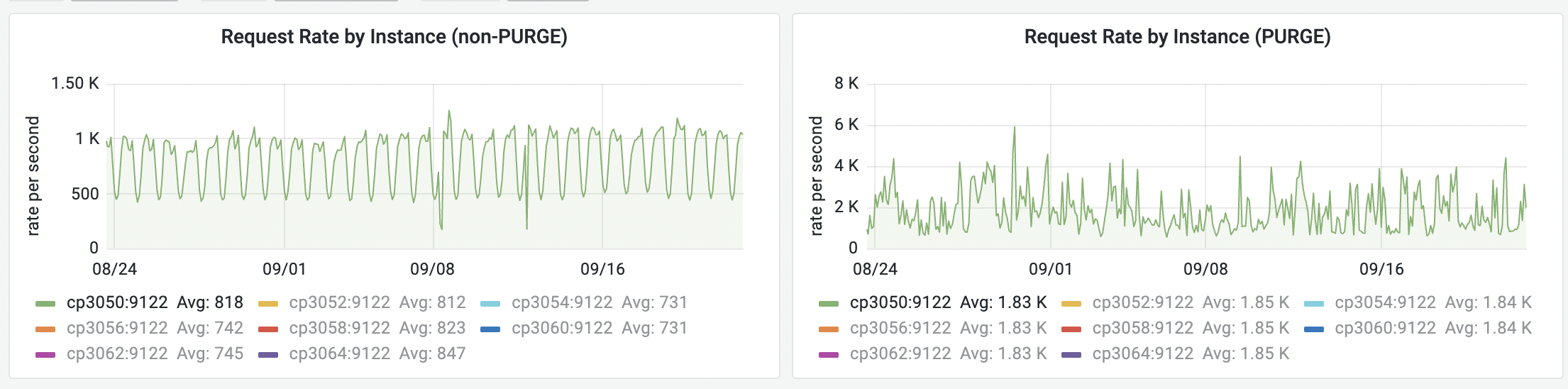
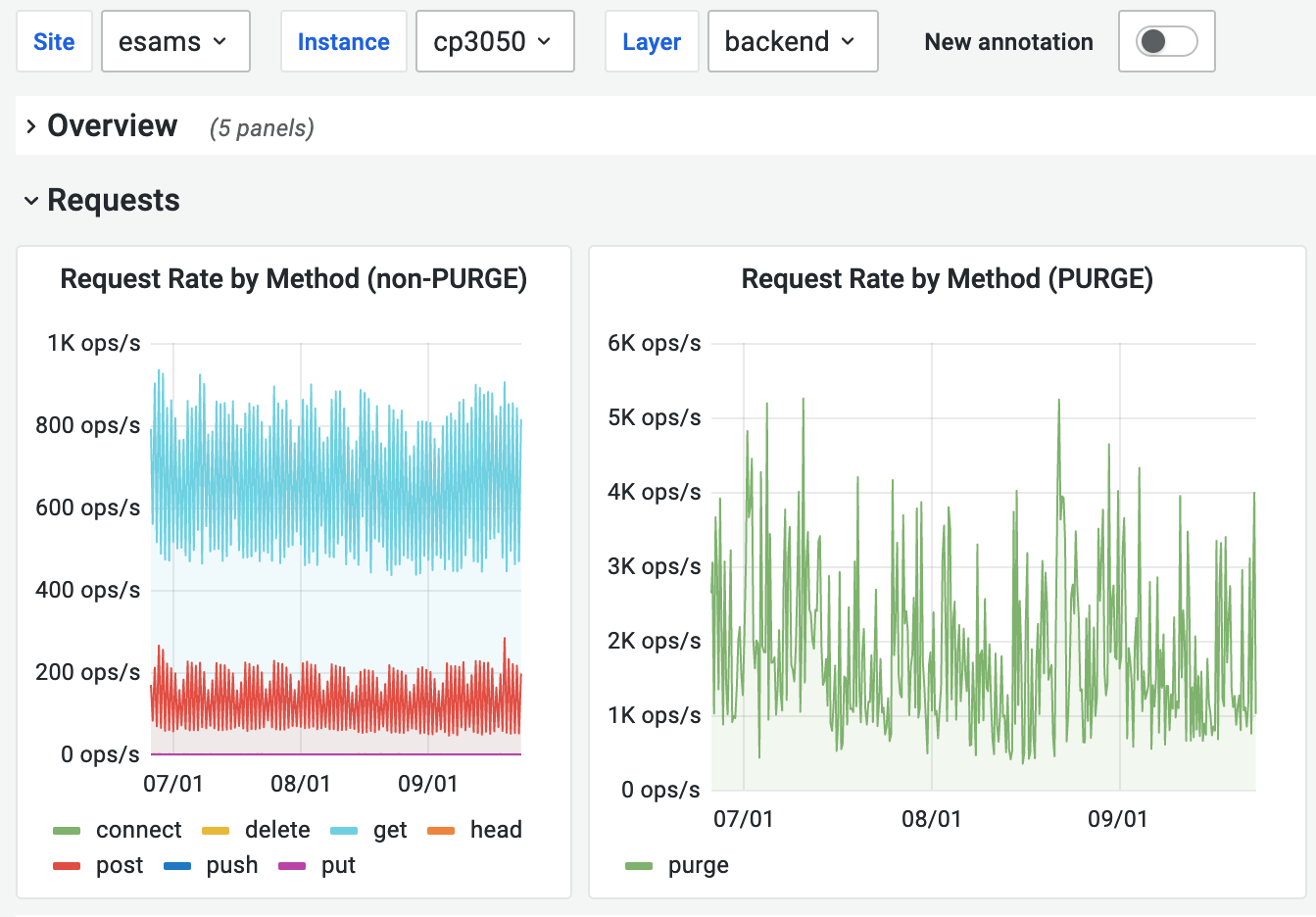
Varnish/ATS are processing on average 1.8k PURGE requests per second on the text cluster. To put this into perspective, ATS handles more PURGE requests than GETs per server on any DC and it's not uncommon to see PURGE requests matching and exceeding the volume of GET requests being handled by varnish in a busy DC like eqiad
An initial 60 seconds capture on one of the test host showed the following top 10 hostnames:
sort purge.log |uniq -c | sort -rn | head -10 52670 commons.wikimedia.org 34983 commons.m.wikimedia.org 34533 tr.wikipedia.org 25459 en.wikipedia.org 9296 en.m.wikipedia.org 1710 de.wikipedia.org 1584 www.wikidata.org 1446 m.wikidata.org 990 uk.wikipedia.org 825 fr.wikipedia.org
A following 300 seconds capture on the same host shows
$ sort purge.log |uniq -c | sort -rn | head -10 91377 en.wikipedia.org 54596 he.wikipedia.org 15094 en.m.wikipedia.org 10590 www.wikidata.org 10590 m.wikidata.org 9060 he.m.wikipedia.org 8972 commons.wikimedia.org 8434 fr.wikipedia.org 8016 pl.wikipedia.org 7230 de.wikipedia.org
non-PURGE requests VS PURGE requests hitting ats@cp3050 during the last 30 days: