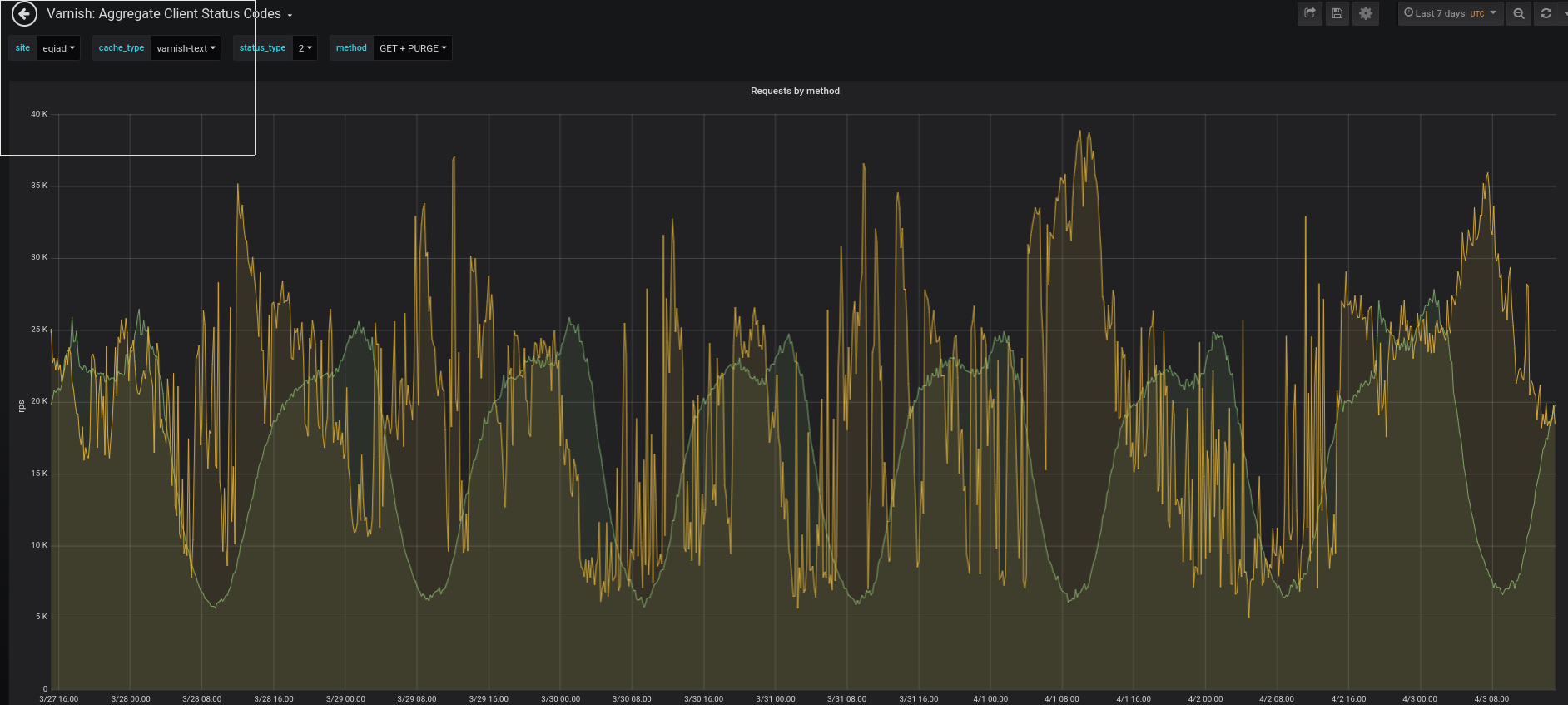
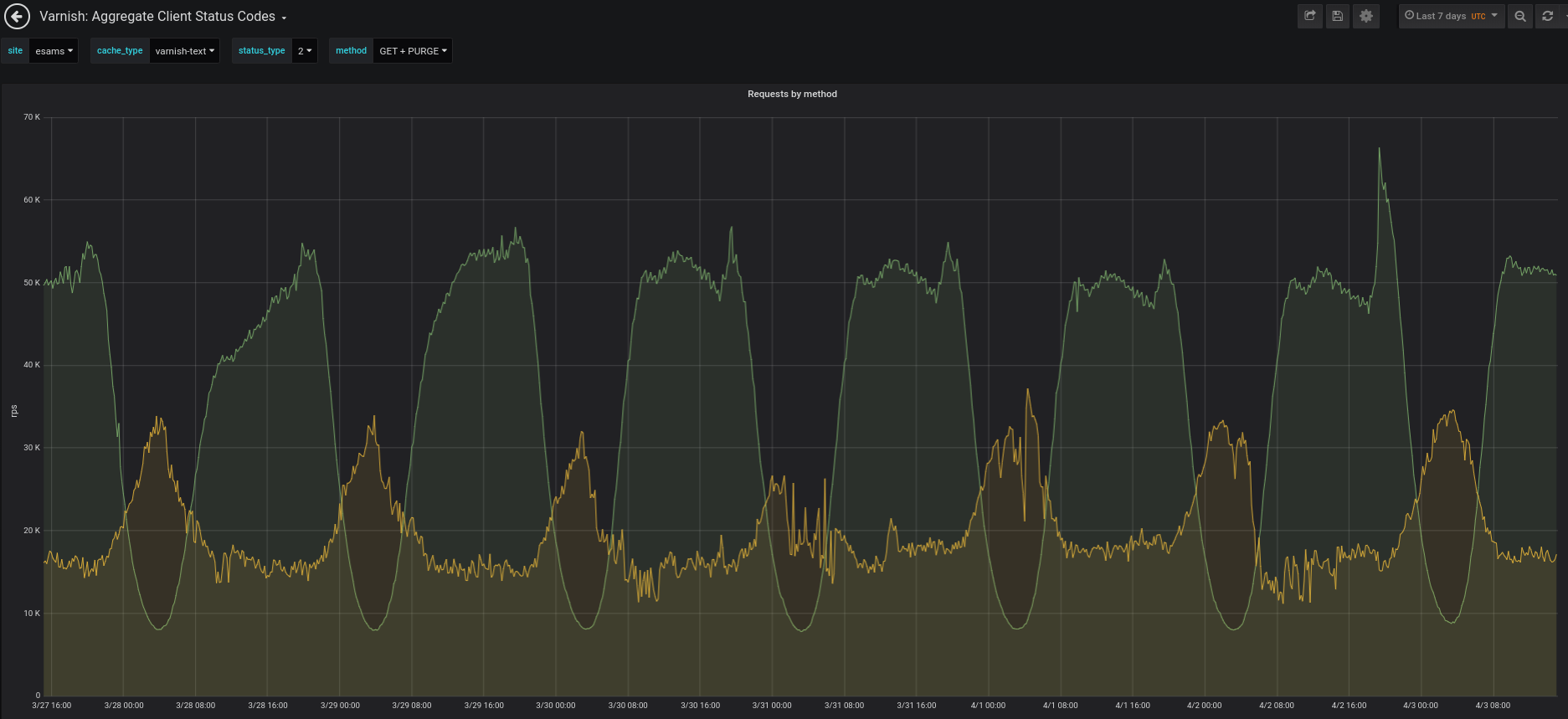
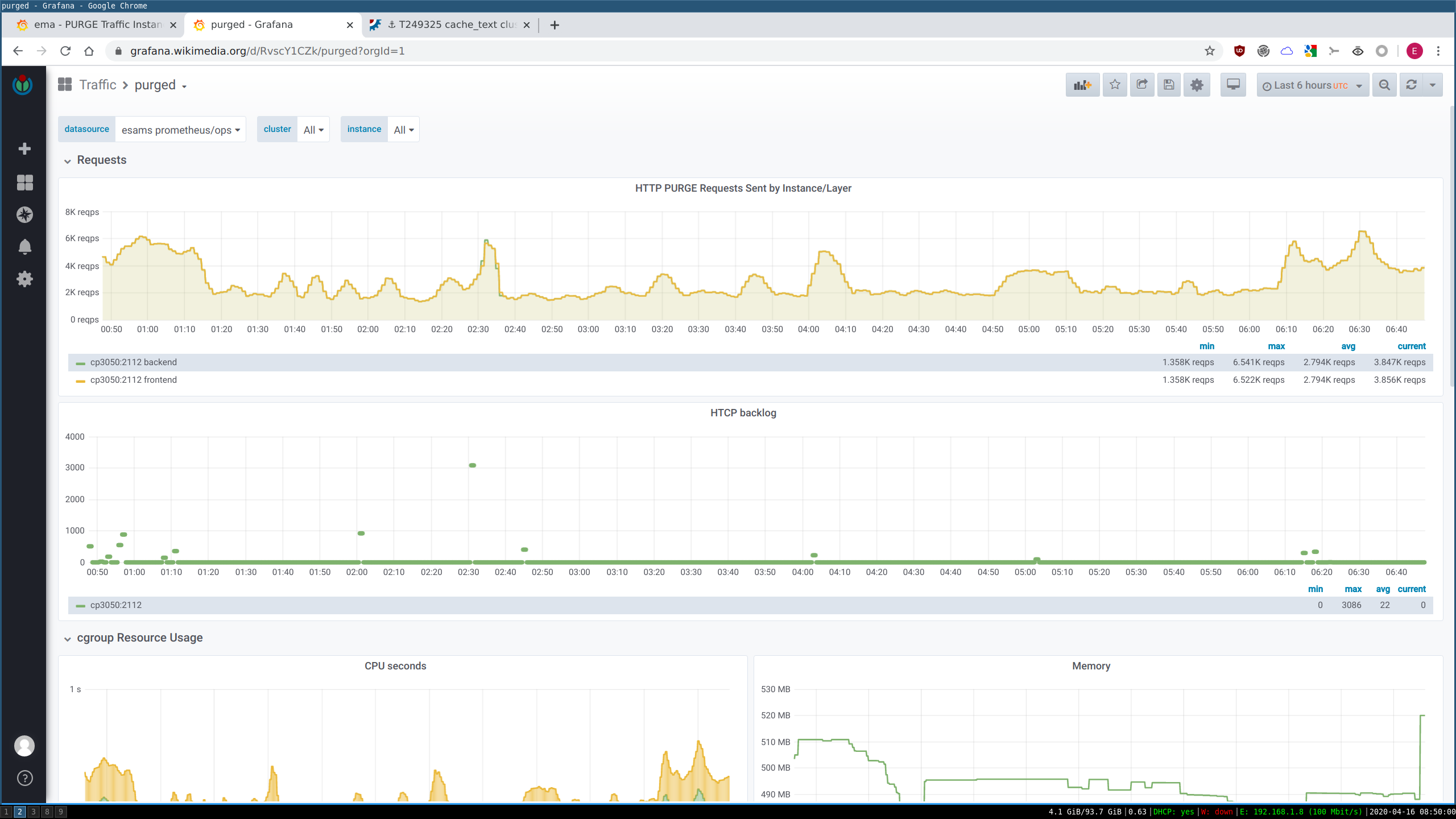
Purging queues are often backlogged in all datacenters, and in esams they are persistently backlogged. (Other locations tend to recover on their own, but esams is so loaded this doesn't happen there.)
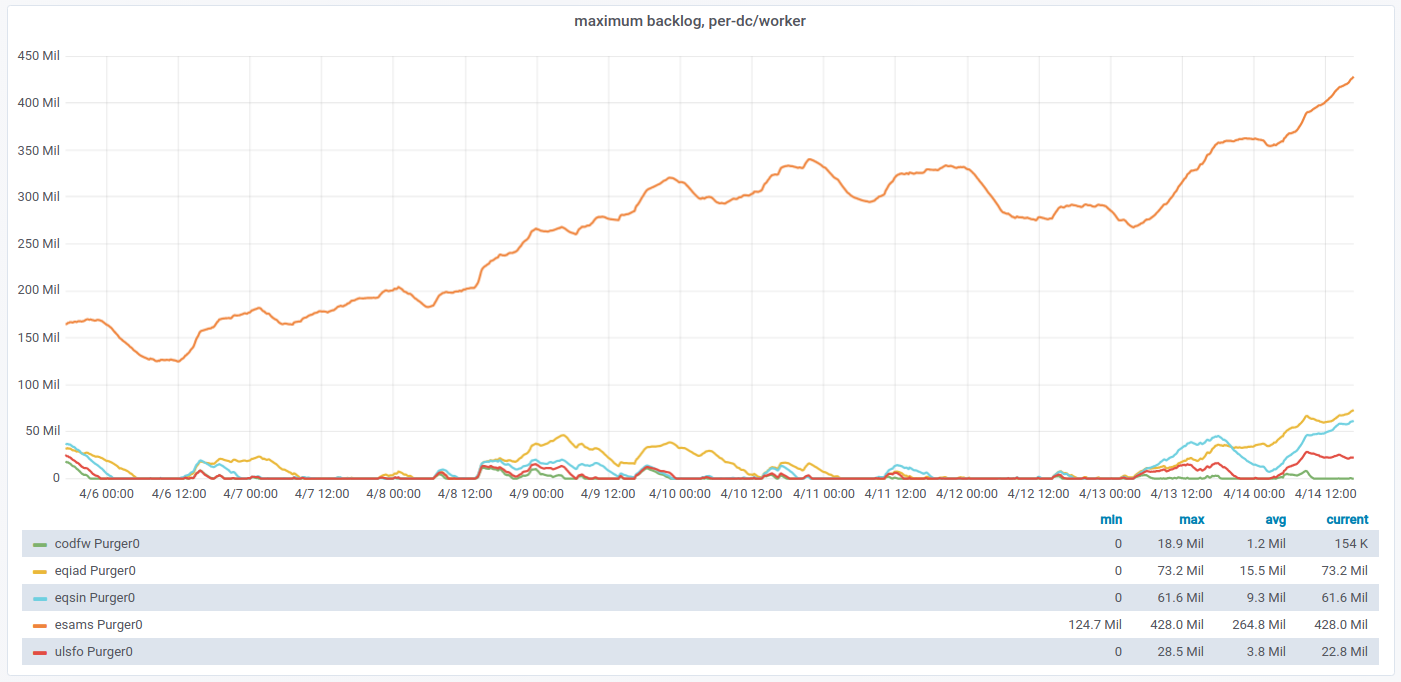
https://grafana.wikimedia.org/d/wBCQKHjWz/vhtcpd?orgId=1&from=now-7d&to=now&var-datasource=esams%20prometheus%2Fops&var-cluster=All&var-worker=Purger0&fullscreen&panelId=4
Work is ongoing in T249583: Create vhtcpd replacement to build and ship a newer, more scalable purged daemon to issue purges in parallel instead of serially. There's also T250205: Reduce rate of purges emitted by MediaWiki to lower the number of them, because as-is it's quite excessive.