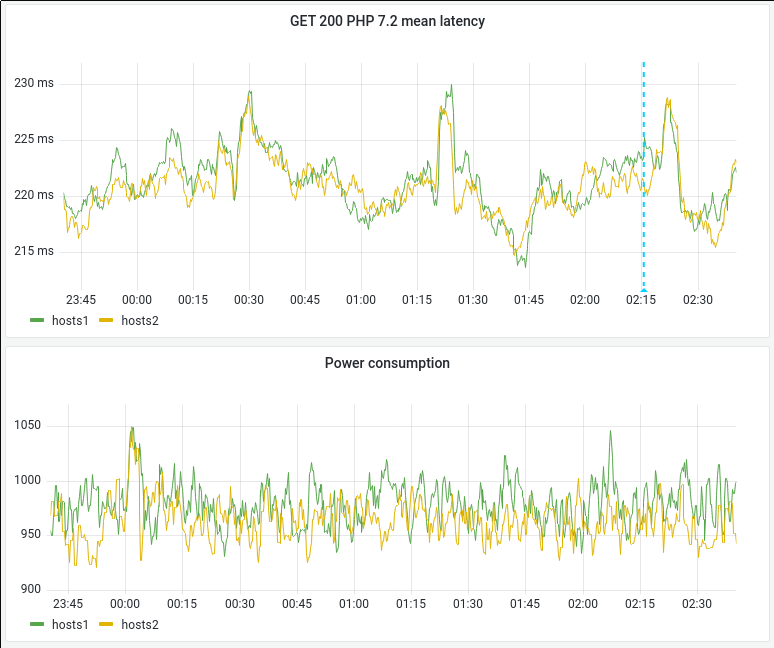
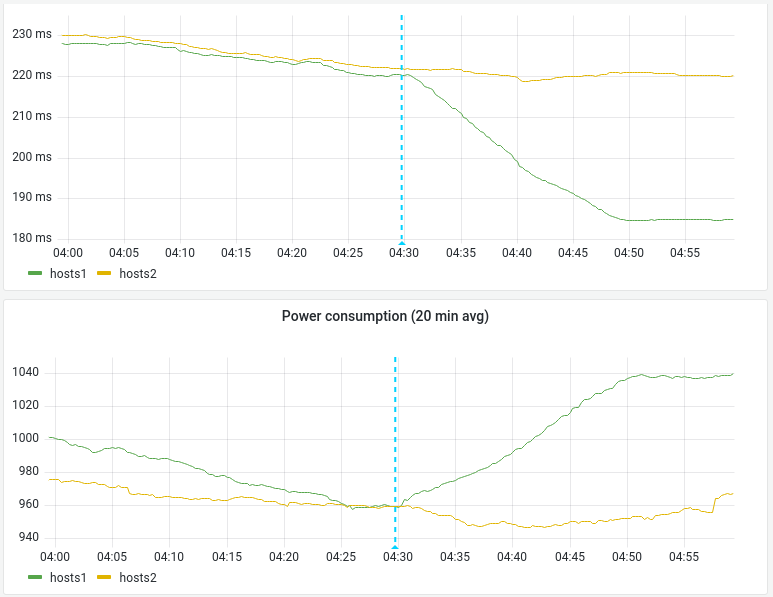
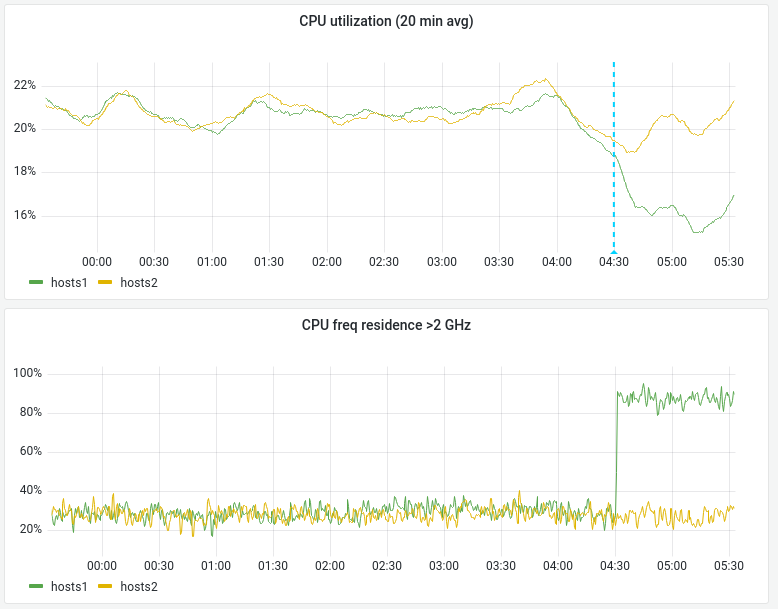
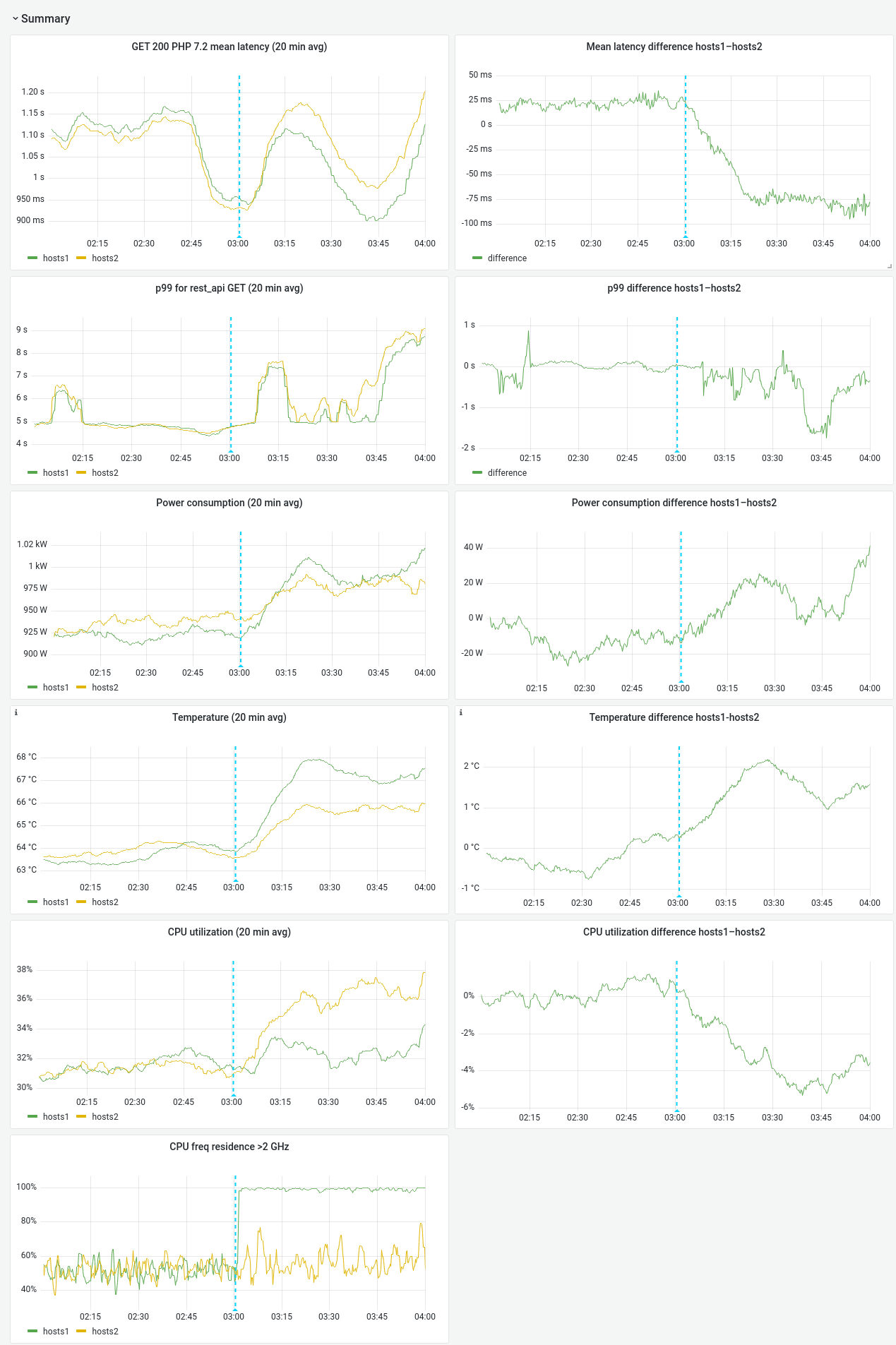
My experiment on a single depooled server indicated that a significant benefit to end-user latency might occur if we set scaling_governor to performance on MW appservers.
I propose making this change on all eqiad appservers in soft state, with cumin. Our latency metrics are noisy so changing it everywhere at once will give us the best chance of measuring a benefit.
We don't collect per-server power usage for these servers, but we can look at power usage at higher levels of aggregation. We can use the power usage data to calculate the cost of this change.
If a cost/benefit analysis supports the change, we can puppetize it.