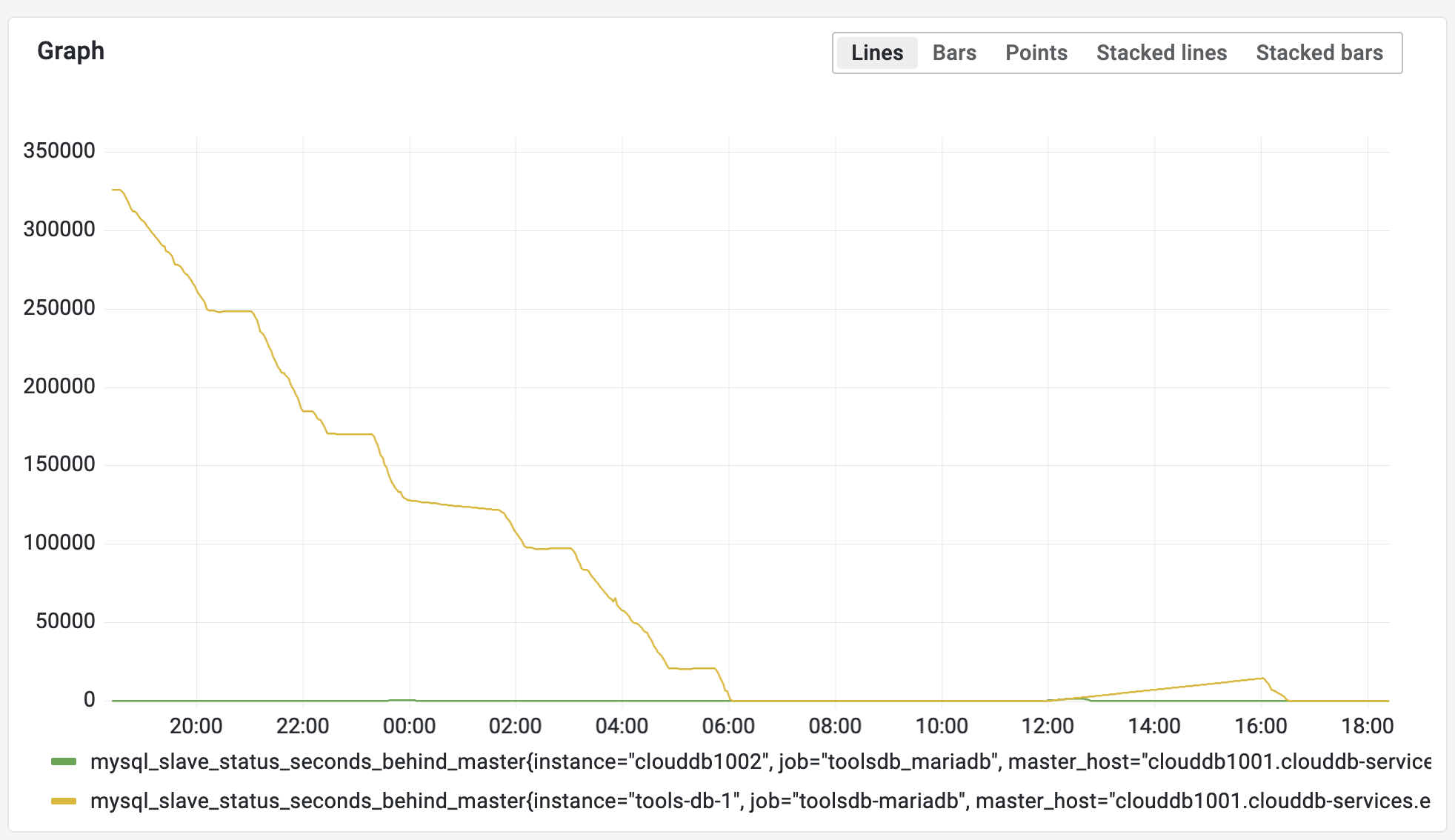
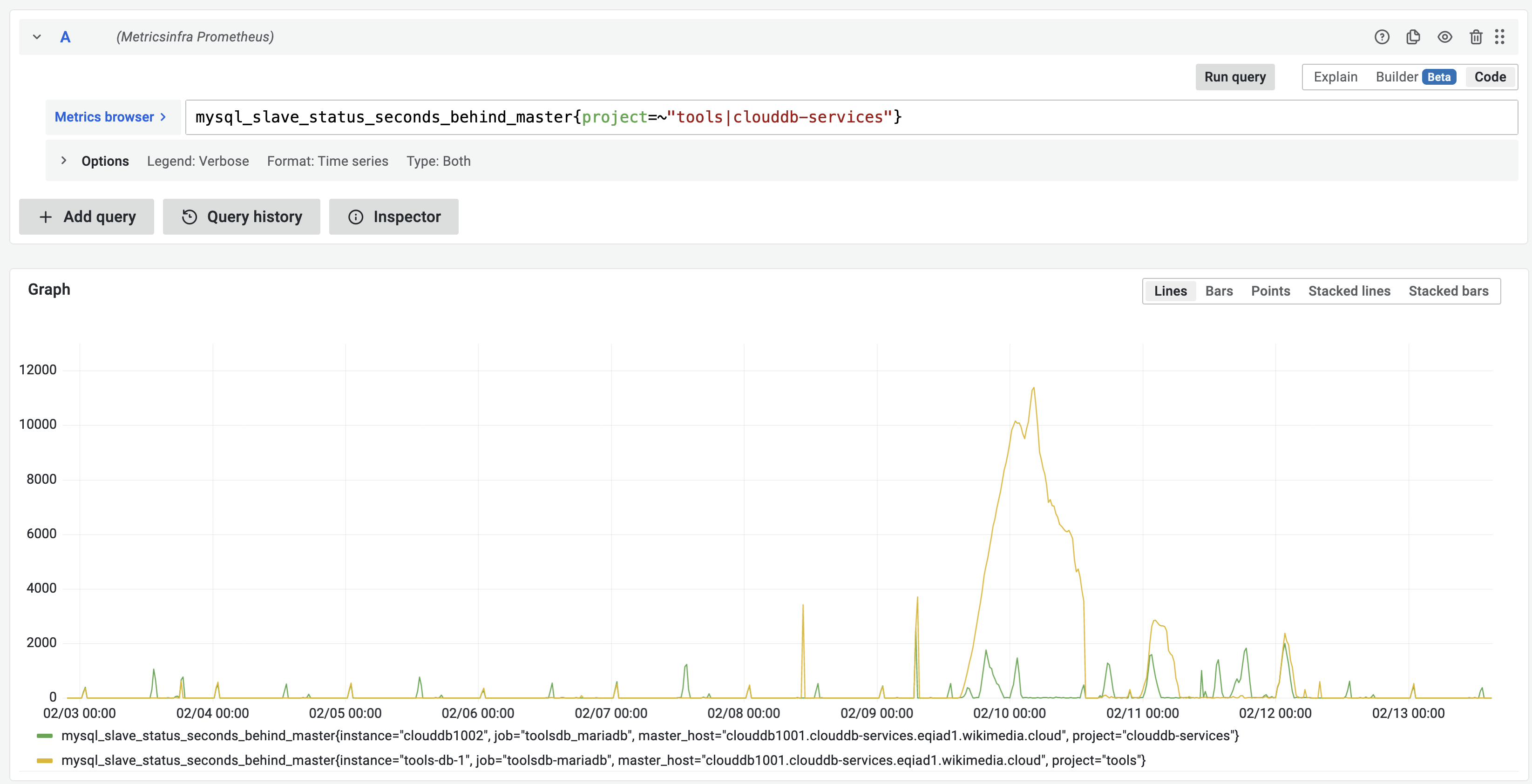
ToolsDB is currently running on two dedicated localdisk hypervisors. Can we temporarily add a third one to make the migration easier? I was thinking of maybe using the replica (once recovered from T301951) to clone a new 10.4 instance without causing any service impact to the primary.
We have two upgrades that need to happen here: the hypervisors (cloudvirt1019 and 1020) need to be upgraded to Bullseye, and the VMs (clouddb100[1-4]) need to be upgraded to at least Buster and, ideally, also Bullseye.
Clouddb1001 and 1004 are on cloudvirt1019
Clouddb1002 and 1003 are on cloudvirt1020
Clouddb1001 is the (partial) toolsdb database, with (partial) replica clouddb1002
Clouddb1004 and Clouddb1003 are postgres servers and I'm not entirely sure what's on them. For these 2 servers, refer to T323159 instead.