Description
Details
Related Objects
Event Timeline
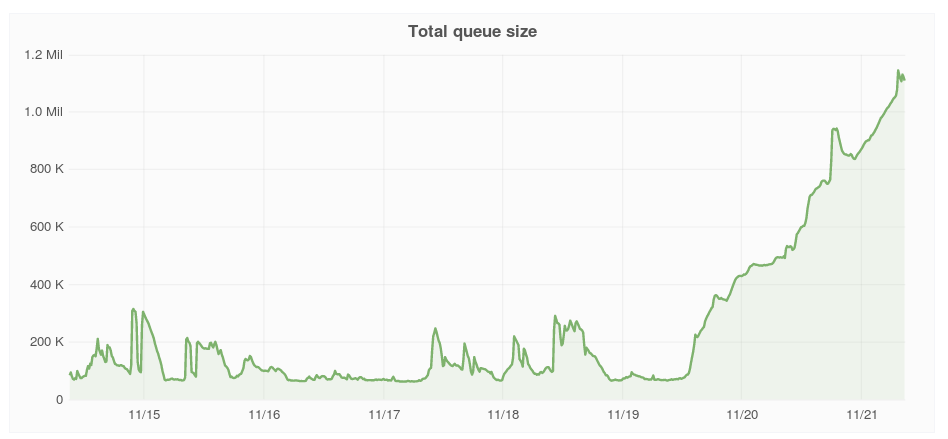
May it be related to recent high bot activity?
After loweing the activity ~twice jobs No. seems to be decreasing slowly (top value was ~1050000):
https://commons.wikimedia.org/w/api.php?action=query&meta=siteinfo&siprop=statistics&format=jsonfm
{
"batchcomplete": "",
"query": {
"statistics": {
"pages": 48557763,
"articles": 124101,
"edits": 239529447,
"images": 34828158,
"users": 6094055,
"activeusers": 30170,
"admins": 238,
"jobs": 998059,
"queued-massmessages": 0
}
}
}Unsure if it is the main reason or related. Similar activity 2-3 days ago did not cause the queue to grow so high.
Looking at some of the jobrunners I get this
$ sudo journalctl -ru jobchron.service Nov 21 11:23:51 mw2081 jobchron[30826]: [Mon Nov 21 11:23:51 2016] [hphp] [30826:7f3d9d5e7100:0:000003] [] LightProcess::closeShadow failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:23:51 mw2081 jobchron[30826]: [Mon Nov 21 11:23:51 2016] [hphp] [30826:7f3d9d5e7100:0:000002] [] LightProcess::closeShadow failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:23:51 mw2081 jobchron[30826]: [Mon Nov 21 11:23:51 2016] [hphp] [30826:7f3d9d5e7100:0:000001] [] LightProcess::closeShadow failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:23:51 mw2081 php[30826]: LightProcess::closeShadow failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:23:51 mw2081 php[30826]: LightProcess::closeShadow failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:23:51 mw2081 php[30826]: LightProcess::closeShadow failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:23:51 mw2081 jobchron[30826]: Caught signal (15) Nov 21 11:23:51 mw2081 systemd[1]: Stopping "Mediawiki job queue chron loop"... Nov 21 11:23:51 mw2081 jobchron[30826]: 2016-11-21T11:23:51+0000 ERROR: Redis error: ERR Error running script (call to f_3917a6b71d2857ca3d40fe6dabc2fc46d8e4e535): @user_script:17: @user_script: 17: -OOM command not allowed when used memory > 'maxmemory'. Nov 21 11:23:51 mw2081 jobchron[30826]: 2016-11-21T11:23:51+0000 ERROR: Redis error: ERR Error running script (call to f_3917a6b71d2857ca3d40fe6dabc2fc46d8e4e535): @user_script:17: @user_script: 17: -OOM command not allowed when used memory > 'maxmemory'. Nov 21 11:23:51 mw2081 jobchron[30826]: 2016-11-21T11:23:51+0000 ERROR: Redis error: ERR Error running script (call to f_3917a6b71d2857ca3d40fe6dabc2fc46d8e4e535): @user_script:40: @user_script: 40: -OOM command not allowed when used memory > 'maxmemory'. Nov 21 11:23:51 mw2081 jobchron[30826]: 2016-11-21T11:23:51+0000 ERROR: Redis error: ERR Error running script (call to f_3917a6b71d2857ca3d40fe6dabc2fc46d8e4e535): @user_script:21: @user_script: 21: -OOM command not allowed when used memory > 'maxmemory'. Nov 21 11:23:51 mw2081 jobchron[30826]: 2016-11-21T11:23:51+0000 ERROR: Redis error: ERR Error running script (call to f_3917a6b71d2857ca3d40fe6dabc2fc46d8e4e535): @user_script:17: @user_script: 17: -OOM command not allowed when used memory > 'maxmemory'. Nov 21 11:23:51 mw2081 jobchron[30826]: 2016-11-21T11:23:51+0000 ERROR: Redis error: ERR Error running script (call to f_3917a6b71d2857ca3d40fe6dabc2fc46d8e4e535): @user_script:40: @user_script: 40: -OOM command not allowed when used memory > 'maxmemory'. Nov 21 11:23:51 mw2081 jobchron[30826]: 2016-11-21T11:23:51+0000 ERROR: Redis error: ERR Error running script (call to f_3917a6b71d2857ca3d40fe6dabc2fc46d8e4e535): @user_script:17: @user_script: 17: -OOM command not allowed when used memory > 'maxmemory'. Nov 21 11:23:51 mw2081 jobchron[30826]: 2016-11-21T11:23:51+0000 ERROR: Redis error: ERR Error running script (call to f_3917a6b71d2857ca3d40fe6dabc2fc46d8e4e535): @user_script:17: @user_script: 17: -OOM command not allowed when used memory > 'maxmemory'. Nov 21 11:23:51 mw2081 jobchron[30826]: 2016-11-21T11:23:51+0000 ERROR: Redis error: ERR Error running script (call to f_3917a6b71d2857ca3d40fe6dabc2fc46d8e4e535): @user_script:17: @user_script: 17: -OOM command not allowed when used memory > 'maxmemory'. Nov 21 11:23:51 mw2081 jobchron[30826]: 2016-11-21T11:23:51+0000 ERROR: Redis error: ERR Error running script (call to f_3917a6b71d2857ca3d40fe6dabc2fc46d8e4e535): @user_script:21: @user_script: 21: -OOM command not allowed when used memory > 'maxmemory'. Nov 21 11:23:51 mw2081 jobchron[30826]: 2016-11-21T11:23:51+0000 ERROR: Redis error: ERR Error running script (call to f_3917a6b71d2857ca3d40fe6dabc2fc46d8e4e535): @user_script:17: @user_script: 17: -OOM command not allowed when used memory > 'maxmemory'. Nov 21 11:23:51 mw2081 jobchron[30826]: 2016-11-21T11:23:51+0000 ERROR: Redis error: ERR Error running script (call to f_3917a6b71d2857ca3d40fe6dabc2fc46d8e4e535): @user_script:48: @user_script: 48: -OOM command not allowed when used memory > 'maxmemory'. Nov 21 11:23:51 mw2081 jobchron[30826]: 2016-11-21T11:23:51+0000 ERROR: Redis error: ERR Error running script (call to f_3917a6b71d2857ca3d40fe6dabc2fc46d8e4e535): @user_script:21: @user_script: 21: -OOM command not allowed when used memory > 'maxmemory'.
The jobrunner.service unit is not very different, even less enlightening in fact
$ sudo journalctl -ru jobrunner.service -- Logs begin at Tue 2016-11-08 11:24:56 UTC, end at Mon 2016-11-21 11:30:38 UTC. -- Nov 21 11:24:05 mw2081 jobrunner[18530]: [Mon Nov 21 11:24:05 2016] [hphp] [18530:7f6a44035100:0:000026] [] LightProcess::closeShadow failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:24:05 mw2081 jobrunner[18530]: [Mon Nov 21 11:24:05 2016] [hphp] [18530:7f6a44035100:0:000025] [] LightProcess::closeShadow failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:24:05 mw2081 jobrunner[18530]: [Mon Nov 21 11:24:05 2016] [hphp] [18530:7f6a44035100:0:000024] [] LightProcess::closeShadow failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:24:05 mw2081 jobrunner[18530]: [Mon Nov 21 11:24:05 2016] [hphp] [18530:7f6a44035100:0:000023] [] LightProcess::closeShadow failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:24:05 mw2081 systemd[1]: Unit jobrunner.service entered failed state. Nov 21 11:24:05 mw2081 systemd[1]: Stopped "Mediawiki job queue runner loop". Nov 21 11:24:05 mw2081 systemd[1]: jobrunner.service: main process exited, code=exited, status=143/n/a Nov 21 11:24:05 mw2081 jobrunner[18530]: [Mon Nov 21 11:24:05 2016] [hphp] [18530:7f6a44035100:0:000022] [] LightProcess::closeShadow failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:24:05 mw2081 jobrunner[18530]: Sending SIGTERM to 5535. Nov 21 11:24:05 mw2081 jobrunner[18530]: [Mon Nov 21 11:24:05 2016] [hphp] [18530:7f6a44035100:0:000021] [] LightProcess::waitpid failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:24:05 mw2081 jobrunner[18530]: Sending SIGTERM to 5533. Nov 21 11:24:05 mw2081 jobrunner[18530]: [Mon Nov 21 11:24:05 2016] [hphp] [18530:7f6a44035100:0:000020] [] LightProcess::waitpid failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:24:05 mw2081 jobrunner[18530]: Sending SIGTERM to 5531. Nov 21 11:24:05 mw2081 jobrunner[18530]: [Mon Nov 21 11:24:05 2016] [hphp] [18530:7f6a44035100:0:000019] [] LightProcess::waitpid failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:24:05 mw2081 jobrunner[18530]: Sending SIGTERM to 5530. Nov 21 11:24:05 mw2081 jobrunner[18530]: [Mon Nov 21 11:24:05 2016] [hphp] [18530:7f6a44035100:0:000018] [] LightProcess::waitpid failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:24:05 mw2081 jobrunner[18530]: Sending SIGTERM to 5529. Nov 21 11:24:05 mw2081 jobrunner[18530]: [Mon Nov 21 11:24:05 2016] [hphp] [18530:7f6a44035100:0:000017] [] LightProcess::waitpid failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:24:05 mw2081 jobrunner[18530]: Sending SIGTERM to 5527. Nov 21 11:24:05 mw2081 jobrunner[18530]: [Mon Nov 21 11:24:05 2016] [hphp] [18530:7f6a44035100:0:000016] [] LightProcess::waitpid failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:24:05 mw2081 jobrunner[18530]: Sending SIGTERM to 5522. Nov 21 11:24:05 mw2081 jobrunner[18530]: [Mon Nov 21 11:24:05 2016] [hphp] [18530:7f6a44035100:0:000015] [] LightProcess::waitpid failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:24:05 mw2081 jobrunner[18530]: Sending SIGTERM to 5520. Nov 21 11:24:05 mw2081 jobrunner[18530]: [Mon Nov 21 11:24:05 2016] [hphp] [18530:7f6a44035100:0:000014] [] LightProcess::waitpid failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:24:05 mw2081 jobrunner[18530]: Sending SIGTERM to 5517. Nov 21 11:24:05 mw2081 jobrunner[18530]: [Mon Nov 21 11:24:05 2016] [hphp] [18530:7f6a44035100:0:000013] [] LightProcess::waitpid failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:24:05 mw2081 jobrunner[18530]: Sending SIGTERM to 5514. Nov 21 11:24:05 mw2081 jobrunner[18530]: [Mon Nov 21 11:24:05 2016] [hphp] [18530:7f6a44035100:0:000012] [] LightProcess::waitpid failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:24:05 mw2081 jobrunner[18530]: Sending SIGTERM to 5512. Nov 21 11:24:05 mw2081 jobrunner[18530]: [Mon Nov 21 11:24:05 2016] [hphp] [18530:7f6a44035100:0:000011] [] LightProcess::waitpid failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:24:05 mw2081 jobrunner[18530]: Sending SIGTERM to 5510. Nov 21 11:24:05 mw2081 jobrunner[18530]: [Mon Nov 21 11:24:05 2016] [hphp] [18530:7f6a44035100:0:000010] [] LightProcess::waitpid failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:24:05 mw2081 jobrunner[18530]: Sending SIGTERM to 5508. Nov 21 11:24:05 mw2081 jobrunner[18530]: [Mon Nov 21 11:24:05 2016] [hphp] [18530:7f6a44035100:0:000009] [] LightProcess::waitpid failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:24:05 mw2081 jobrunner[18530]: Sending SIGTERM to 5505. Nov 21 11:24:05 mw2081 jobrunner[18530]: [Mon Nov 21 11:24:05 2016] [hphp] [18530:7f6a44035100:0:000008] [] LightProcess::waitpid failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:24:05 mw2081 jobrunner[18530]: Sending SIGTERM to 5504. Nov 21 11:24:05 mw2081 jobrunner[18530]: [Mon Nov 21 11:24:05 2016] [hphp] [18530:7f6a44035100:0:000007] [] LightProcess::waitpid failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:24:05 mw2081 jobrunner[18530]: Sending SIGTERM to 5502. Nov 21 11:24:05 mw2081 jobrunner[18530]: [Mon Nov 21 11:24:05 2016] [hphp] [18530:7f6a44035100:0:000006] [] LightProcess::waitpid failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:24:05 mw2081 jobrunner[18530]: Sending SIGTERM to 5500. Nov 21 11:24:05 mw2081 jobrunner[18530]: [Mon Nov 21 11:24:05 2016] [hphp] [18530:7f6a44035100:0:000005] [] LightProcess::waitpid failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:24:05 mw2081 jobrunner[18530]: Sending SIGTERM to 5497. Nov 21 11:24:05 mw2081 jobrunner[18530]: [Mon Nov 21 11:24:05 2016] [hphp] [18530:7f6a44035100:0:000004] [] LightProcess::waitpid failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:24:05 mw2081 jobrunner[18530]: Sending SIGTERM to 5495. Nov 21 11:24:05 mw2081 jobrunner[18530]: [Mon Nov 21 11:24:05 2016] [hphp] [18530:7f6a44035100:0:000003] [] LightProcess::waitpid failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:24:05 mw2081 jobrunner[18530]: Sending SIGTERM to 5493. Nov 21 11:24:05 mw2081 jobrunner[18530]: [Mon Nov 21 11:24:05 2016] [hphp] [18530:7f6a44035100:0:000002] [] LightProcess::waitpid failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:24:05 mw2081 jobrunner[18530]: Sending SIGTERM to 5492. Nov 21 11:24:05 mw2081 jobrunner[18530]: [Mon Nov 21 11:24:05 2016] [hphp] [18530:7f6a44035100:0:000001] [] LightProcess::waitpid failed due to exception: Failed in afdt::recvRaw: Interrupted system call Nov 21 11:24:05 mw2081 php[18530]: LightProcess::closeShadow failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:24:05 mw2081 php[18530]: LightProcess::closeShadow failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:24:05 mw2081 php[18530]: LightProcess::closeShadow failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:24:05 mw2081 php[18530]: LightProcess::closeShadow failed due to exception: Failed in afdt::sendRaw: Broken pipe Nov 21 11:24:05 mw2081 php[18530]: LightProcess::closeShadow failed due to exception: Failed in afdt::sendRaw: Broken pipe
Restarting the units doesn't really help, a few minutes later we are back into that state. I suppose increasing *maxmemory* is the first path to investigate.
There are nearly two million jobs queued now, and while https://grafana.wikimedia.org/dashboard/db/job-queue-health doesn't provide breakdown by type for the overall number, "Activity per minute" shows that nearly all jobs being processed are 'categoryMembershipChange'. For fun comparison, https://commons.wikimedia.org/wiki/Category:Uploaded_with_UploadWizard has a bit more than two million less files in it than it did when folks started removing it.
Can we just ignore the 'categoryMembershipChange' jobs for that category, until it is deleted? I'm sure none of the few people who watch it really want to see all nine million category removals appear on their watchlist. My own watchlist doesn't even load if I try to show "page categorization" changes on it.
Actually, it seems that 'categoryMembershipChange' jobs are being processed processed quickly. There's a backlog of 'htmlCacheUpdate' jobs.
So, these are just the bog-standard jobs generated in WikiPage::onArticleEdit(). The job queue is growing simply because we can't handle this rate of edits.
The number of page revisions being created in the last few days is an order of magnitude larger than normal.
select left(rev_timestamp, 8), count(*) from commonswiki.revision where rev_timestamp > '201608' group by left(rev_timestamp, 8);
Unless Ops can somehow throw more processing power at the problem, the bots removing the category should slow down.
Change 323139 had a related patch set uploaded (by Giuseppe Lavagetto):
jobrunner: temporarily double the html workers
Change 323139 merged by Giuseppe Lavagetto:
jobrunner: temporarily double the html workers
For the record, @Ankry says he stopped his bot for now (which was responsible for about half of the edits, it looks like at least two other bots are currently running).
@matmarex since I increased the htmlCacheUpdate throughput by 100% the queue stopped increasing, and the number of error/timeouts has decreased as well. I'm inclined in seeing how it goes during the day - there is no way to increase the number of processed jobs just for one specific wiki, though, which would be way more effective in this situation.
Change 323151 had a related patch set uploaded (by Giuseppe Lavagetto):
jobrunner: increase (again) the workers for htmlCacheUpdate jobs
Change 323151 merged by Giuseppe Lavagetto:
jobrunner: increase (again) the workers for htmlCacheUpdate jobs
So, even if I raised the number of jobs and the number of submitted htmlCacheUpdate jobs submitted for commonswiki increased:
$ fgrep htmlCacheUpdate jobqueue-access.log | fgrep commonswiki | perl -ne 'print "$1\n" if /T(\d\d:)/;' | uniq -c 1059 07: 1052 08: 847 09: 941 10: 784 11: 1351 12: 1714 13: 2304 14: 2427 15: 854 16:
I don't see an increase in completed htmlCacheUpdate jobs
which is confirmed by runJobs.log on fluorine
fluorine:~$ fgrep commonswiki /a/mw-log/runJobs.log | grep htmlCache | grep ' good' | perl -ne 'print "$1\n" if /^2016-11-23 (\d\d:)/;' | uniq -c 27221 10: 22719 11: 17268 12: 15524 13: 14368 14: 18736 15:
while the number of enqueued jobs is
fluorine:~$ fgrep commonswiki /a/mw-log/runJobs.log | fgrep htmlCache | grep ' STARTING' | perl -ne 'print "$1\n" if /^2016-11-23 (\d\d:)/;' | uniq -c 27221 10: 22719 11: 17268 12: 15524 13: 14368 14: 18736 15: 10558 16:
so for some reason we are starting less jobs even while submitting more of them.
How can this be?
Also, it looks like 1 day old jobs are still being processed, while for htmlCacheUpdate I'd like to process jobs from the last 15 minutes (say) first.
@aaron do you think we can do something to speed up the processing of a specific wiki's queue? I cannot find indications we can from the code.
Also, why this discrepancy between the number of requests to run this kind of jobs and the started/completed ones (we are submitting 3x jobs, but we're processing way less)?
I am seriously baffled by this behaviour, that doesn't make sense to me.
@aaron do you think we can do something to speed up the processing of a specific wiki's queue? I cannot find indications we can from the code.
We can just run runJobs.php for commonswiki on terbium.
Mentioned in SAL (#wikimedia-operations) [2016-11-24T10:13:15Z] <_joe_> running commonswiki htmlCacheUpdate jobs on terbium to catch up with the backlog, monitoring caches for vhtcpd queue overflows T151196
So, I solved the "mistery": since I last checked, we're throttling htmlCacheUpdates on the jobrunners, so more submissions won't translate into more actual jobs ran.
To catch up with the backlog, I am running on terbium, at 60 seconds interval
mwscript runJobs.php --wiki=commonswiki --maxjobs 1000 --maxtime 60s --type htmlCacheUpdate --nothrottle
and then checking if this makes vhtcpd overflow its queue with
salt -v -t 5 -b 101 -G cluster:cache_text --out=raw cmd.run "cat /tmp/vhtcpd.stats | awk '{print \$7,\$8}'"I might increase the frequency of purges if it seems not to affect the caches.
Mentioned in SAL (#wikimedia-operations) [2016-11-24T17:25:48Z] <_joe_> turned off additional workers for htmlcacheupdate on commonswiki as the queue has reduced to acceptable sizes (T151196)
Related (and tricky) task is T123815, where the backoff times are waaay to pessimistic. The X/sec limit is quickly reached per server and then the runners which to other types for 0-120sec or so. So you get a small window of X/sec, then a large window of 0, and rinse and repeat. The end result is that, overall, the run rate is way less than X/sec.
X=20 in wmf-config now.
I had a patch to take a crack it this, but ended up abandoning it since it wasn't fully as nice as I wanted and there was no problem at the time...might be worth resurrecting some work to make the nominal throttle rates be closer to the real throttle rates...
@aaron why can't we just do something smarter and have a global throttling on a specific job type done by using the poolcounter?
I say this as we probably want to have at most N cache purges at the same time across the whole cluster - at least that's the limit that makes sense.
In the meantime, the queue has grown again during the night, and for the same reason - htmlCacheUpdate jobs for commonswiki. This has to be expected as we have bots doing several hundreds of edits/minute on commons and we can't clearly keep up with that rate of edits.
In general, I would like our job processing to be smarter, doing one of multiple of the following things:
- Be smarter about which jobs to pick; if xyzwiki has a backlog of 20 htmlCacheUpdates and commonswiki has 2 M, maybe prioritize the longest queue
- Have a configurable, global hard limit on concurrency rather than on the per-second rate
- Better instrumentation, and specifically:
- Register the number of jobs per type and wiki submitted to HHVM
- Register the number of actual jobs, per job type and wiki that have completed, and time of completion
- A breakdown, again by type/wiki, of the current queue (I am actually going to do this myself, probably)
- Allow operators to prioritize easily a kind of job type/wiki manually if needed
but I'd wait and see what our plans on asyncronous processing are at the WMDS before we proceed in any way.
@Joe's runJobs.php run has brought the queue back to normal levels, but it is growing again at a similar rate.
@matmarex agreed, I was waiting for about one day of data to accrue, but it's clearly a good idea to have the script run constantly at a controlled rate.
Mentioned in SAL (#wikimedia-operations) [2016-11-28T10:18:11Z] <_joe_> stopping the dedicated commonswiki htmlCacheUpdate job runner, T151196
Mentioned in SAL (#wikimedia-operations) [2016-11-28T16:49:58Z] <_joe_> re-started the commonswiki htmlCacheUpdate dedicated jobrunner (T151196)
Mentioned in SAL (#wikimedia-operations) [2016-11-28T17:20:57Z] <_joe_> turned on the second commonswiki htmlCacheUpdate dedicated jobrunner (T151196)
Mentioned in SAL (#wikimedia-operations) [2016-11-30T08:44:31Z] <_joe_> stopped dedicated commonswiki jobrunner T151196
The deletion bot jobs on commons finished yesterday near 21:00 UTC
Hopefully, there will be no similar massive action in near future.
@matmarex I can confirm the jobqueue is now under control and I think the only real thing missing is better instrumentation of the jobqueue. I'll post a followup ticket and close this one when I'm done.