Looking at Kibana, I see a lot of banned requests marked with wbqc happening on the internal cluster. In the last 4 hours, it's 2,428,030 events (more than 300 per second!). Something is clearly not right there. Needs to be checked what is causing this.
Description
Description
Details
Details
| Subject | Repo | Branch | Lines +/- | |
|---|---|---|---|---|
| Split SPARQL pre and post throttling metrics | mediawiki/extensions/WikibaseQualityConstraints | master | +2 -2 |
Related Objects
Related Objects
- Mentioned In
- T214032: query service should send a retry-after header with a 429 response
T214031: Investigate missing WikibaseQualityConstraints logs in logstash.
T204471: WikibaseQualityConstraints include extension name in UA for query service requests
T204469: WikibaseQualityConstraints should respect query service 429 header response.
T204317: Don’t send SPARQL prefixes with WikibaseQualityConstraints queries - Mentioned Here
- T214031: Investigate missing WikibaseQualityConstraints logs in logstash.
T214032: query service should send a retry-after header with a 429 response
T204022: Add functionality to run QualityConstraint checks on an entity after every edit
T204024: Store WikibaseQualityConstraint check data in persistent storage instead of in the cache
Event Timeline
Comment Actions
Kibana log for banned requests.
Example request:
PREFIX wd: <http://www.wikidata.org/entity/>
PREFIX wds: <http://www.wikidata.org/entity/statement/>
PREFIX wdt: <http://www.wikidata.org/prop/direct/>
PREFIX wdv: <http://www.wikidata.org/value/>
PREFIX p: <http://www.wikidata.org/prop/>
PREFIX ps: <http://www.wikidata.org/prop/statement/>
PREFIX pq: <http://www.wikidata.org/prop/qualifier/>
PREFIX pqv: <http://www.wikidata.org/prop/qualifier/value/>
PREFIX pr: <http://www.wikidata.org/prop/reference/>
PREFIX prv: <http://www.wikidata.org/prop/reference/value/>
PREFIX wikibase: <http://wikiba.se/ontology#>
PREFIX wikibase-beta: <http://wikiba.se/ontology-beta#>SELECT (REGEX("533892", "^(?:[1-9][0-9]+|)$") AS ?matches) {}&format=json&maxQueryTimeMillis=5000Also I must notice about 90% of the text of this request is prefixes which are already defined by default...
Comment Actions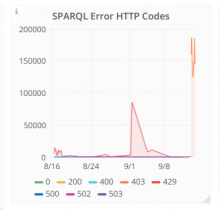
Seems the Wikibase-Quality-Constraints extension is the source:
https://grafana.wikimedia.org/dashboard/db/wikidata-quality?refresh=10s&orgId=1&from=now-30d&to=now
It seems SPARQL error codes increased drastically
Comment Actions
Quick investigation shows that the increase in sparql requests is likely due to the 4x/5x increase in API requests (there was 10x increase at the peak of the spike).
Looking at the web requests most requests seem to be coming from a single UA / IP. so lets aim to block those requests.
{P7547}
Comment Actions
Tagging operations as we want to block / stop these requests.
/ Figure out what's causing them
Comment Actions
Mentioned in SAL (#wikimedia-cloud) [2018-09-14T10:51:35Z] <arturo> T204267 stop the openrefine-wikidata tool (k8s) because is hammering the wikidata API
Comment Actions
@aborrero thanks for the ping. I do not recognize the shape of the queries as coming from this tool though. The openrefine-wikidata tool should do relatively few SPARQL queries, whose results are cached in redis. How did you determine that this tool is the source of the problem?
Comment Actions
Sorry for the noise, after stopping your tool we still see the same traffic. Feel free to restart your tool and again: sorry.
Problem is that we can't identify the tool by the server logs because there isn't any meaningful UA, so we are walking a bit blind. Your tool had the wikidata name in it, so that was the first candidate.
Comment Actions
Mentioned in SAL (#wikimedia-cloud) [2018-09-14T11:22:34Z] <arturo> T204267 stop the corhist tool (k8s) because is hammering the wikidata API
Comment Actions
We stopped now the corhist tool which belongs to @Tpt, please check the tool. Now that the tool has been terminated, the traffic in wikidata seems back to normal.
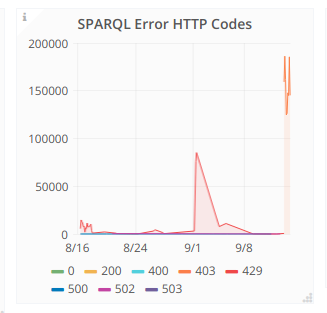
Comment Actions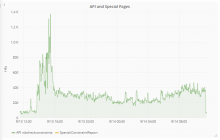

The API request rate has returned to a normal level:
As have the SPARQL error codes being hit by the WBQC extension.
The rate of wdqs queries being banned / throttled is also down:
The situation here in the future will likely be better once we can run these in the job queue T204022 and once we can store them more persistently T204024
@Smalyshev do we have to manually unban localhost somewhere to get quality constraints sparql requests back or will that happen automatically? (I'll assign you for this 1 remaining open question, otherwise we can probably close this ticket)
Comment Actions
Sorry everyone for the troubles. I was experimenting with a tool that tries to find corrections for constraint violations.
I have modified it to send a proper User-Agent for all its requests to the Wikidata API but not restarted it.
@Wikidata team: what would be an ok request rate to the constraints violation API? The alternative options for me from using the WikibaseQuality API does not look very compelling:
- look directly for violations from WDQS but it's probably not much better in term of load for the query service and it won't use any cache implemented by WikibaseQuality.
- use its own WDQS but it means to find an other hosting than tools labs.
Comment Actions
@Tpt is it necessary for your tool to run the constraint checks in parallel?
Using WDQS instead would be a good idea, because then only your tool would get throttled.
The problem there is that just a fraction of all violations are in there at the moment.
Comment Actions
@Jonas Thank you for your feedback.
is it necessary for your tool to run the constraint checks in parallel?
No, I am going to switch to a sequential processing. Thanks for the idea!
Using WDQS instead would be a good idea, because then only your tool would get throttled.
It's what I already do to start filling my database. And I was using the recent changes to get the "most recent" violations i.e. the ones that the users are probably the most willing to fix and that have an higher probability to be vandalism. I just restarted the tool and I now only use WDQS and some calls to the QualityApi to get the conflict labels, but only at a 1/s rate.
Comment Actions
All bans are temporary, so as soon as traffic returns to normal the bans will expire. It would be nice if there was a way to wbqc to respect the 429 throttling header, which will avoid bans.
Comment Actions
That sounds like a great idea that could do with some thought, I'll file a ticket.
Is Retry-after always provided?
Comment Actions
Is Retry-after always provided?
Yes, as far as I know WDQS will always do it on throttling. If you notice it doesn't it's a bug, please tell me.
Comment Actions
It looks like there was another little flood on the 1st of October with requests being banned again:
https://logstash.wikimedia.org/goto/77f3d01f6e7eaf56e5436727b5643ba2
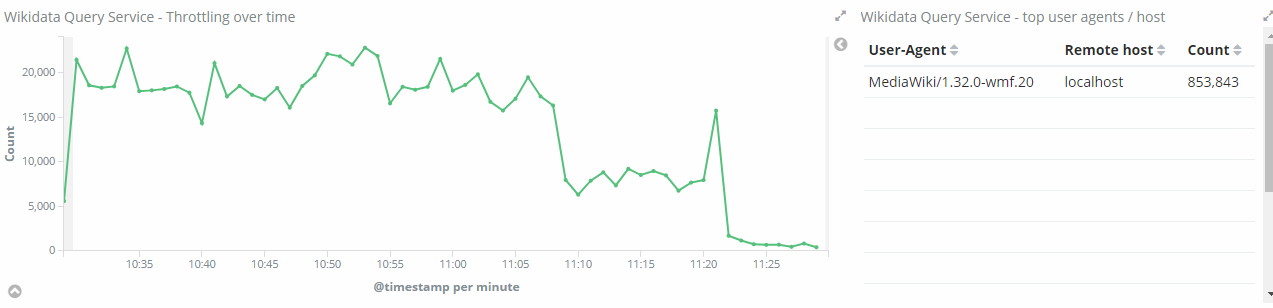
Is there a reason that all mediawiki hosts show as "localhost"?
Comment Actions
Is there a reason that all mediawiki hosts show as "localhost"?
This is probably coming from Jetty, which takes it from connection info. Since we have nginx in front of the Blazegraph and no X-Client-IP is supplied, probably, it has no way to discover the originating host.
Comment Actions
Also, 1,182,961 events is a lot. What's going on there? Why so many? Is it a legit scenario? I wonder also if the most of it is regex matching shouldn't we make some service to do just that. Using full-blown SPARQL database to do regex matching is kinda like hammering in nails using a last-generation cell phone.
Comment Actions
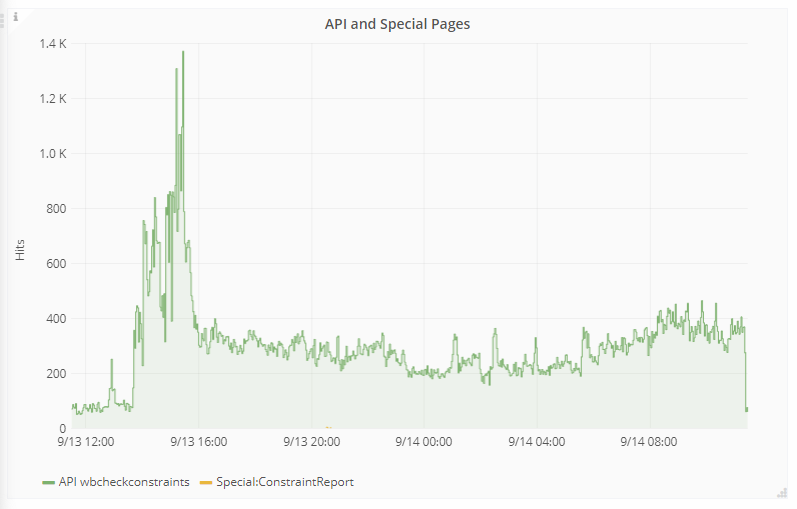
The spike can be seen here
It doesn't look like there was a bit spike in hits to the api or special pages.
There was a big spike in the regex cache misses here.
Comment Actions
Change 483112 had a related patch set uploaded (by Addshore; owner: Addshore):
[mediawiki/extensions/WikibaseQualityConstraints@master] Split SPARQL pre and post throttling metrics
Comment Actions
Change 483112 abandoned by Addshore:
Split SPARQL pre and post throttling metrics
Reason:
This can probably be done with the metrics we already have..
Comment Actions
So the spike reported again above was before https://gerrit.wikimedia.org/r/#/c/mediawiki/extensions/WikibaseQualityConstraints/+/464812/ was merged and deployed.
WBQC now respects the 429 header and will throttle based on it.
I added a new panel to https://grafana.wikimedia.org/d/000000344/wikidata-quality so that we can see this along side the http responses from the query service for WBQC.
I also created https://gerrit.wikimedia.org/r/#/c/mediawiki/extensions/WikibaseQualityConstraints/+/483112/ and then abandoned it (to split this metric between pre request and post request), i'm not sure if we need this as we can already calculate this based on # of throttle attempts - # requests that result in 429 = # of requests that were totally avoided due to throttling.
While digging into this again I went to look at how the throttling was performing and found that there were some occurrences of "Sparql API replied with status 429" in the log,
but they don't seem to have a valid retry-after header.
It doesn't look like the query service is returning a valid retry-after header?
So right now WBQC will be just waiting for 10 seconds per the default setting of the WBQualityConstraintsSparqlThrottlingFallbackDuration
An example log entry can be seen @ https://logstash.wikimedia.org/app/kibana#/doc/logstash-*/logstash-2018.12.30/mediawiki?id=AWgAckPBzpjgITg61Cm8&_g=h@4e853bb
which says the headers were:
{"server":["nginx\/1.13.6"],"date":["Sun, 30 Dec 2018 18:48:34 GMT"],"content-type":["application\/octet-stream"],"connection":["close"],"cache-control":["no-cache"]}The WBQC code is specifically looking for 'Retry-After' currently case sensitive.
Comment Actions
Moving from High to Normal based on the comments above.
Can promote if this happens again
Comment Actions
So there was another flood in the past 48 hours.
This can be seen on the WBQC dashboard @ https://grafana.wikimedia.org/d/000000344/wikidata-quality?orgId=1&from=1547564623742&to=1547573021473
I had a quick look in turnilo and this spike was from a single user
WBQC logged a bunch of 429s again and correctly backed off:
2019-01-15 15:27:10 [XD37zApAMEAAAFaniE4AAAAF] mw1229 wikidatawiki 1.33.0-wmf.12 WikibaseQualityConstraints WARNING: Sparql API replied with status 429 and no valid retry-after header. {"responseHeaders":"{\"server\":[\"nginx\\/1.13.6\"],\"date\":[\"Tue, 15 Jan 2019 15:27:10 GMT\"],\"content-type\":[\"application\\/octet-stream\"],\"connection\":[\"close\"],\"cache-control\":[\"no-cache\"]}","responseContent":"Rate limit exceededAlthough WDQS did not add an amount of time to the retry-after response as previously reported in T204267#4865669 and now filed as T214032
Also these logs seemed to not appear in logstash this time, which I have filed as T214031 (as I am slightly confused).
This now means that the requests no longer get banned as well, https://grafana.wikimedia.org/d/000000489/wikidata-query-service?panelId=23&fullscreen&orgId=1&from=1547564623742&to=1547573021473&edit&var-cluster_name=wdqs
Only throttled https://grafana.wikimedia.org/d/000000489/wikidata-query-service?orgId=1&from=1547555327023&to=1547581779508&var-cluster_name=wdqs-internal&panelId=31&fullscreen
So, although floods can still happen, WBQC respects the responses of the query service and will back off, resulting in no overload / banned requests.
I think we can close this now? :)