Tpimh reports
In English wiki bulbs show the beginning of the article with stripped text in brackets (e.g. dates of birth and death, alternative names), but in Russian wiki it is shown. Sometimes it is the only information that is shown if the text in brackets is long enough. Kind of not usefull at all.
This seems to be a prolific problem at Ruwiki, (screenshots from [[Main page]] links to these articles: Луций Сергий Катилина, and Гай Саллюстий Крисп, and Этрурия.)
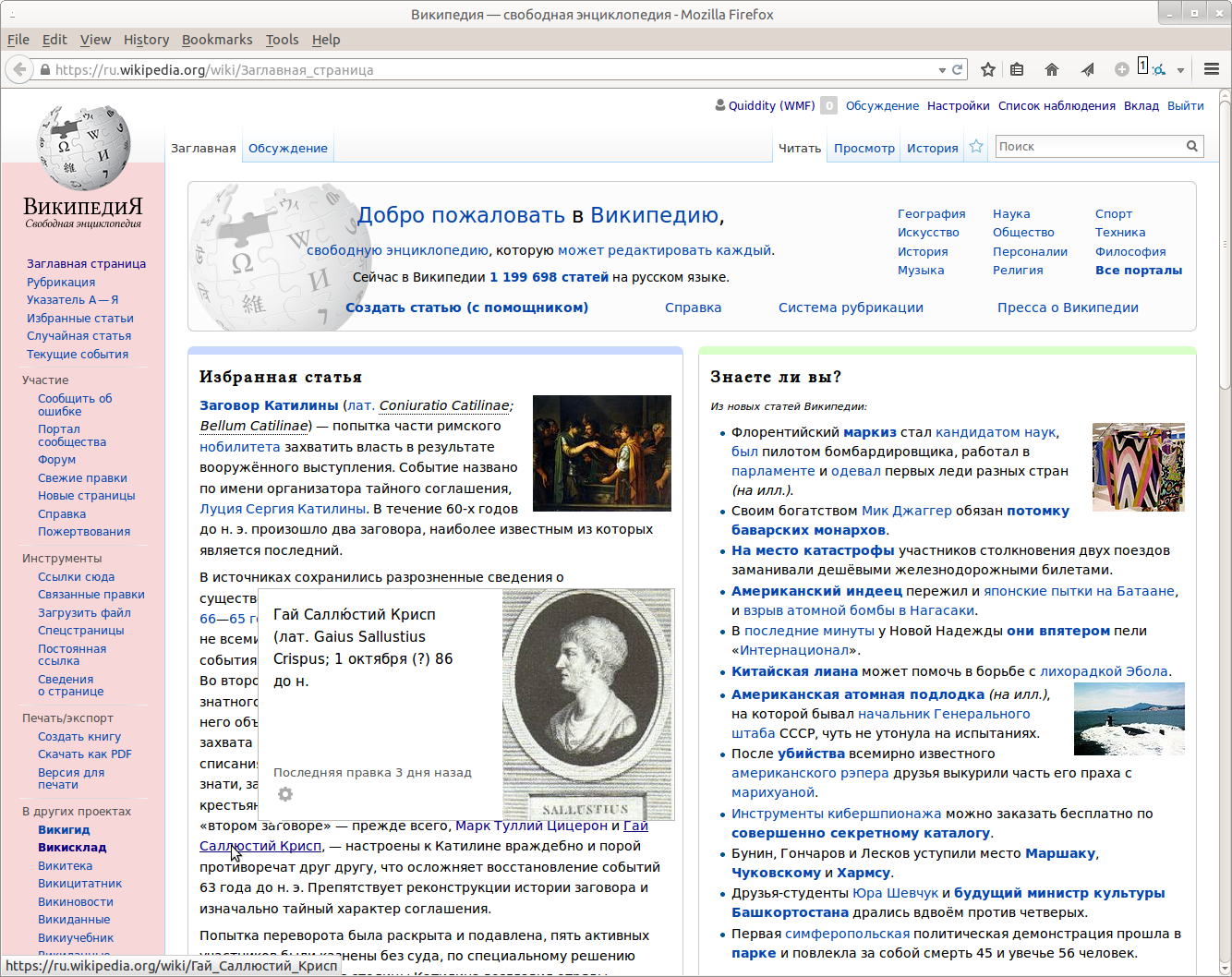
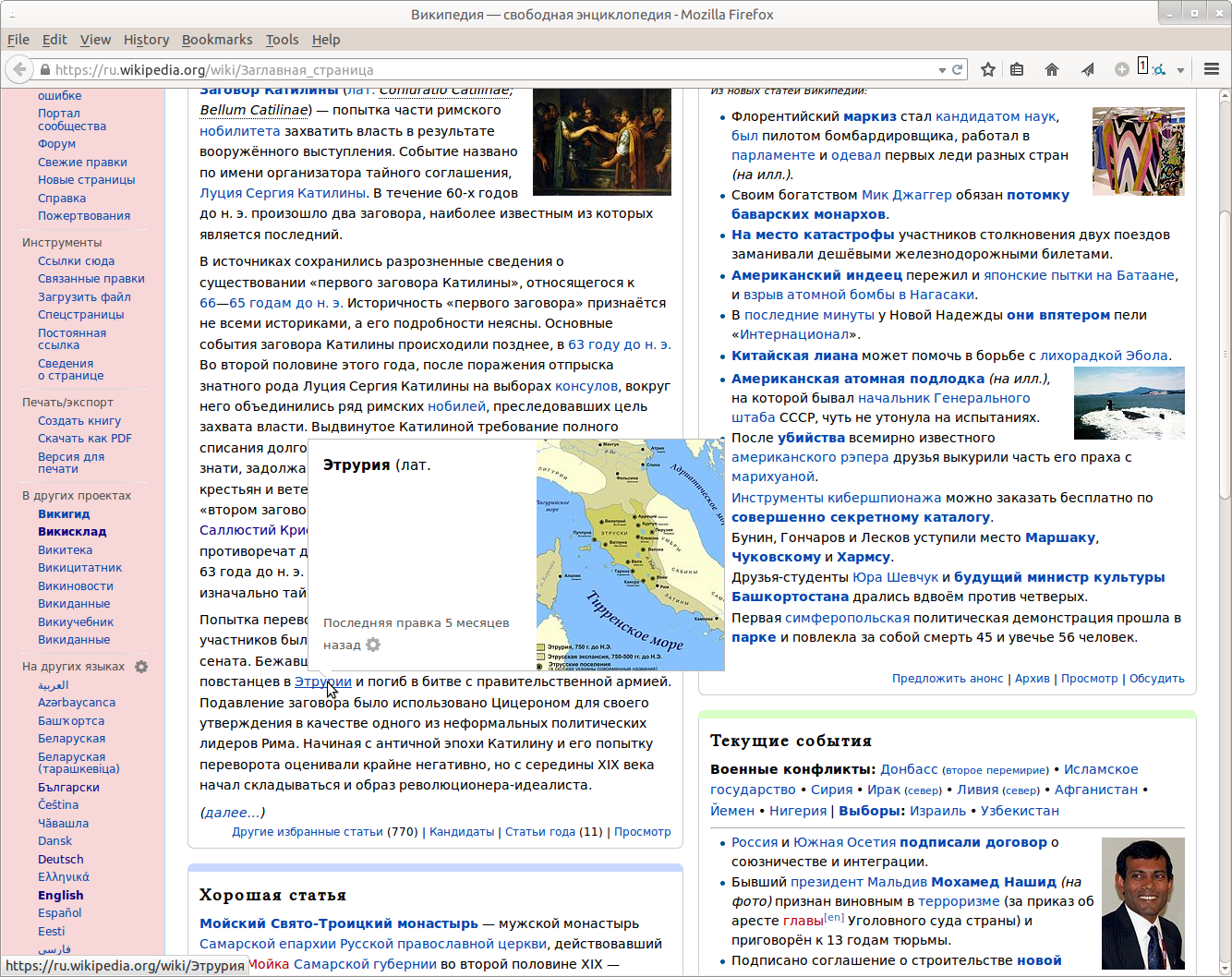
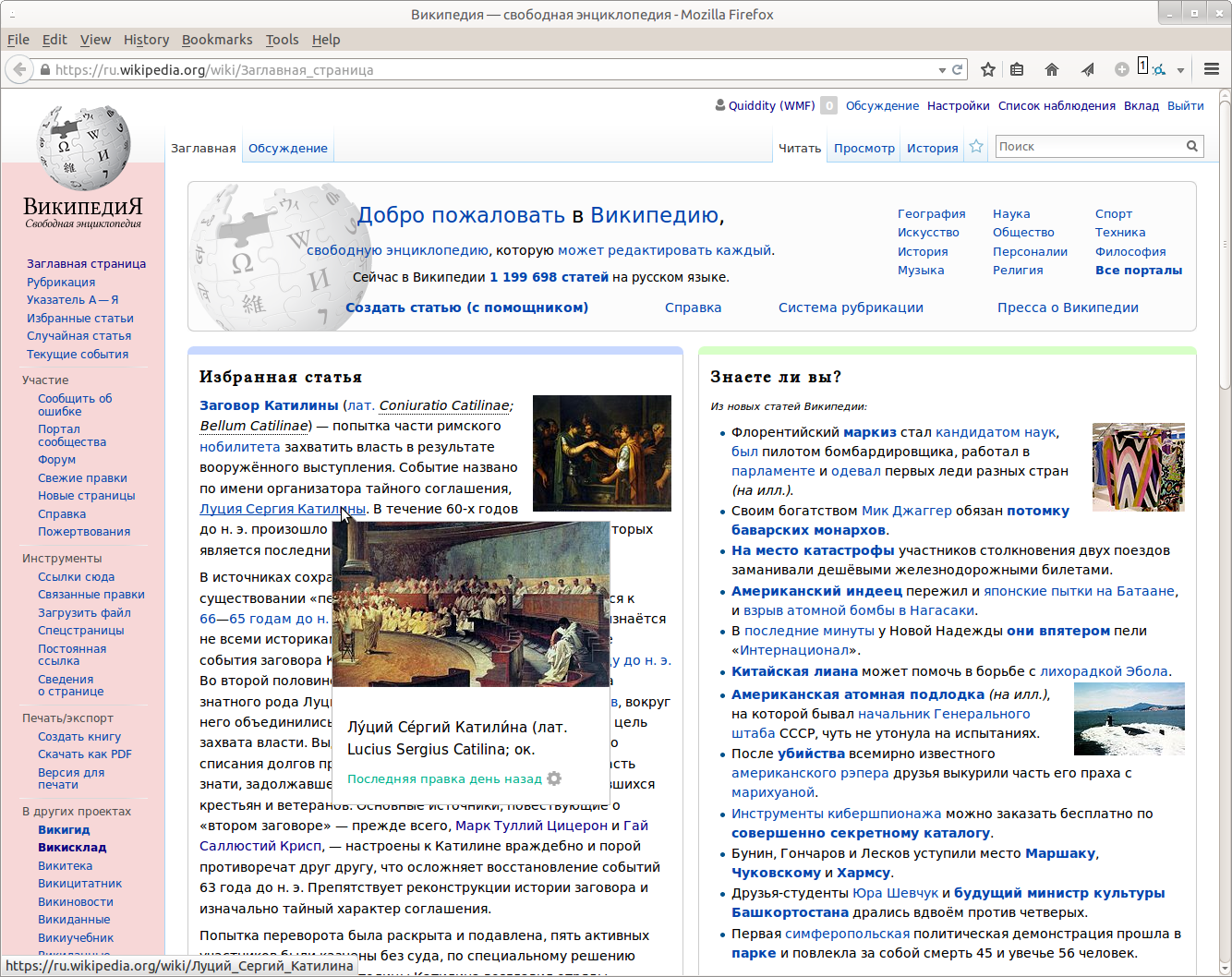
I've only been able to find one example at Enwiki (out of ~100 tests) linking to this article https://en.wikipedia.org/w/index.php?title=Samuel_Allyne_Otis&oldid=523235627
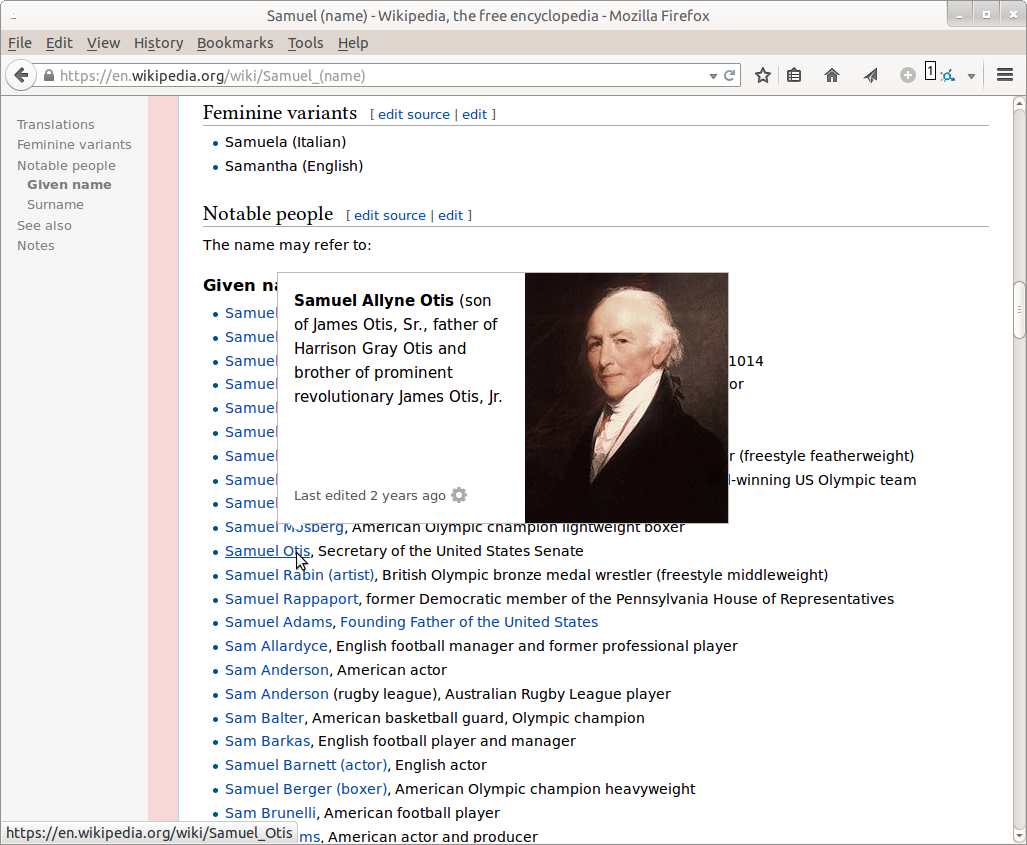
and none at Frwiki,
Note: There is a plan to refine what content is excluded, in T91344: Review exclude all approach to parenthetical elements in summary endpoint, but for the moment No bracketed contented is meant to be shown.