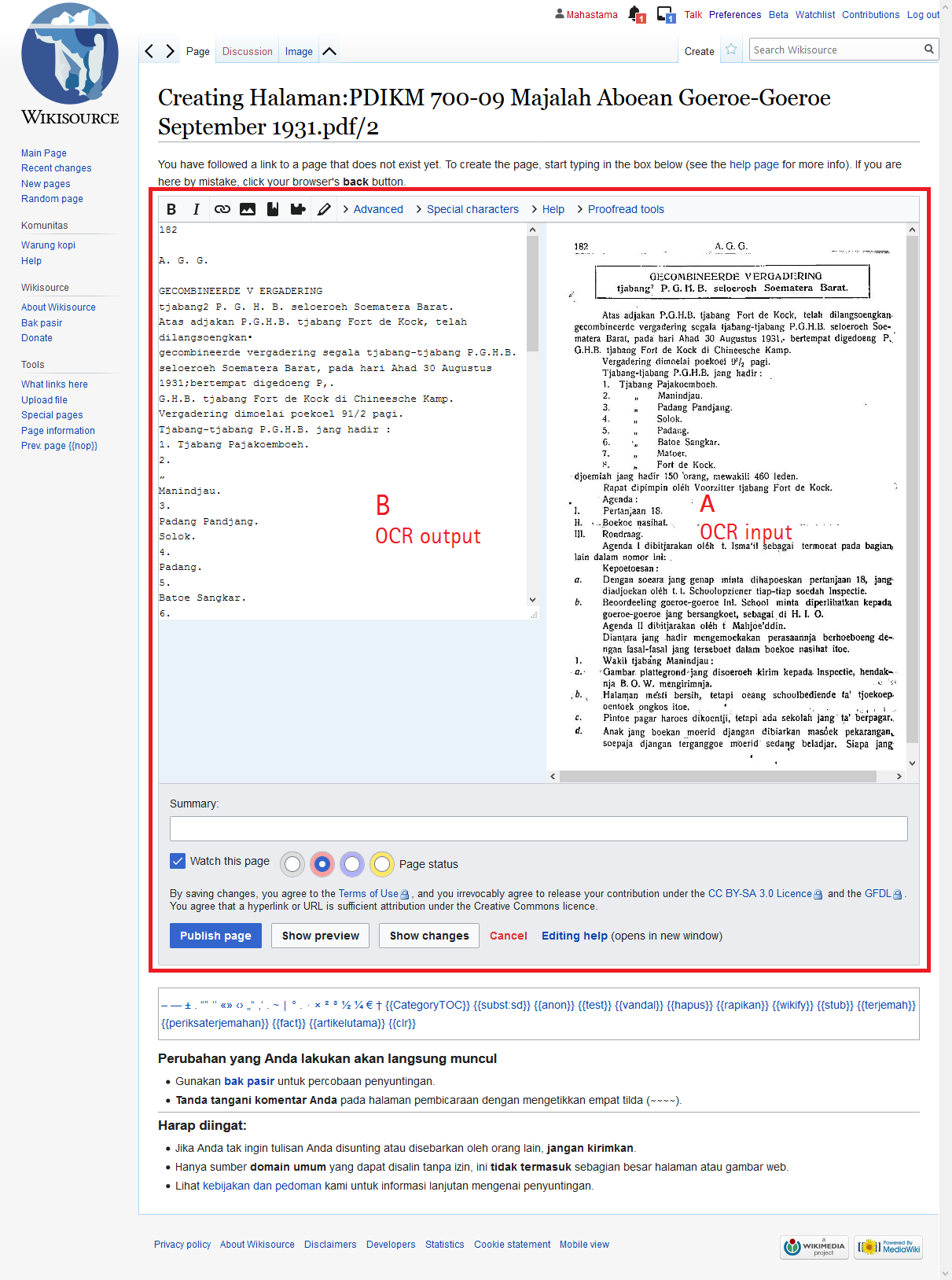
Thanks guys, it's been up and running for the initial test. Apparently the module which we use to accept cross-domain API request has a very short valid period for each API key generated and caused the error mentioned before. We temporarily disable the validity period check at the moment.
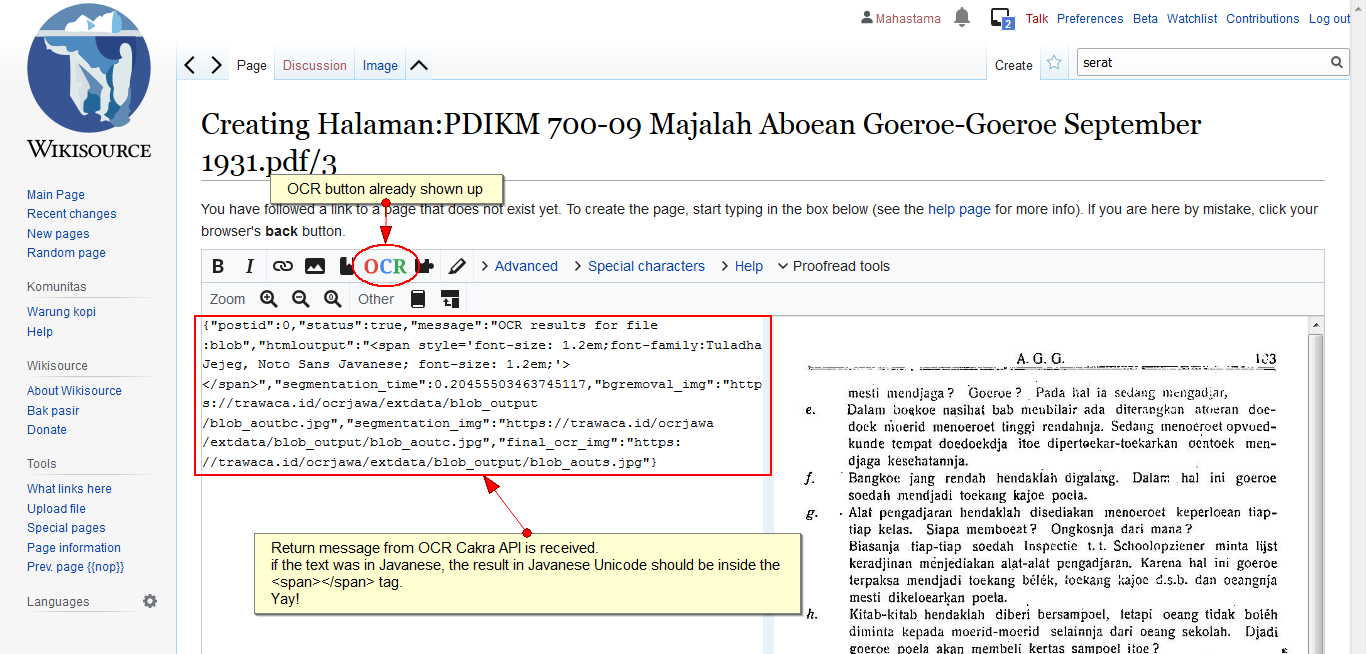
The textbox is already showing the response from the Cakra OCR API. However there are some things still in question:
- We haven't tested it yet using a Wikisource document with Javanese script. I am asking the ID crew to point an example of available file.
- The sent data from the page is apparently in BLOB data type, while the API is designed to receive a JPEG file. We might have to take a look at the process and the data sent, if this will raise an issue on our side or not.
- The OCR result in Unicode jv is contained inside the span tag. Do we have to provide a response in plain text or is it possible to circumvent this so that only the result from inside the span tag is displayed on the textbox? The blank return itself is still within investigation, on whether it is caused by no Javanese script in the document or because the sent data is a BLOB.