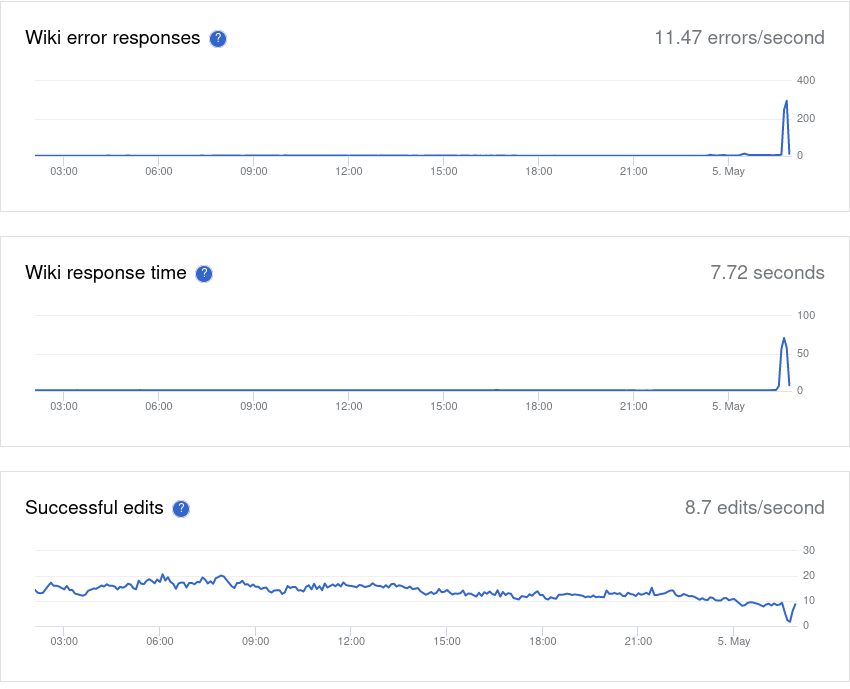
Wikimedia wikis were down from ~5:40 to 5:54 because of a faulty schema change.
| AlexisJazz | |
| May 5 2022, 5:43 AM |
| F35104269: Screenshot 2022-05-05 at 02-02-59 Wikimedia Status.png | |
| May 5 2022, 6:04 AM |
Wikimedia wikis were down from ~5:40 to 5:54 because of a faulty schema change.
| Status | Subtype | Assigned | Task | ||
|---|---|---|---|---|---|
| Resolved | BUG REPORT | • Marostegui | T307647 2022-05-05 Wikimedia full site outage | ||
| Resolved | • Marostegui | T307501 Adjust the field type of globalblocks timestamp columns to fixed binary on wmf wikis | |||
| Resolved | • Marostegui | T308126 Migrate a s7 DB host to mariadb 10.6 | |||
| Resolved | Ladsgroup | T307648 Audit database usage of GlobalBlocking extension |
This was due to an outage, we identified and fixed the root cause around 5-10 minutes ago and we should be ok now.
We are now investigating why the outage happened in the first place
As the description was overwritten: it didn't break instantly and maybe it was never strictly down, just too slow to work. For me it was extremely slow for a few minutes or so first (taking 20s to load a page) until finally I saw "upstream connect error or disconnect/reset before headers. reset reason: overflow".
Btw, Phabricator was up and performing normally, as was beta cluster. https://foundation.wikimedia.org/wiki/ was down, as was enwiki and metawiki.
Updating this task - cross posting from the original schema change task:
This query seemed to be the one that got stuck
SELECT /* MediaWiki\Extension\GlobalBlocking\GlobalBlocking::getGlobalBlockingBlock */ gb_id,gb_address,gb_by,gb_by_wiki,gb_reason,gb_timestamp,gb_anon_only,gb_expiry,gb_range_start,gb_range_end FROM `globalblocks`WHERE (gb_range_start LIKE '5B85%' ESCAPE '`' ) AND (gb_range_start <= '5B85B2D2') AND (gb_range_end >= '5B85B2D2') AND (gb_expiry > '20220505012805');
However the explain output (and the optimizer trace) shows no difference on query plans between the original schema change and the new one (T307501)
@AlexisJazz Full doc will come later, but for clarification, the impact was the following:
A most recent test on one of the most affected hosts during the outage, does show a different query plan:
Just for greater visibility and awareness, there is T301505 for the upstream connect error or disconnect/reset before headers. reset reason: overflow". error. As pointed out in that task that error message is a symptom and not the cause.
I am going to close this as fixed. The incident report is at https://wikitech.wikimedia.org/wiki/Incidents/2022-05-05_Wikimedia_full_site_outage (still flagged as draft but pretty much finished)