Update: Incident report at https://wikitech.wikimedia.org/wiki/Incident_documentation/20180410-Routing
For about 54min from 22:46 - 23:40 on Tue 10 Apr, a significant amount of global traffic was unable to reach our data centres.
| Varnish traffic (Grafana) |
|---|
 |
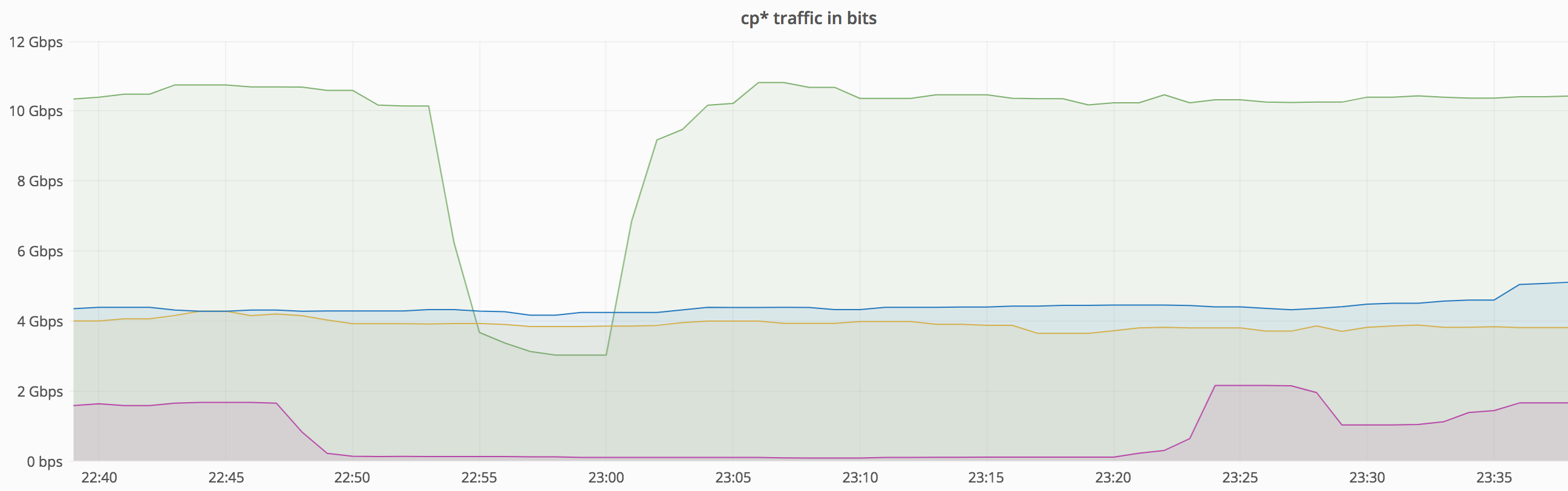 |
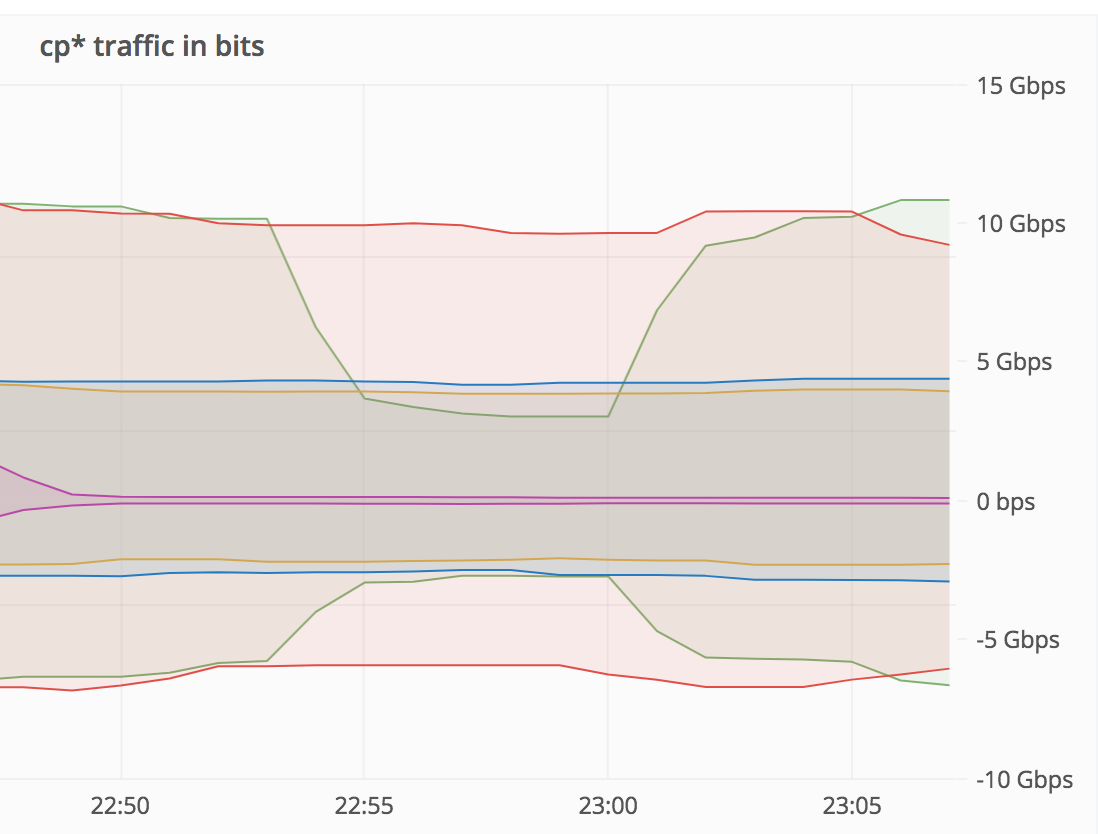
From 22:53 - 23:03 (10min), "Transmission cp10xx (eqiad)" was down 70% (dropped from 10 GBit/s to 3 GBit/s). The bottom lasted for about 5min (22:55 - 23:00).
From 22:46 - 23:24 (40min), "Transmission cp50x (eqsin)" was down 90% (dropped from 1.6 GBits to 0.12 Gbit/s). The bottom lasted about 30min (23:50 - 23:20).
| Edit count (Grafana) |
|---|
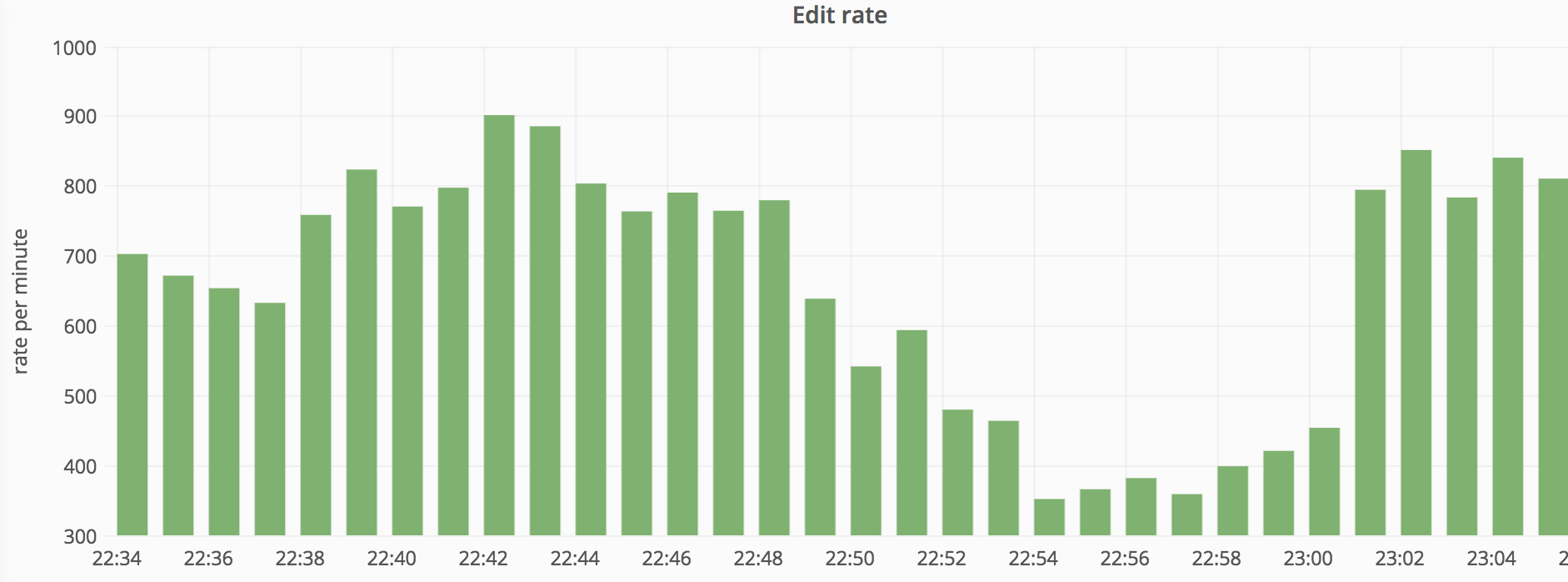 |
| Edit count (global) dropped from 800/min to 350/min (down 56%) |
| Varnish http (Grafana) |
|---|
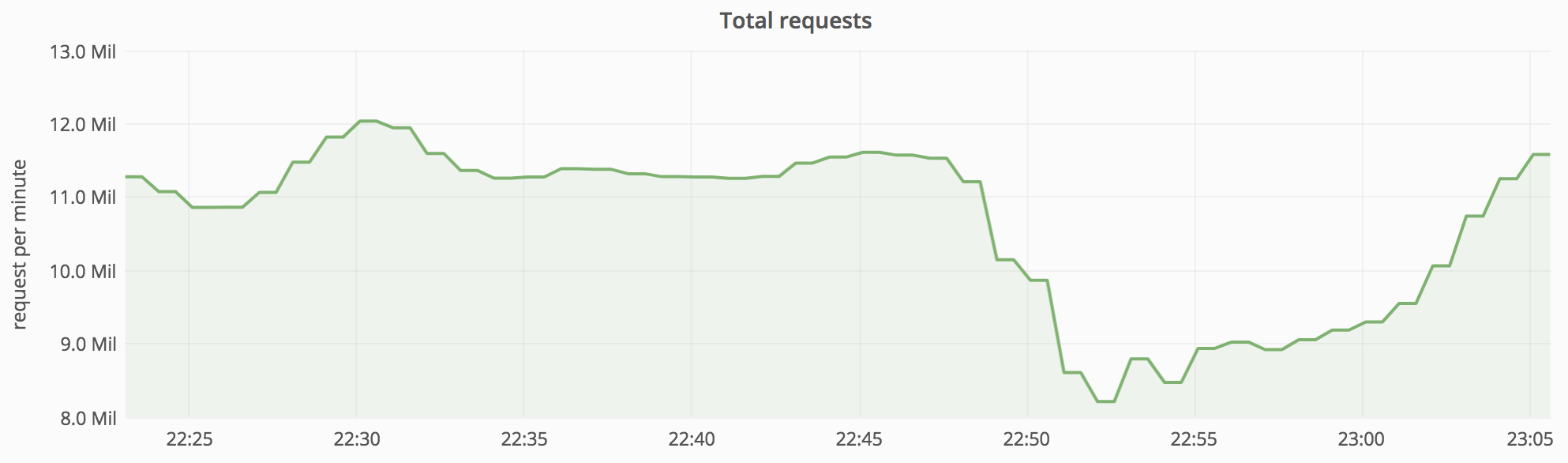 |
| Requests (total) dropped from 11M/min to 8M/min (down 30%) |
| Asia page views (Grafana) |
|---|
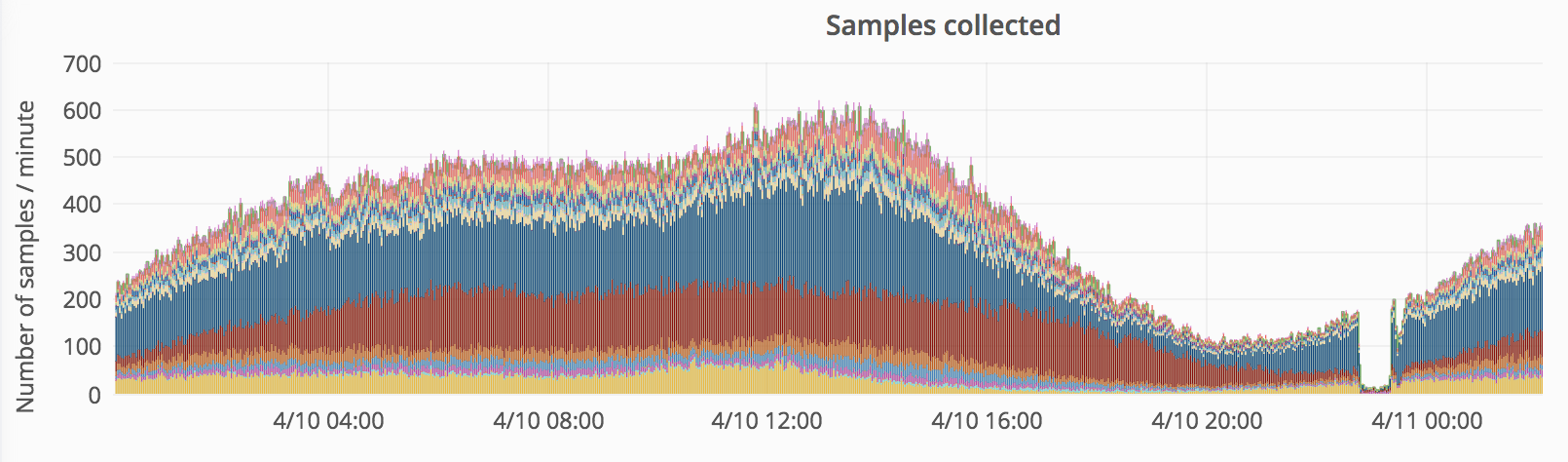 |
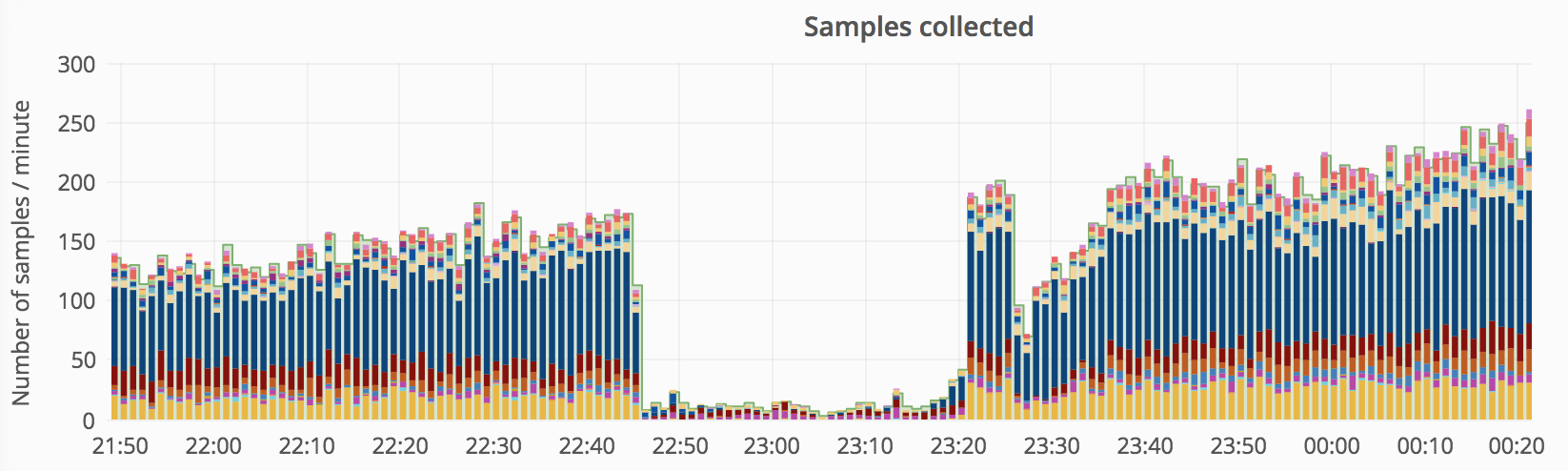 |
| Page views (1:100 samples) dropped from 170/min to <10/min (down 90%). This is based on client-side Geo and indicates that traffic was really down (as opposed to re-routed). |