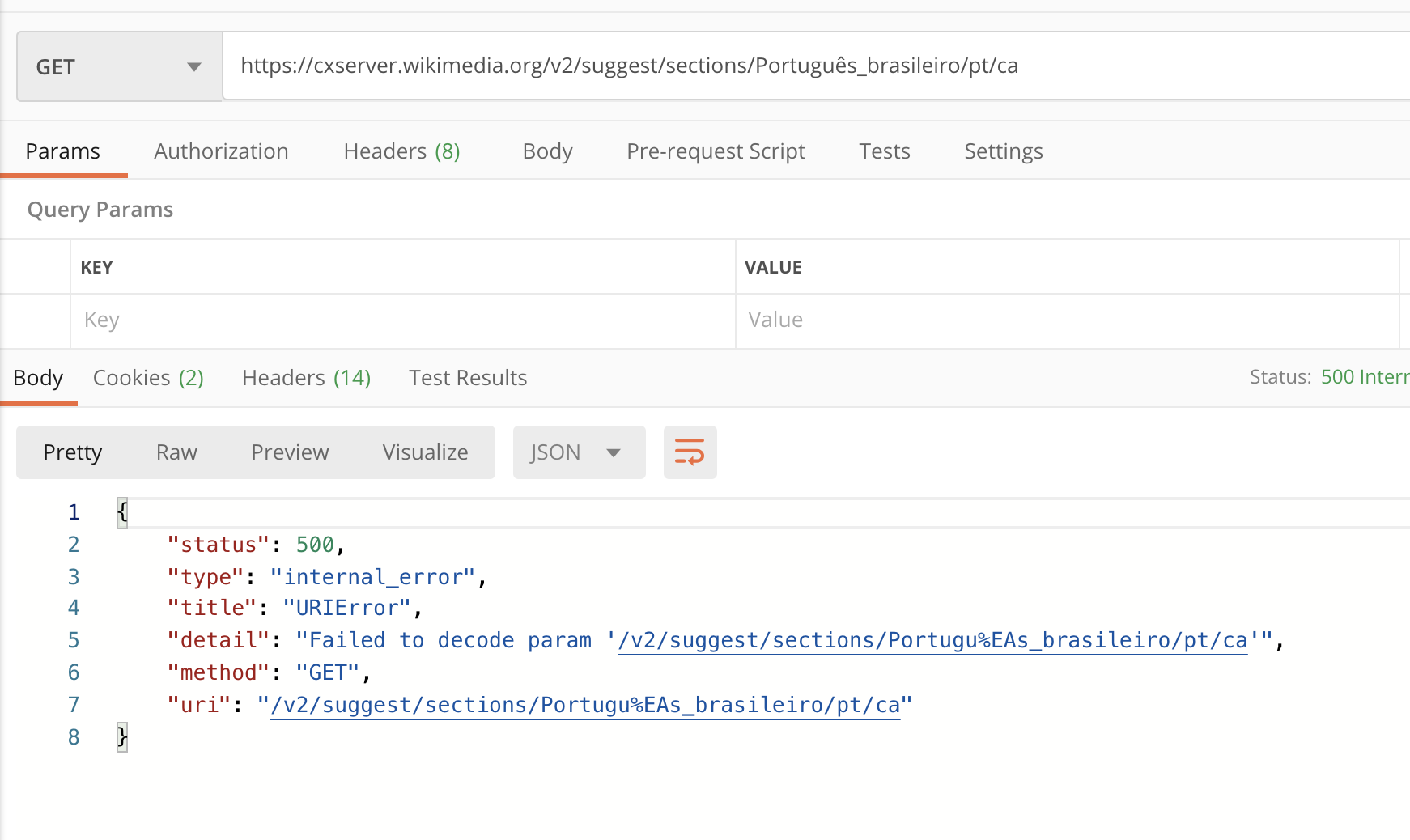
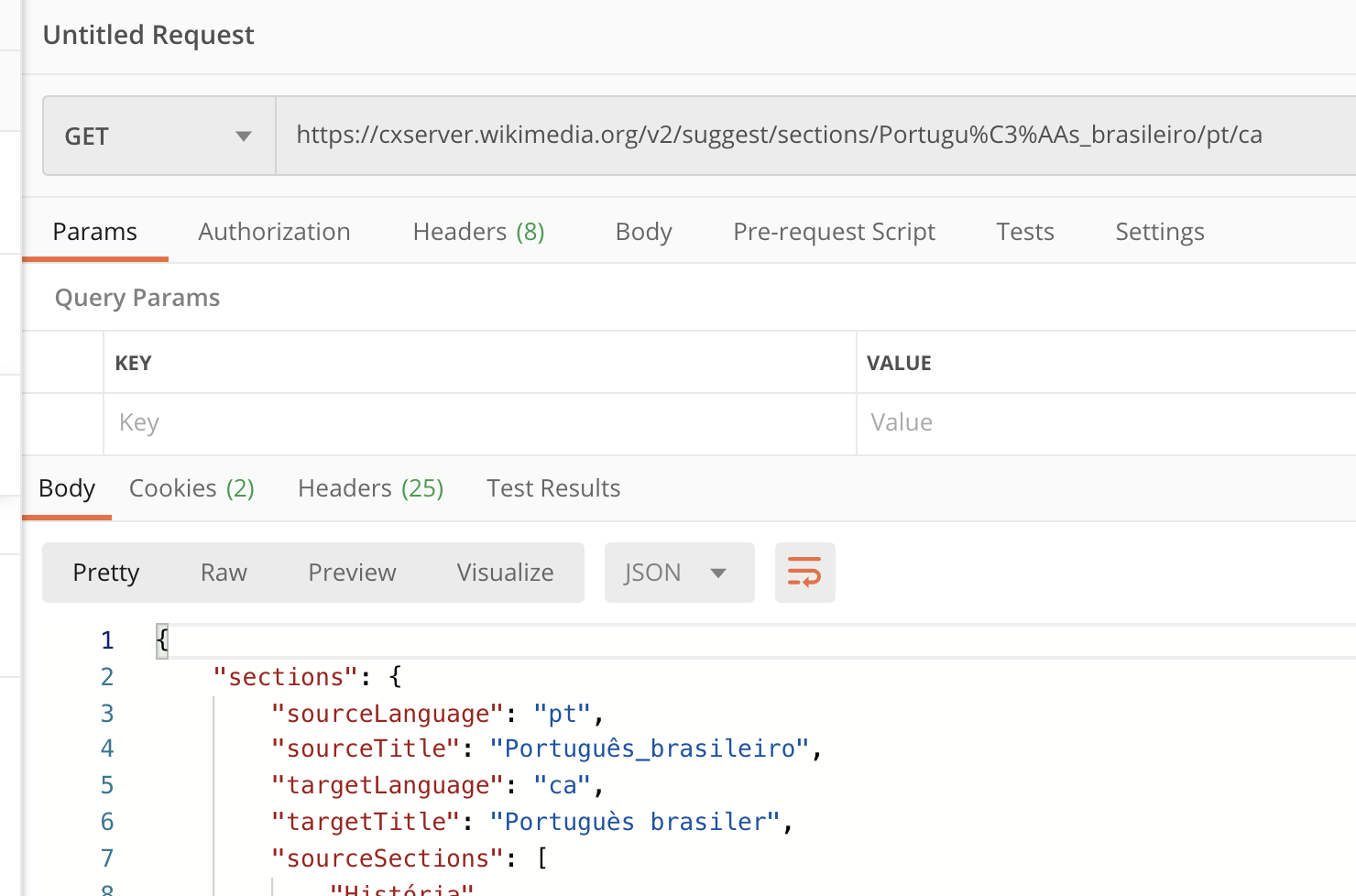
The section suggestion feature of cxserver is based on the database of section title pairs prepared from all the translations in Content Translations. This was prepared more than an year ago, and we have bigger and latest CX Corpus dumps.
Updating the database will help better section title suggestions