Since approximately 3:20am UTC, the amount of 5XX responses as monitored on Wikimedia CDNs shows an increase in rate, from 1-2 per second to 20-30 per second:
(please ignore the spike from 5:40-5:55, that was an unrelated outage T307647)
Looking at logstash logs, the source of the errors seem to be maps:
(error rates without maps included)

(only error rates of maps)

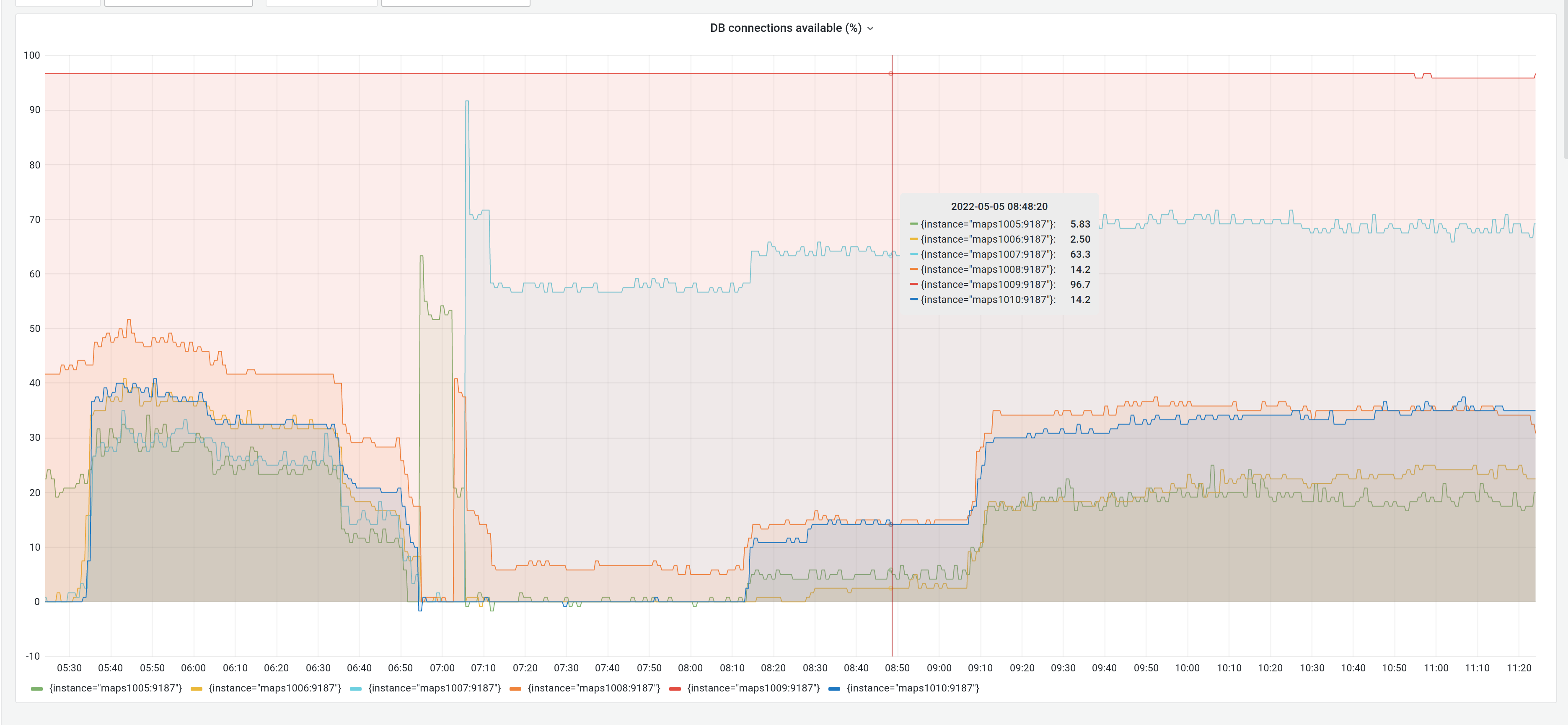
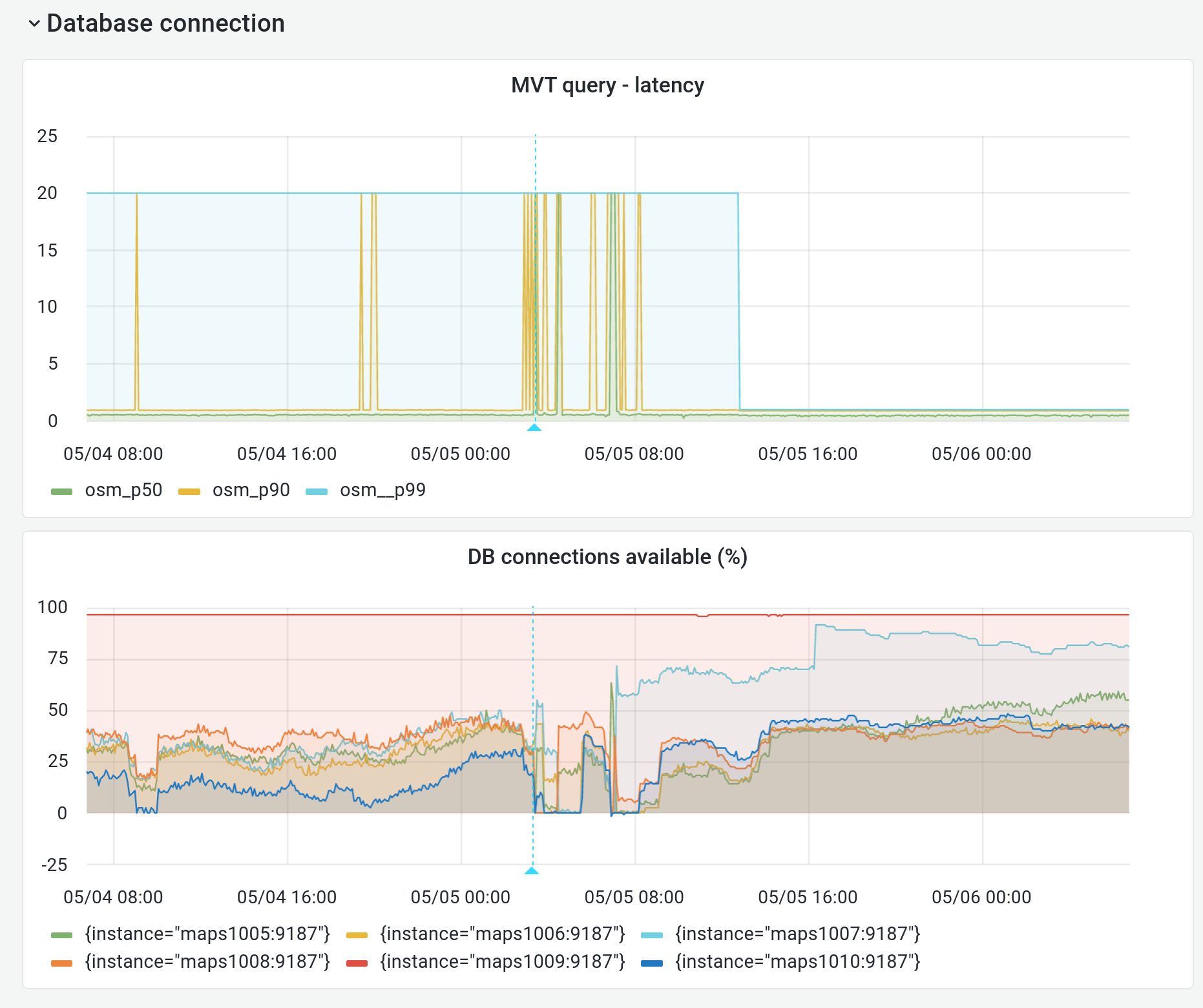
Dashboards seem worrying and not normal regarding maps performance (increased load and IO):