Before we begin to graduate the Page Previews beta feature across the groups of wikis, it's our responsibility to make sure that we have a clear overview of how the feature is performing on a day to day basis rather than, say, waiting for analysis of the latest batch of Event Logging data.
Initially we can this information to inform our rollout plan – especially for the group2 wikis (See T136602: Graduate the Page Previews beta feature on stage 0 wikis). Once we're fully rolled out though, we can use it a place to view the in-the-wild performance impact of any future work that we do.
AC
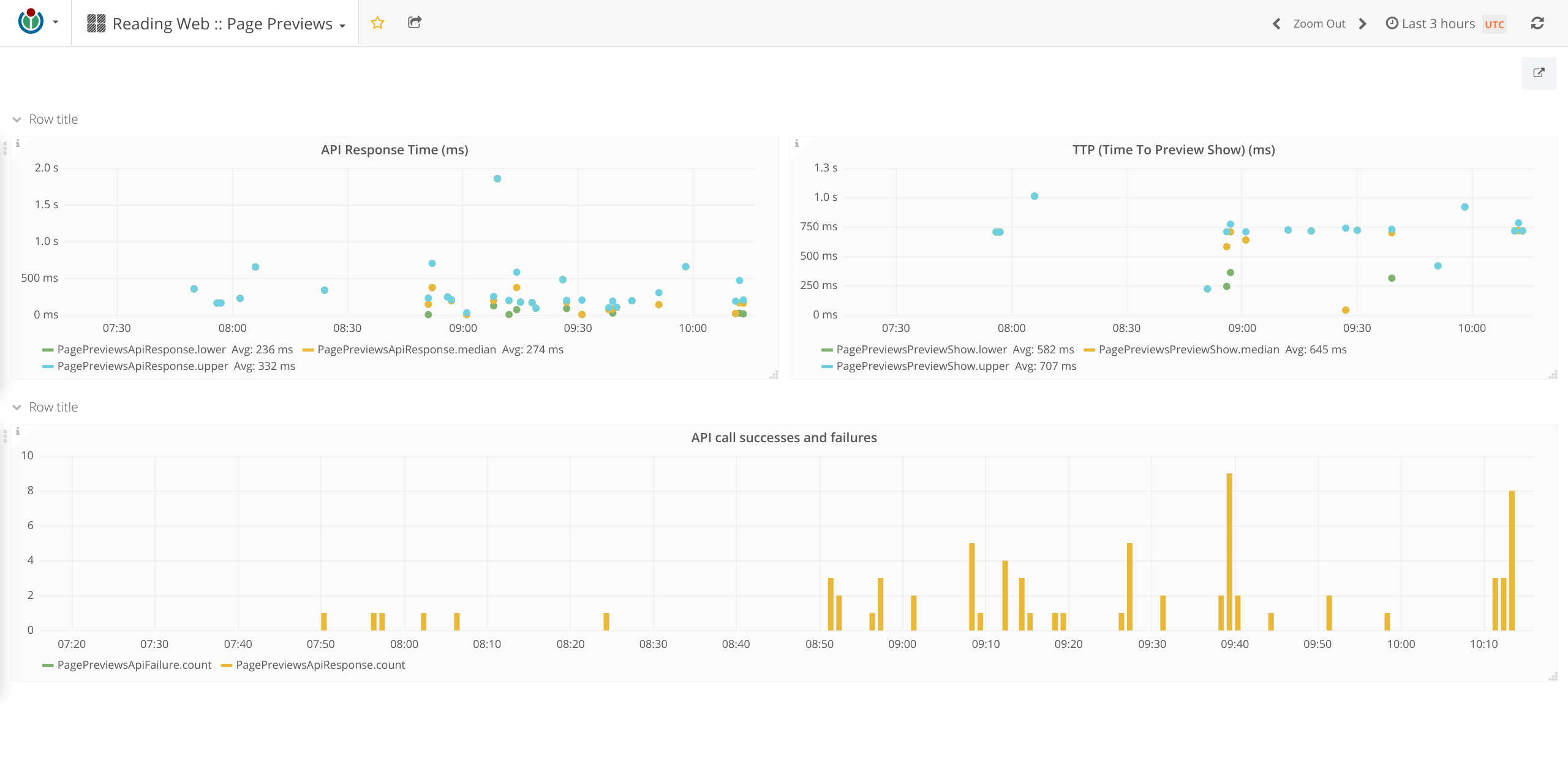
- The Reading Web :: Page Previews dashboard is available at https://grafana.wikimedia.org and displays the following metrics:
- Time taken for an API request
- Rate of API request failures
- Time taken to display a preview after the user dwells on a link.
Possible Metrics
The following aren't strictly performance metrics:
- Number of logged out users enabling feature
- Number of logged out users disabling feature
- Empty (or "generic") previews shown per page
- Extract previews shown per page
Implementation Notes
Grafana graphs get their data from Graphite, which in turn gets its data from statsd, primarily. There are a couple of ways that we could get the from the client into statsd to create the dashboard:
statsv
We'd add secondary instrumentation to the Page Previews codebase that sends data to statsv for a sample of users.
Pros
- Familiarity – this is the approach we take with instrumenting features with EventLogging.
- The existing instrumentation already accumulates timing information for the Popups schema, e.g. for the totalInteractionTime property.
Cons
- Increased configuration complexity.
- As usual, this behaviour must be disabled by default and the sample size should be configurable.
- Increased bandwidth usage/resource consumption.
- Generally speaking, a higher cost of making a change to the instrumentation.
EventLogging
We'd create a new EventLogging stream processor per https://wikitech.wikimedia.org/wiki/Graphite#EventLogging.
Pros
- Lower cost of making a change to the instrumentation.
- We can deploy a new version of the stream processor to hafnium whenever we require.
- No changes to the codebase.
- Enabled/disabled transparently to the client (in this context, the Page Previews code running in the UA).
- Similarly – but worth pointing out – a change in the sampling rate for EventLogging is reflected immediately.
Cons
- Generally speaking, unfamiliarity with the stack.
- Increased architectural complexity.
Further Reading
- Graphite on Wikitech.
- Especially, the Data Sources section.