Description
Description
| Status | Subtype | Assigned | Task | ||
|---|---|---|---|---|---|
| Resolved | aaron | T183889 2017-12-30 save timing regression | |||
| Resolved | Joe | T184048 HHVM hangs on the API cluster |
Event Timeline
Comment Actions
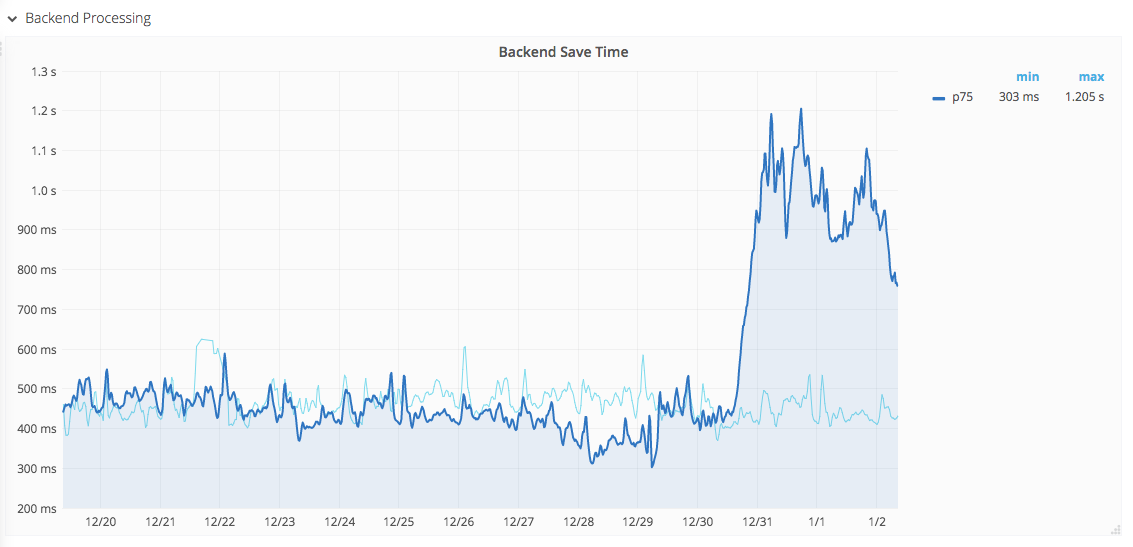
Looking at the new breakdown dashboard: https://grafana.wikimedia.org/dashboard/db/backend-save-timing-breakdown?refresh=5m&orgId=1
- all user types are affected
- bot edit rate is actually going down during that period, the rest is stable
- the API entry point is more affected than the index entry point
- the API edit rate goes down during that period, index is stable
- all page types are affected
- content pages edit rate is down during that period
I'm not sure what to make of it. Maybe the fact that all types are affected is an unavoidable side-effect due to the increased load on shared DB resources.
Is the rate of bot+api+content going down because that combo is causing the issue? Or are the bots backing off/being throttled somehow because of the increased load?
Comment Actions
This recovered a few hours ago:
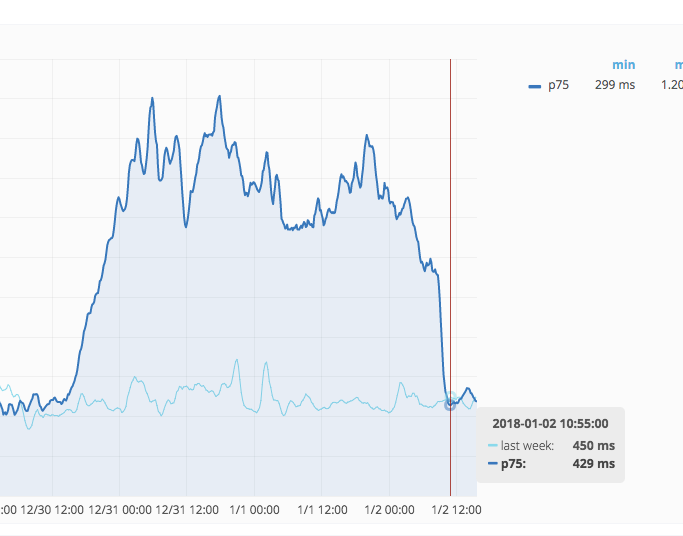
Haven't yet seen anything that would point to a fix/change going in at that point, but doesn't mean that one didn't.
Comment Actions
Pinged the Ops mailing list to see what might have happened. Closer look at Grafana shows recovery started right around 8:45UTC[1], and SAL has a log of a number of MW servers being restarted around that same time[2], so possibly something related there.
[1] https://grafana.wikimedia.org/dashboard/db/backend-save-timing-breakdown?orgId=1&from=1514876696365&to=1514895739684
[2] https://tools.wmflabs.org/sal/log/AWC2EstYwg13V6286YMQ
Comment Actions
Ruled a few things out, but nothing conclusive yet:
- HHVM APC Usage: no notable changes that align with our regression. I checked it because of the mention of server restarts, which resets APC values.
- Backend Save Timing Breakdown: the regression affected users, page types, and entry points equally. Probably not caused by batch activity of any particular (group of) user(s).
- Edit Count: no notable change in Edit rate or Save failures.
- Save Timing: shows that Frontend Save Timing did regress significantly at multiple times during this timeframe.
| Frontend | Backend |
|---|---|
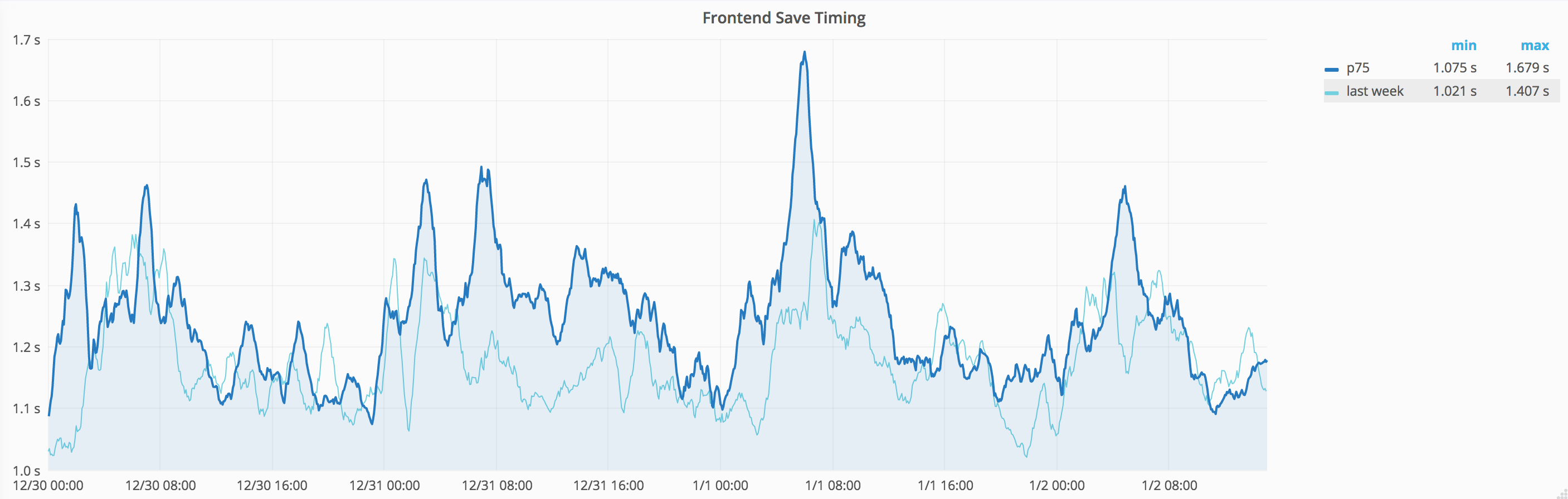 | 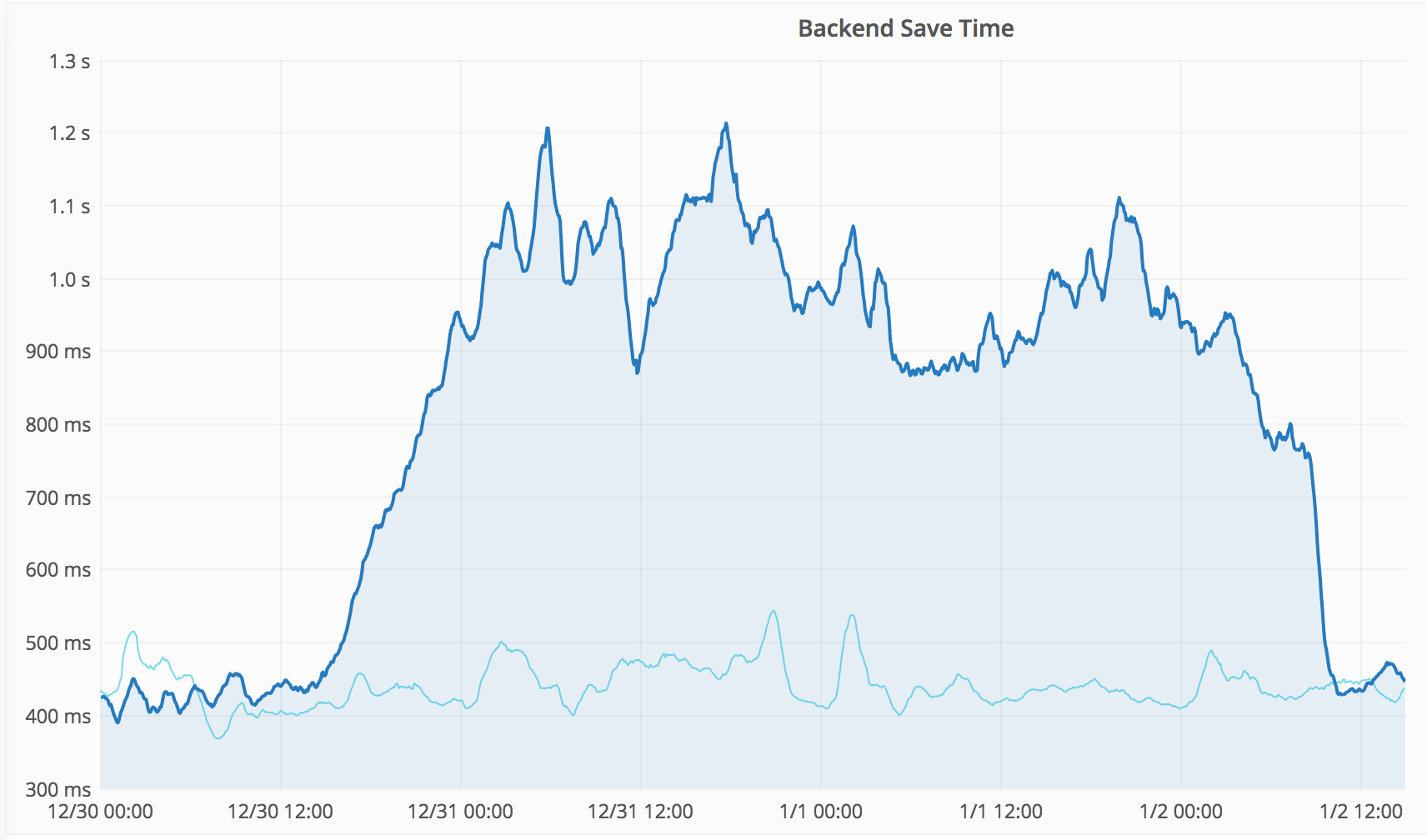 |
It isn't obvious at first due to the difference in vertical scale, but the regression is equally continuous and roughly aligns. The correlation isn't perfect, so it is imho not conclusive, but it aligns enough that it seems likely to be related.
The backend p75 metric regresses by about +700ms, from 30 Dec 16:00 to 2 Jan 08:30.
The frontend p75 metric regressed by about +300ms, from 30 Dec 20:00 to 2 Jan 07:00.
| Frontend (last 30 days) |
|---|
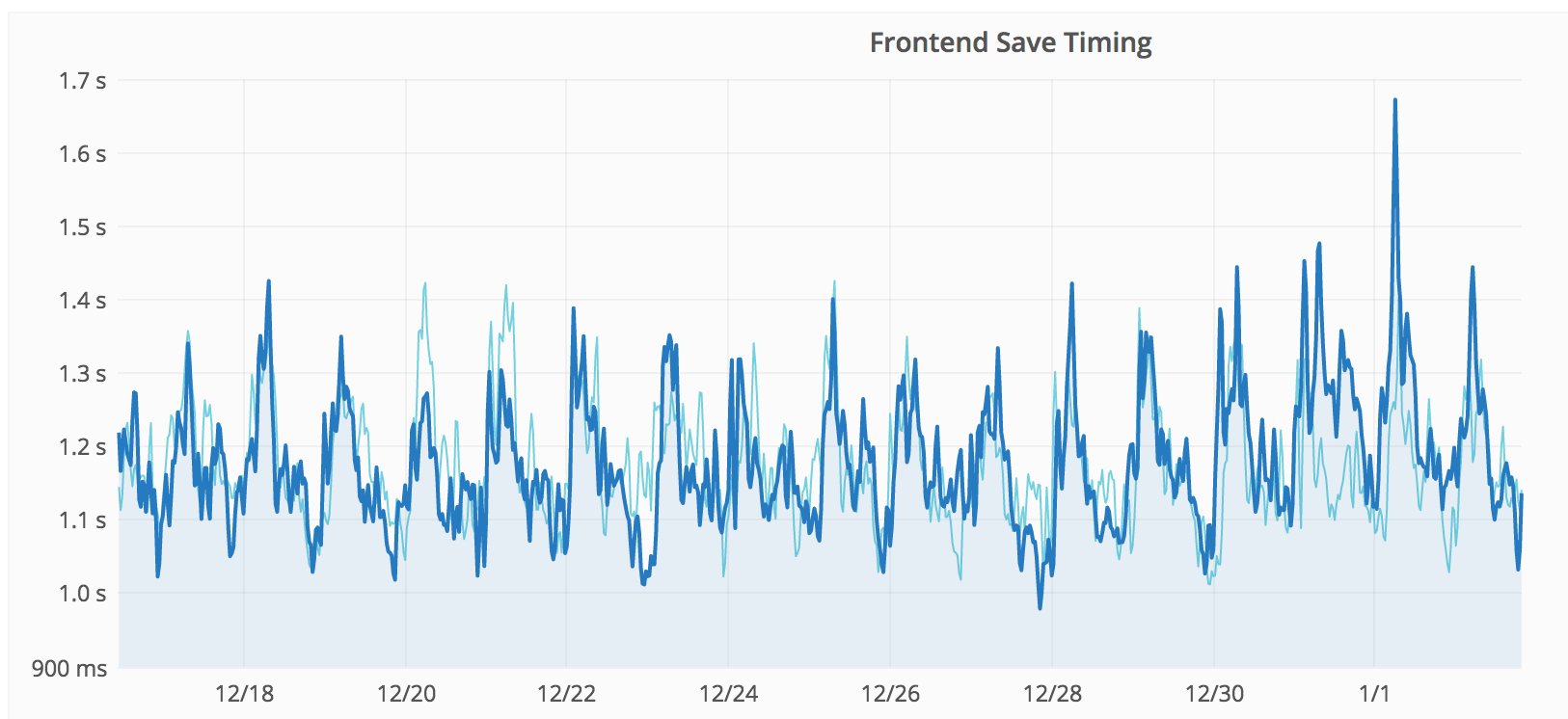 |
Comment Actions
As I mentioned in the email thread last night, and I confirmed looking at the timings, this is related to a spike in CPU usage on the API cluster in eqiad:
all evidence in this case seem to point to a case of https://phabricator.wikimedia.org/T182568 - it resolved once I came back to work and noticed a few hhvm API appservers maxing out their CPU.
But looking at the backtraces on some of the machines, I have started having some doubts - it surely is a hang, but it seems to be of a different nature than the one I reported in that bug - specifically the threads seem to be deadlocked in some sort of internal loop, and not reading from a file like last time. I'll open a bug about this new issue today.
One thing we could do is to raise a critical alert if the load /cpu on an API appserver is higher than a very high threshold for an extended time (say 10 minutes), and maybe shorten the HHVM restart time.
Comment Actions
I'm resolving this task, as there's no followup investigation needed. Agreed with @Joe 's assessment that mitigation is the right approach for now, as we don't really want to be spending cycles on HHVM fixes.