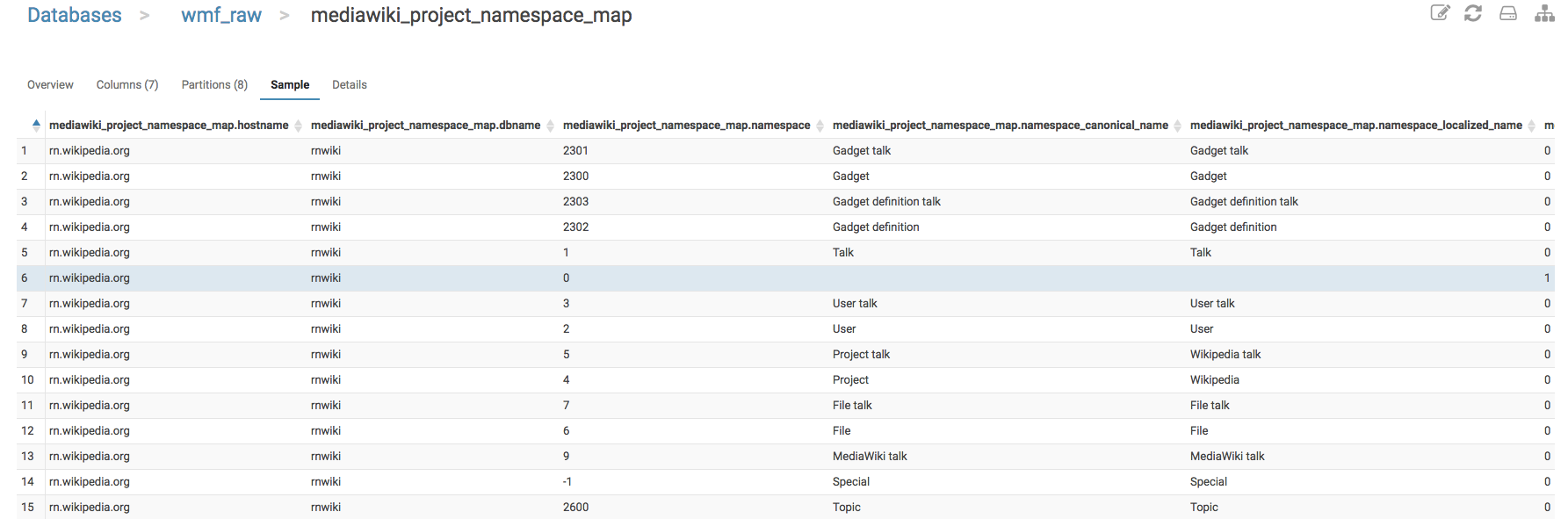
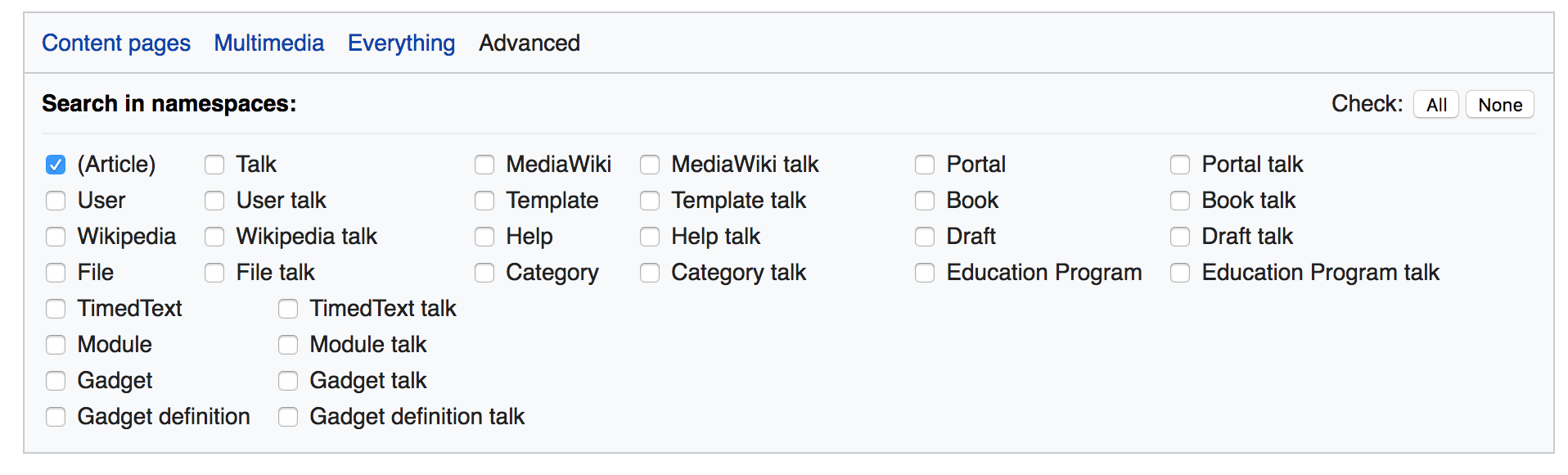
Ideally we would love to have the following:
Per wiki project and language a csv of the last searches[1] with
project + language | namespaces searched (in alphabetical order) | number of times
[1] Many would be good, but the file should still be sendable via mail ;) We thought about something like 24h maybe? But if you have a better sampling strategy, feel free!