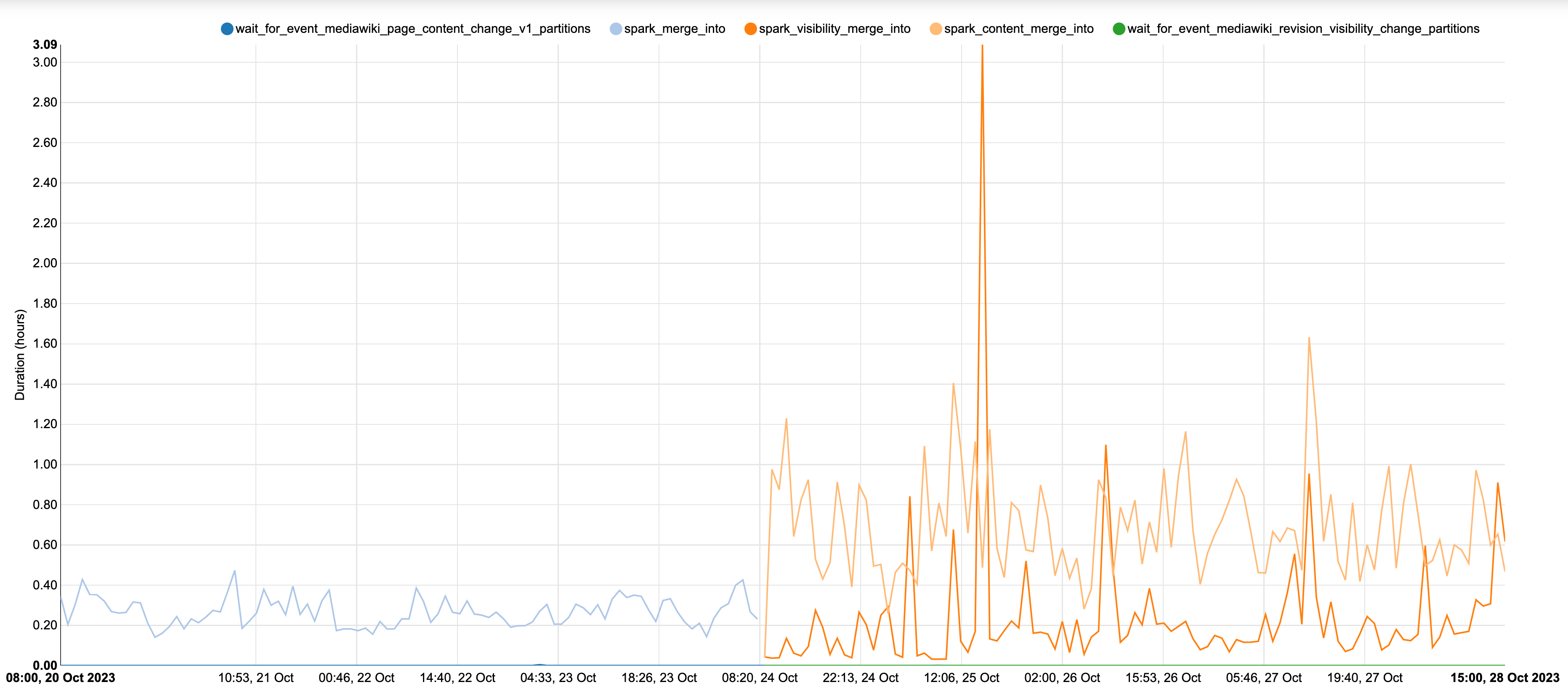
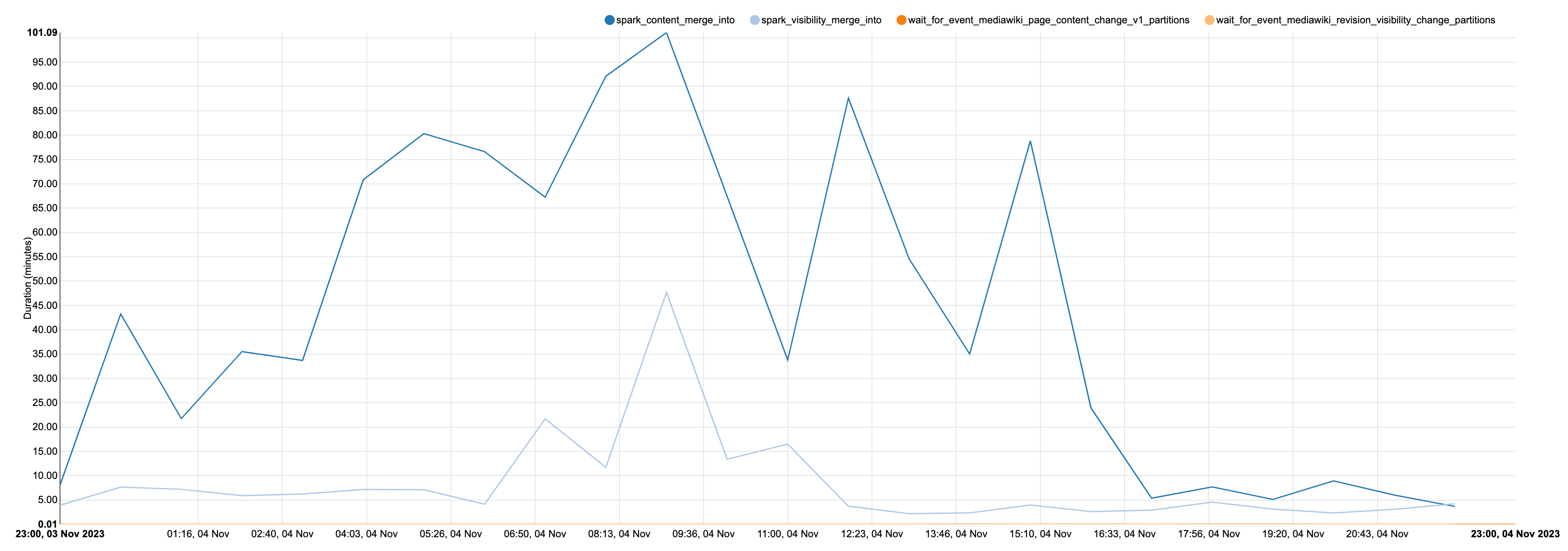
On T335860, we implemented a pyspark job that runs a MERGE INTO that transforms event data into a table that will eventually have all the mediawiki revision history.
Reviews of the MERGE INTO pointed at situations that should not happen, assuming that we have a properly backfilled table:
WHEN MATCHED AND s.changelog_kind IN ('insert', 'update') AND s_dt >= t.dt THEN
UPDATE SET
...
WHEN MATCHED AND s.changelog_kind = 'delete' AND s_dt >= t.dt THEN DELETE
WHEN NOT MATCHED AND s.changelog_kind IN ('insert', 'update') THEN
INSERT (
...For example, in the snippet above, we should never hit WHEN MATCHED AND s.changelog_kind = 'insert' and we should also never hit WHEN NOT MATCHED AND s.changelog_kind ='update'.
Also:
In this task we should:
- These things do happen right now, but that is because we are not backfilled, so we should wait until T340861 is complete first.
- We should run a couple queries to see if the above situations do happen after backfill.
- Build a mechanism to log these situations. It can be as simple as having an extra column in the target table where we log the error. Or fancier.
- For partial correctness, we should merge the two current events Airflow jobs into one and force ordering.
- Add one more column to separate visibility updates from regular update, so that visibility changes are idempotent.