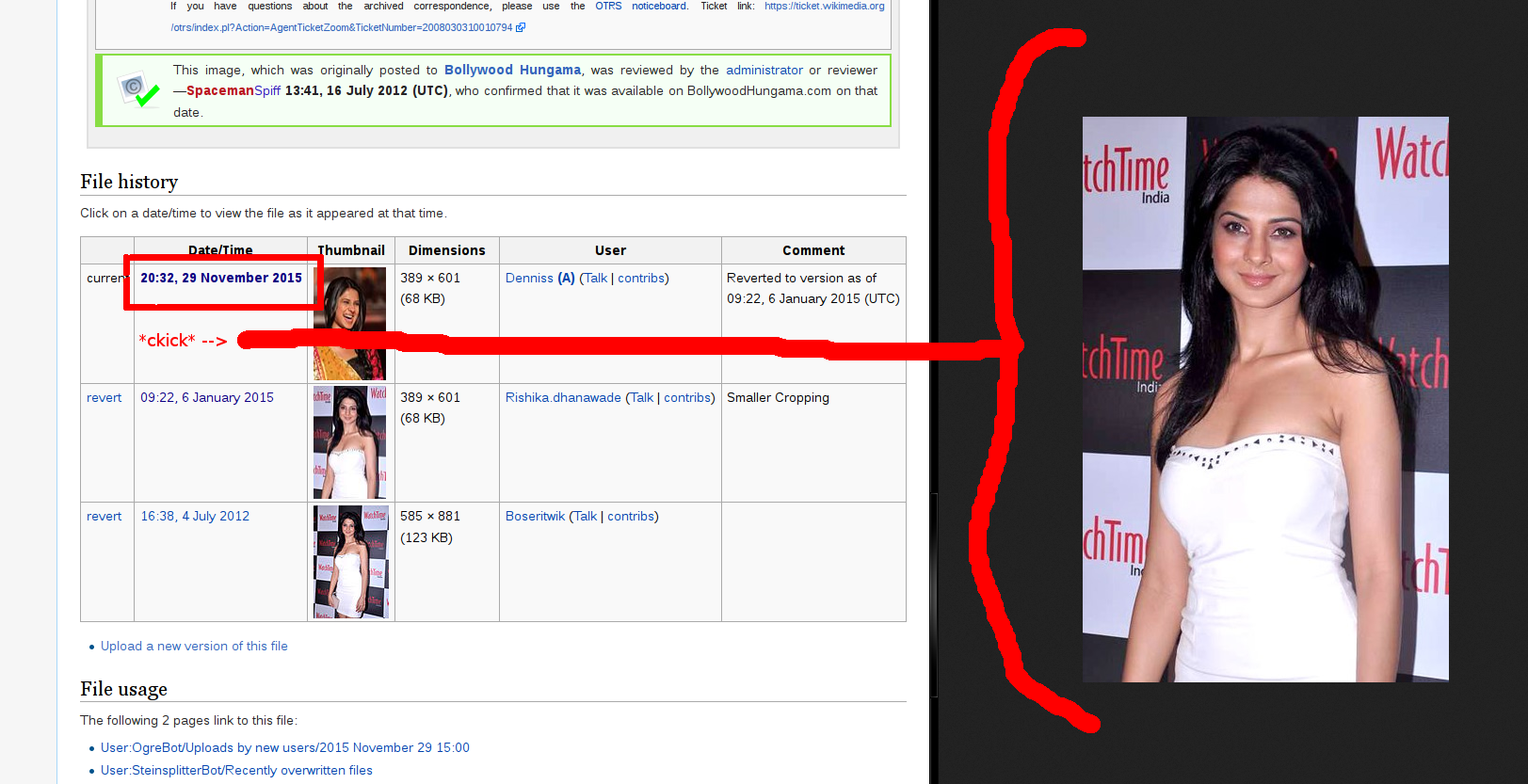
Recently i have seen that when you upload over a previous image, the changes don't seem to show up (for the picture atleast) [the resolution and size remain current], i thought it was an issue with my browser in the beginning but then i tried with 4 other browser on my PC and they all came looking the same as the previous image, The thumbnail on the file history may look updated or may not looked updated, it depends, here are two examples,
- I made a major change to this image (https://commons.wikimedia.org/wiki/File:Kim_Jong-Un_Photorealistic-Sketch.jpg) but it doesn't look changed at all, unless you look at the thumbnail below
- I tried this on another image, a higher resolution one and as previously, "ctrl +f5" multiple times but it still did not update to the "less pinkish" recent version (https://commons.wikimedia.org/wiki/File:Bernie_Sanders_September_2015.jpg)
An admin on commons told me he had issue like this as well and another user on IRC told me to change the pixels by 1 to get the "current" version" of the image...is this a known issue?..
I'm on FF43b1 on WinVista ..just in case..