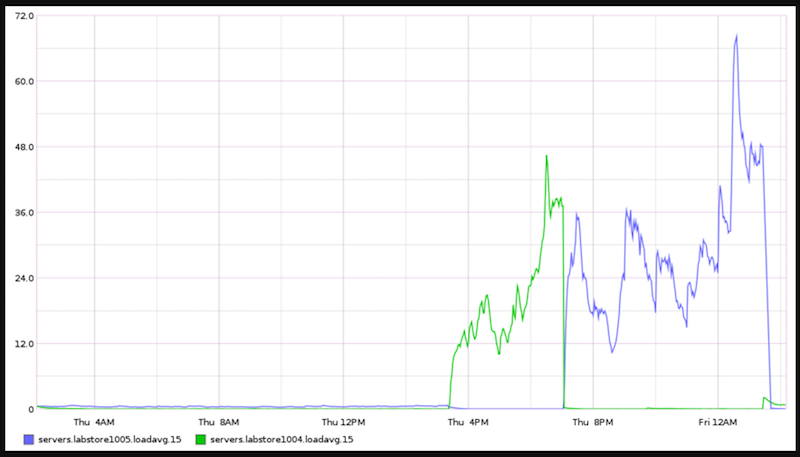
We upgraded labstore1004/1005 to 4.9.25-1~bpo8+3 and things got really bad. Downgraded back to the former kernel and things got better.
Attached graph shows this in terrifying color.
| Andrew | |
| Jun 30 2017, 2:37 AM |
| F8575779: nfsperformance.png | |
| Jun 30 2017, 2:37 AM |
We upgraded labstore1004/1005 to 4.9.25-1~bpo8+3 and things got really bad. Downgraded back to the former kernel and things got better.
Attached graph shows this in terrifying color.
"A total of 16,214 non-merge changesets were pulled into the mainline repository for the 4.9 development cycle, making this cycle the busiest in the kernel project's history." https://www.linux.com/news/linux-weather-forecast
Summarizing from IRC for posterity :)
Load was proportional to what we would expect but way inflated (periods of high use were higher and periods of low use were lower). We generally see load of .5-3 during normal operations over the last 10 months or so and here it was averaging 20-50 and we were seeing 80-110. Client side we saw load climb, and we observed a rotating cast of nfsd procs in D wait state server side. When nfs-kernel-server was stopped load dropped until it was started again. Other than performance being way off normal T169281 was the only real clue that things were wrong.
I talked to someone in #drbd (lge a dev I think) who said they have no reason to think there would be an issue with 4.4 or 4.9 kernel variants with the module version 8.4.5 but they suggested we grab https://github.com/LINBIT/drbd-8.4 and build at 8.4.10 their 'out of tree' bug fix and up-to-date tag as that's the next step to really demonstrating for upstream. Suggested double checking IO scheduler doesn't change since that could have drastic effects.
This is resolved, the jessie-based labstore servers are running 4.9 since a few weeks.