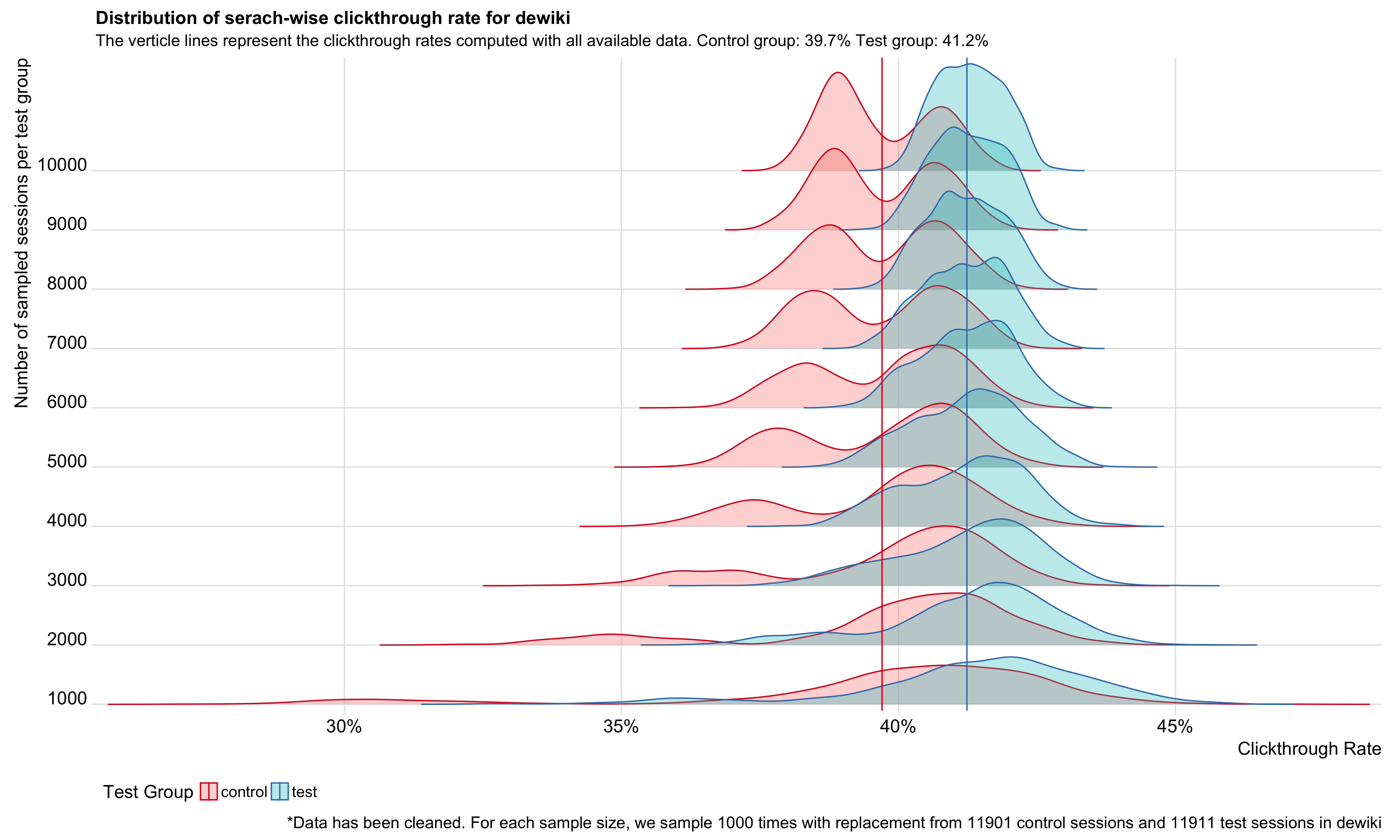
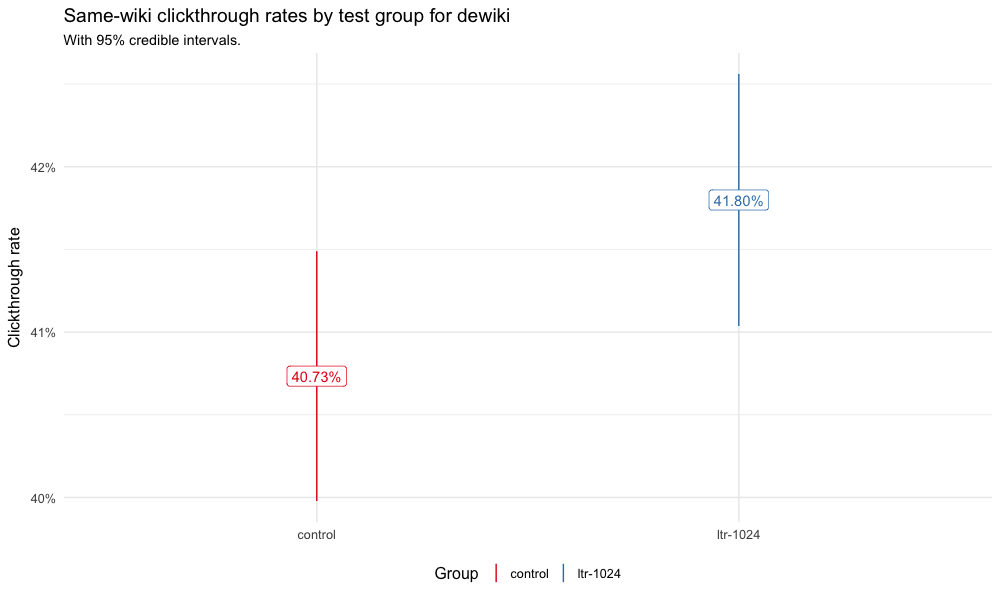
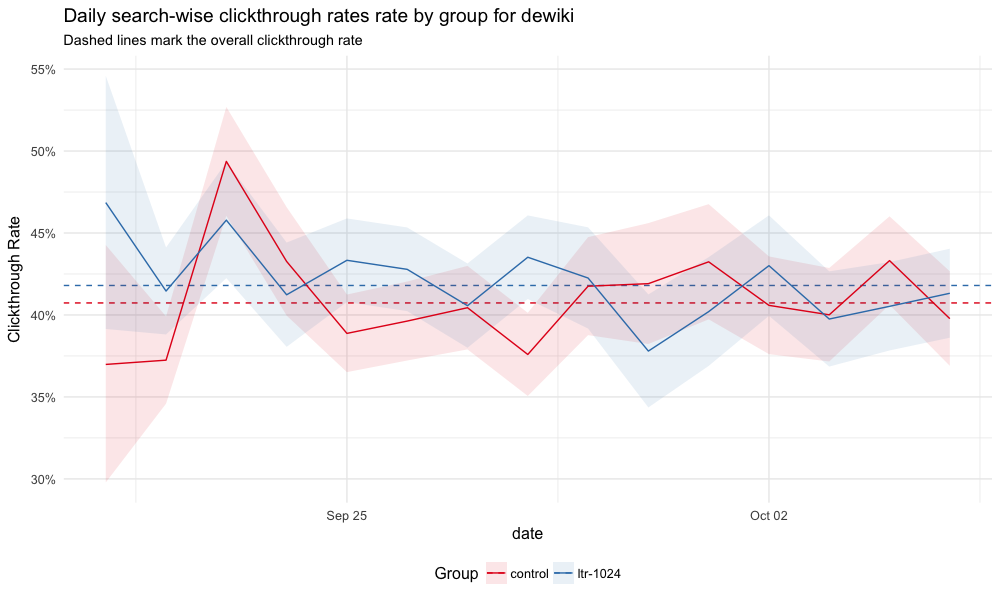
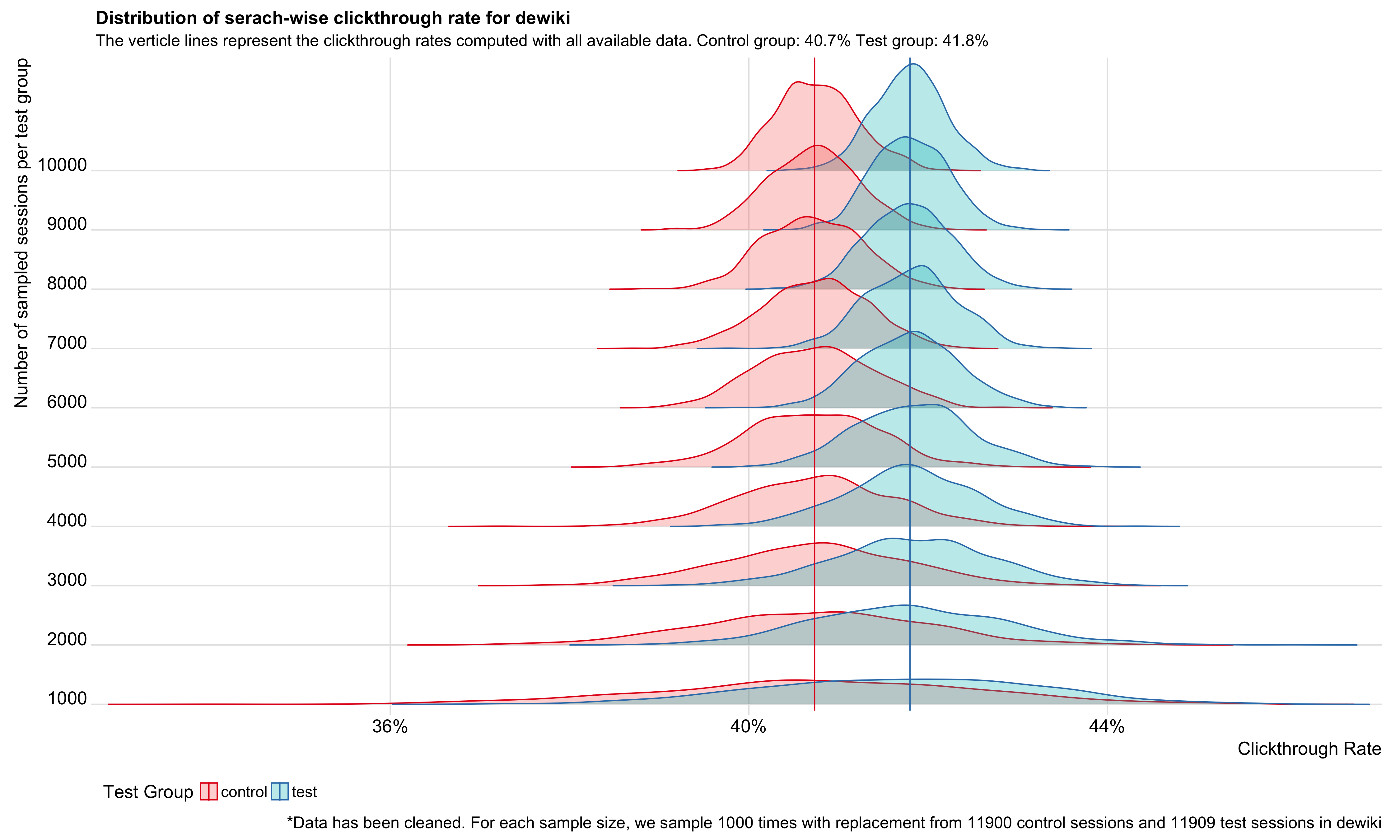
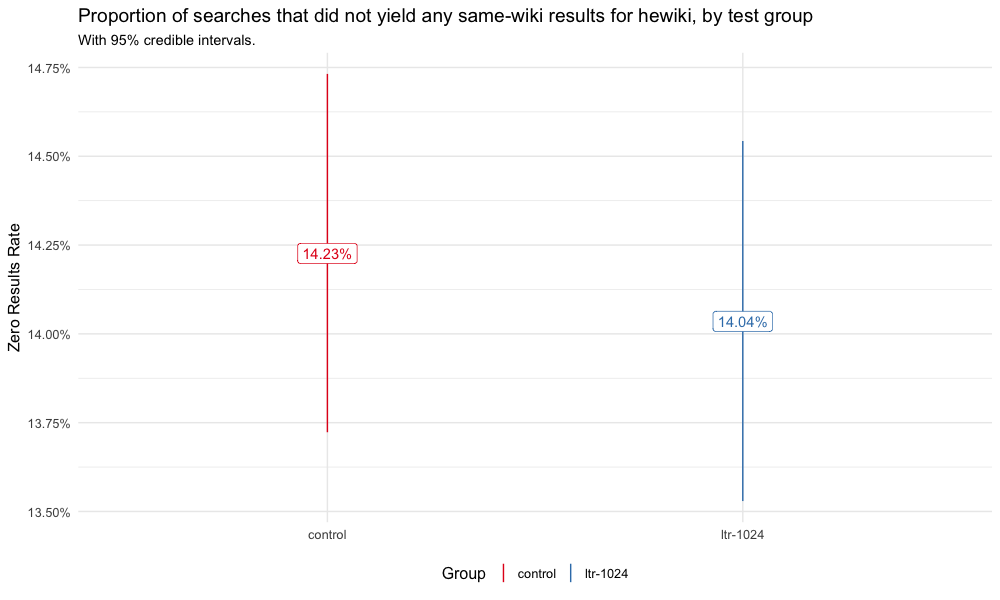
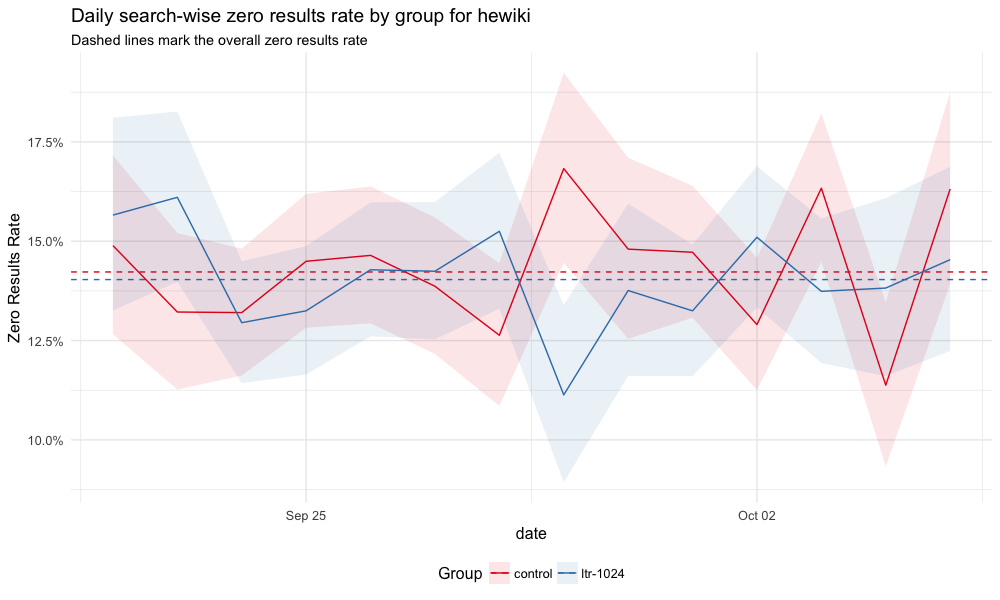
Since the enwiki test went well and it's been deployed in production, we wanted to see if running the same test on wikis that are as low as 1% of all search traffic would get the same results. This ticket is to do the analysis after the test finishes up: T175771.
(Edit: adding the explicit list of languages and codes for searchability: ar, de, fa, fi, fr, he, id, it, ja, ko, nl, no, pl, pt, ru, sv, vi, zh; Arabic, German, Persian, Finnish, French, Hebrew, Indonesian, Italian, Japanese, Korean, Dutch, Norwegian, Polish, Portuguese, Russian, Swedish, Vietnamese, Chinese.)