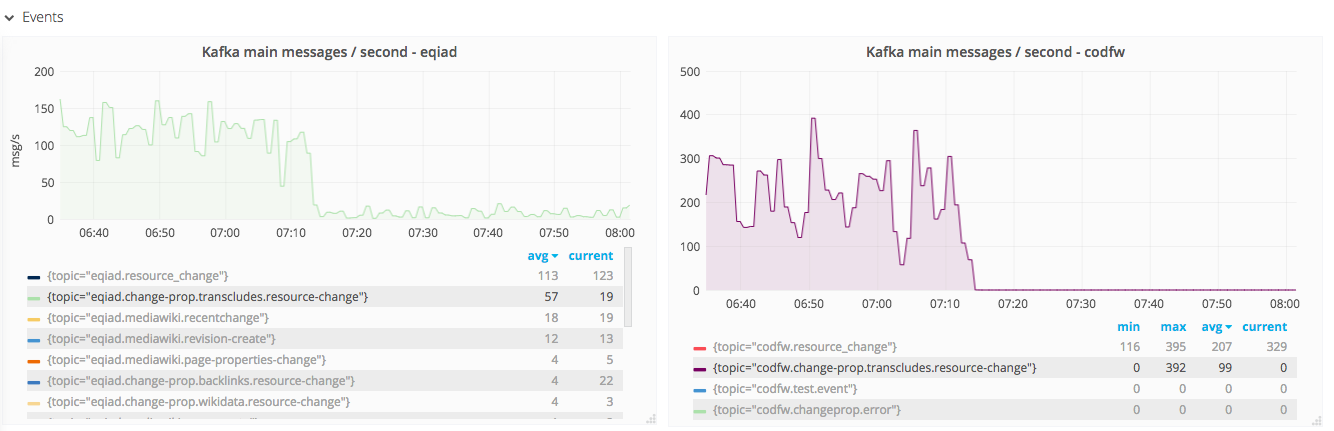
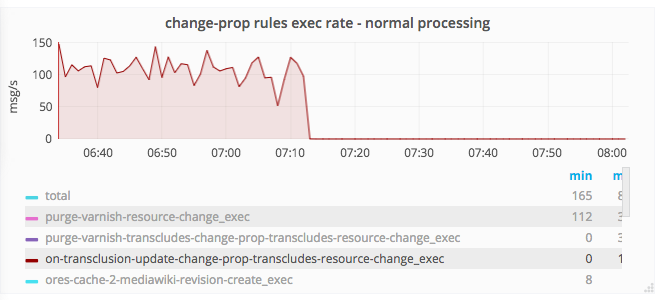
On Nov 03 1 am UTC a daily automatic reds restart happened. Following them there were a lot of logs from ChangeProp that it couldn't connect to redis. Following that change-prop workers stopped sending heartbeats massively and we killed by masters. Following respawning of killed workers happened in a bulk, so Kafka connection errors started occurring.
This ticket is created to find out why did change-prop workers stop sending heartbeats when they've lost connection to Redis.