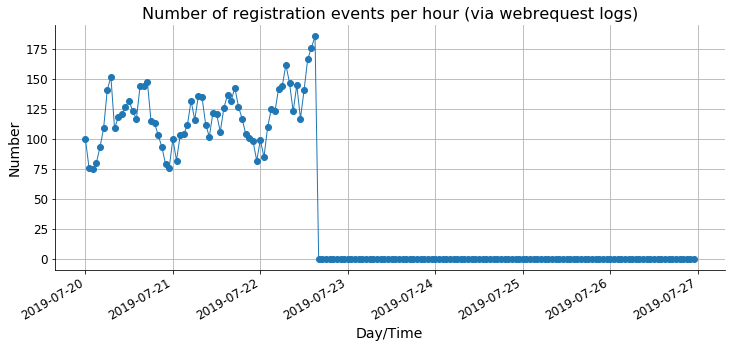
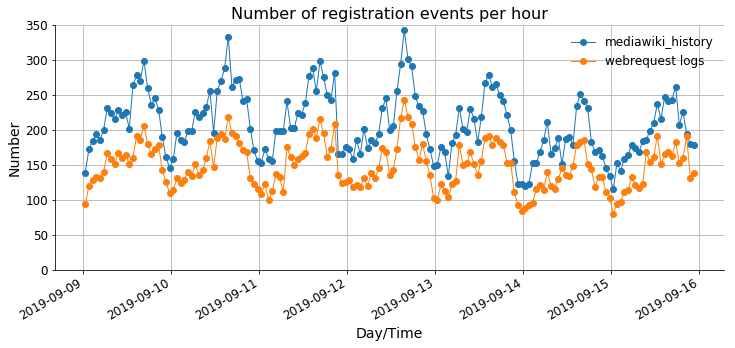
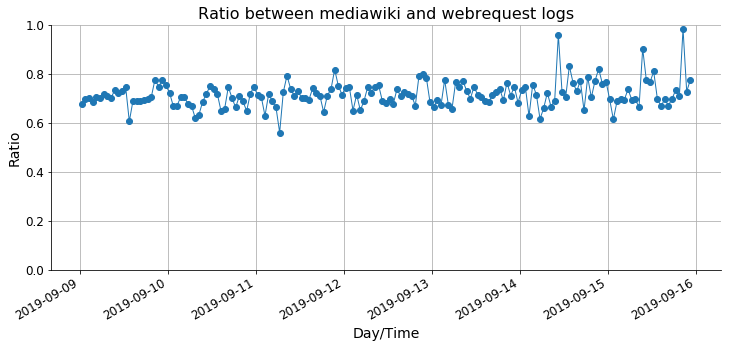
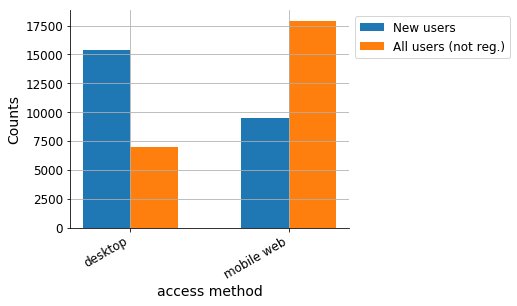
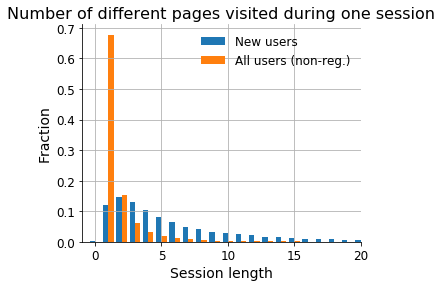
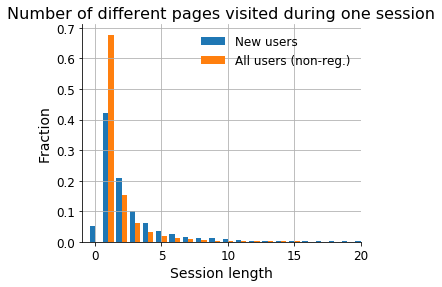
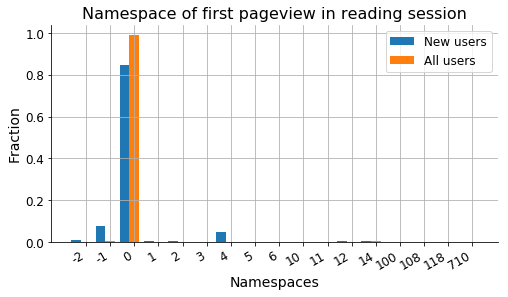
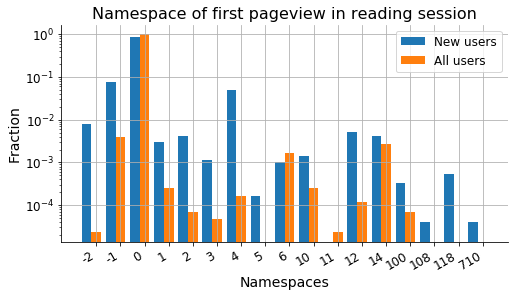
Aim: Understand reading patterns of new users. What motivates users to create accounts. Note that this is a project as part of @MGerlach 's onboarding to become familiar more familiar with WMF-datasets. Here, the focus is on the webrequest logs.
What
- Identify new users. For example, new user is someone who clicked 'Create Account' button
- Extract reading visited pages before and after registration via webrequest logs
- Extract features of pages, e.g. namespace, topic, length, popularity
- Extract patterns of reading patterns
- embedding in lower dimensional space
- are there clsuters?
- can we interpret the clusters?
Begin with 1 (small) wiki-project.
Some context from earlier discussions with Jon Katz that can be helpful in Martin's thinking and direction. (We don't need to attempt to address the questions below. They may be longer term.) --Leila
Nice-to-have
- Which parts of the current Desktop experience are key in turning readers to contributors or deepening the reading experience and should not be removed/hid as part of the refresh?
- Can we characterize account creations?
- Can we characterize the first edit?
- ...
Higher priority
- Characterize the account who edit with the hope of gaining a deeper understanding about the characteristics of readers. (Consider repeating Why We Read Wikipedia? as Why We Edit Wikipedia?)
- Is there anything causal going on? For example, is there a way to train readers to become editors? (beyond editathons and ongoing initiatives by the community). We may not necessarily want to do this, but we want to understand what our options are.