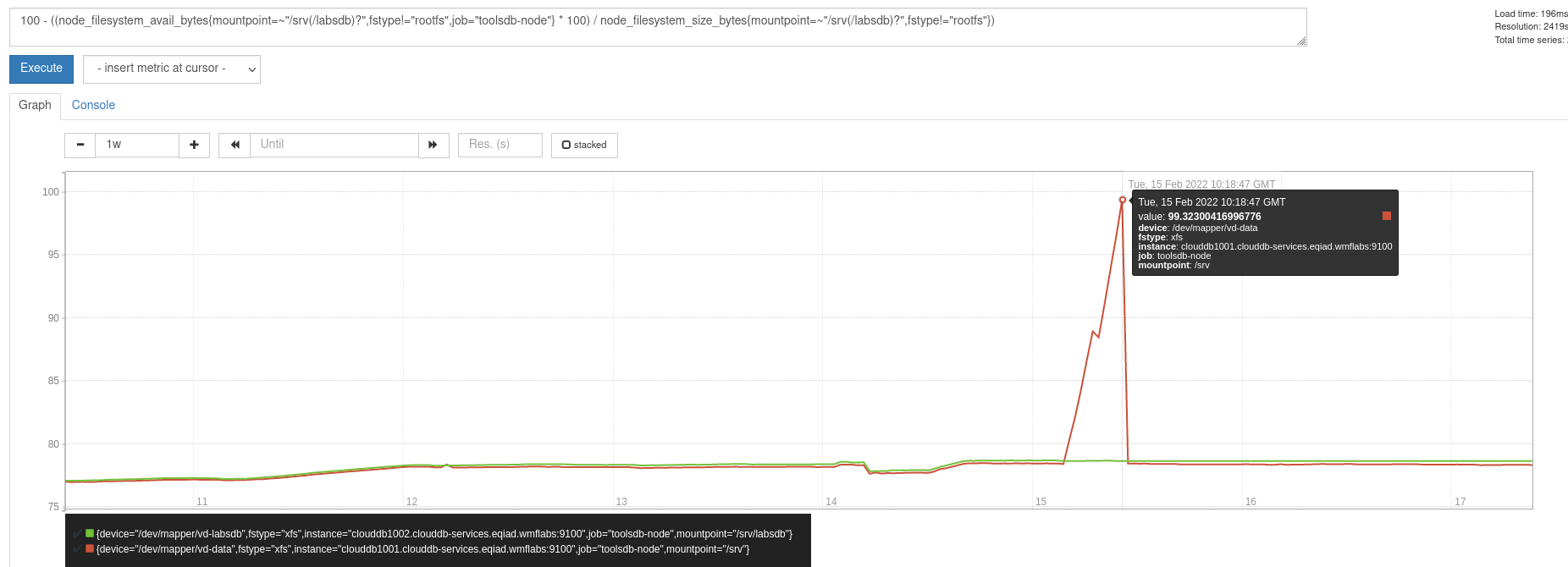
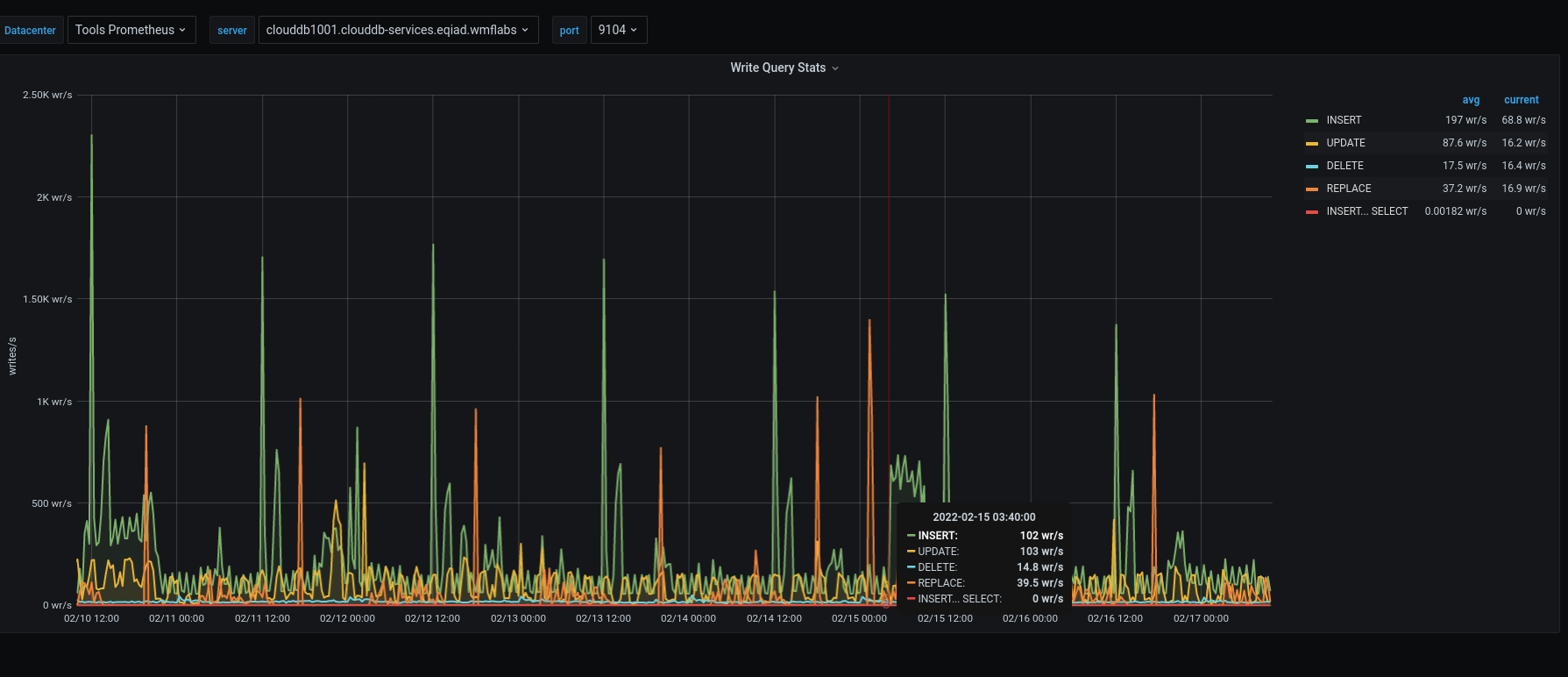
ToolsDB replication to clouddb1002.clouddb-services.eqiad1.wikimedia.cloud broke on 2022-02-15:
MariaDB [(none)]> show slave status\G
*************************** 1. row ***************************
[...]
Last_IO_Errno: 1236
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'binlog truncated in the middle of event; consider out of disk space on master; the first event 'log.275246' at 15499031, the last event read from 'log.275246' at 15499142, the last byte read from 'log.275246' at 15499161.'
[...]and clouddb1001 indeed somehow went out of disk space: