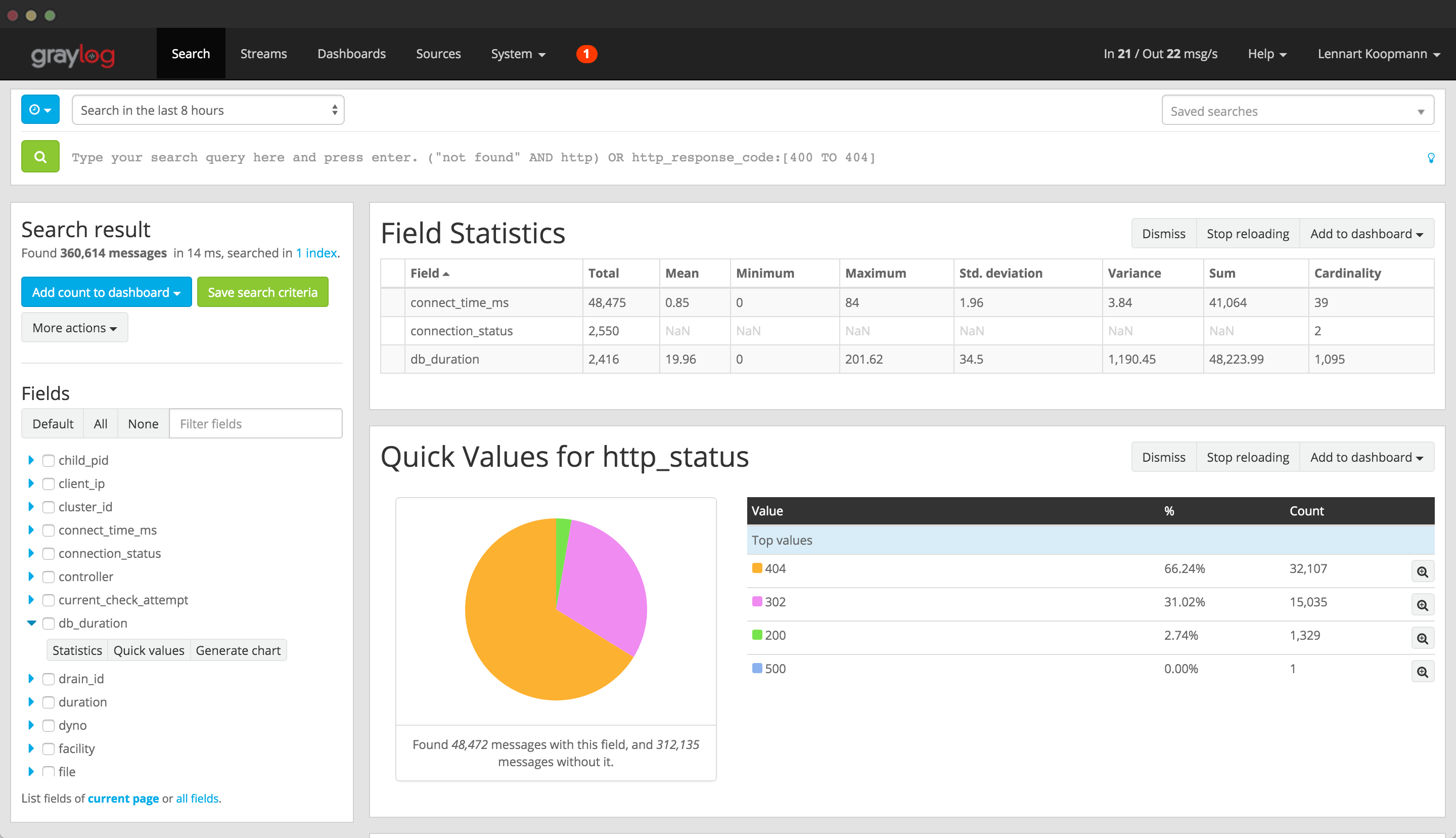
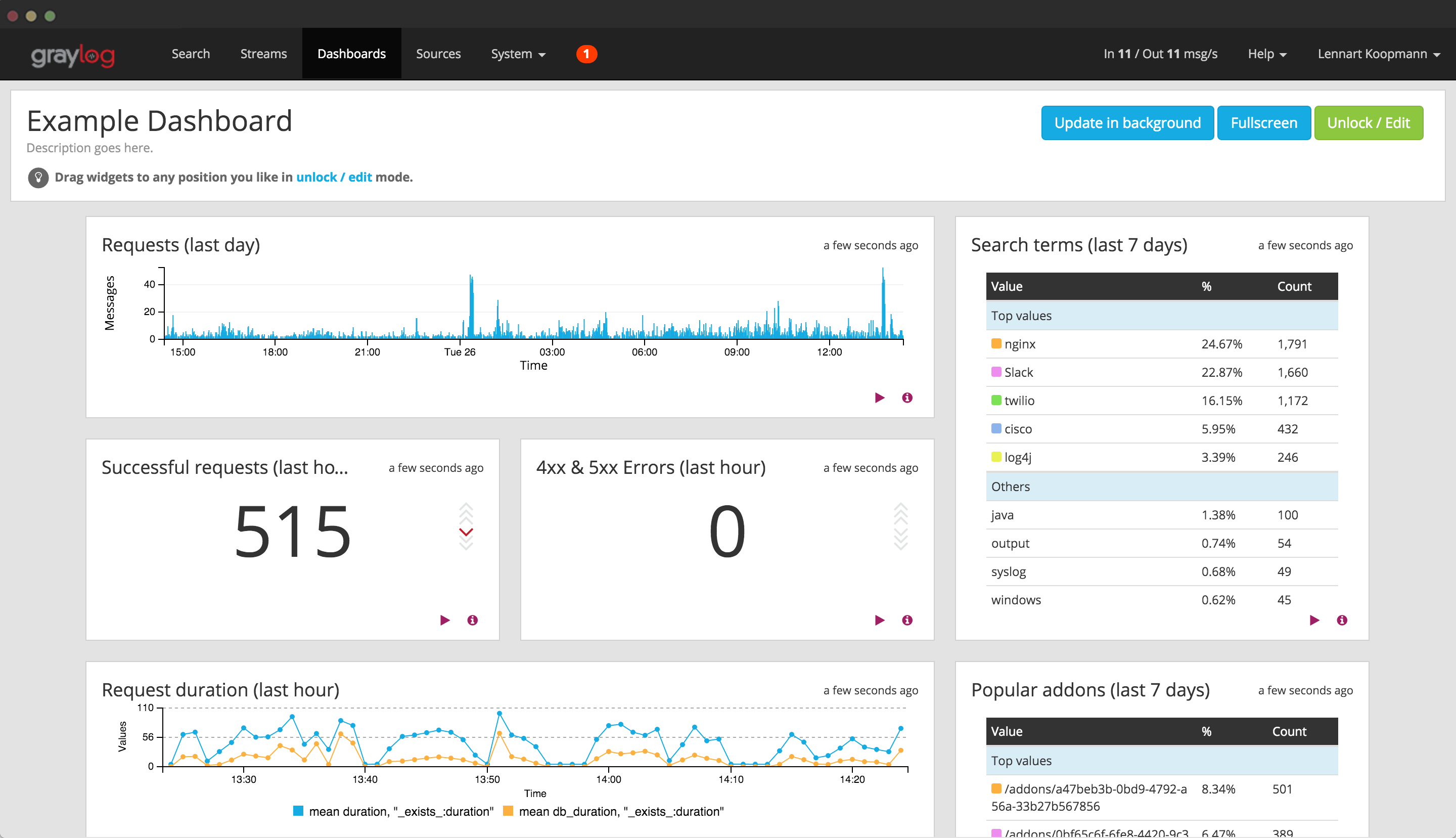
Currently, tools just default to writing log files on to NFS. While simple, this causes a number of problems:
- It adds additional load on our NFS server, which isn't already doing great
- There's a delay between the logs being written on the exec node and being readable on bastion, which is both confusing and annoying
- Logrotate is a PITA with GridEngine + NFS
A solution (based on ElasticSearch, probably - to mirror what we have in production), should allow us to do the following:
- Take load off NFS
- Make it far faster to see the actual logs from processes
- Be able to search through logs easier
- Automatically drop older logs
- Provide a Filesystem based interface for log ingress
- Provide more standard and modern interfaces (gelf? etc) for log ingress
- Provide a filesystem based interface for log reading
- Provide a more modern interface for log reading as well
- Be secure in allowing only authenticated members to read a particular tool's logs.
This is the tracking ticket for this overhaul.
This is specifically *only* for Toolforge, and not for use by general Cloud VPS projects, mostly due to concern 9.
Other related tasks:
- T50846: Provide a central logging service for tools (now defunct)
- T97861: [toolforge.infra] Provide centralized logging (logstash) for Toolforge
- T122508: Prevent overly-large log files
- T127368: Estimate hardware requirements for Toolforge logging elastic cluster
- T293672: [tbs.cli] Create an easy way to extract/tail logs from buildpack based webservices