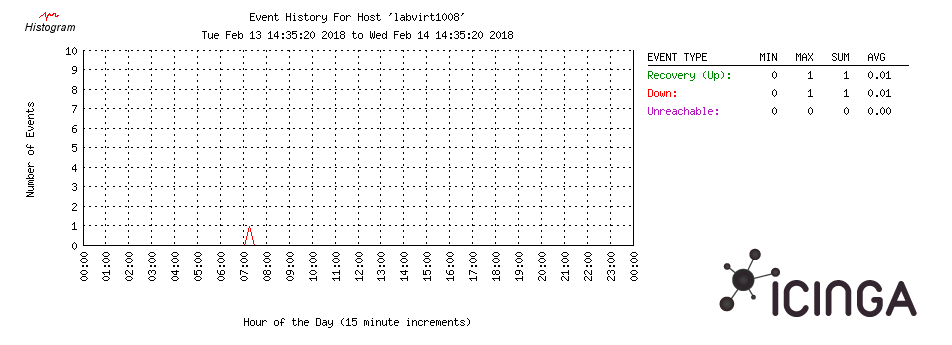
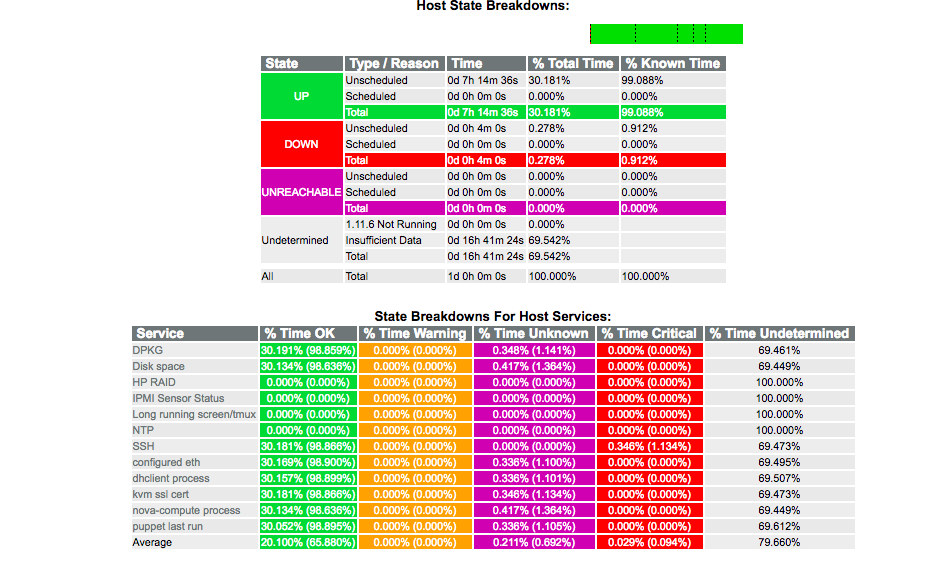
This morning at 7:20 UTC labvirt1008 rebooted. Hardware log shows that the system overheated:
number=8 severity=Critical date=02/14/2018 time=07:10 description=Critical Temperature Threshold Exceeded (Temperature Sensor 21, Location System, Temperature 127C) number=09 severity=Caution date=02/14/2018 time=07:10 description=System Overheating (Temperature Sensor 21, Location System, Temperature 127C) number=10 severity=Critical date=02/14/2018 time=07:11 description=Automatic Operating System Shutdown Initiated Due to Overheat Condition number=11 severity=Caution date=02/14/2018 time=07:20 description=POST Error: 1792-Slot X Drive Array - Valid Data Found in Cache Module. Data will automatically be written to drive array.
Not sure about the best mitigation, maybe some fan died or it needs thermal paste?
https://lists.wikimedia.org/pipermail/cloud-announce/2018-February/000023.html
https://wikitech.wikimedia.org/wiki/Incident_documentation/20180214-labvirt1008-failure